本文使用python实现了线性回归和逻辑回归算法,并使用逻辑回归在实际的数据集上预测疝气病症病马的死亡率(当然这里我们的线性回归和逻辑回归实现是原生的算法,并没有考虑正则化系数问题,后期会将其补充完整)。
有关于线性回归的知识可以参考 NG机器学习总结-(三)线性回归 逻辑回归的只是可以参考 NG机器学习总结-(四)逻辑回归。
一、线性回归
1.模型表示
2.损失函数
3.梯度下降法求解
repeat until convergence {
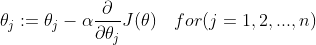
}
根据上式求解:
...
update
,
.,...,
simultaneously
In other words:
repeat until converagence:{
}
二、线性回归python代码实现
1.线性回归的一般过程
(1)收集数据:采用任意的方式采集获取到数据
(2)准备数据:比如数据的类型是否为数值型。一般结构化的数据最佳
(3)分析数据:对数据进行分析,特征数量、数据集大小、特征的选取等
(4)训练算法:通过算法找到最佳的特征参数
(5)测试算法:通过准备好的测试数据集来验证模型的准确性
2.python代码
在代码的实现过程中,我们只是简单的使用了两个特征参数(x1 和 x2)来写的,如果数据集有多个参数,需要修改,写个循环即可。(在以后具体的实例中,会将这一块补充完整。请稍安勿躁。重点是如何使用梯度下降算法求解的过程见gradAscent方法,并且还额外实现了改进的梯度下降算法。另外,这里面不再用具体的数值去测试算法,写测试数据太麻烦了。在逻辑回归的python实现中,我们用已有的测试数据来检查编写的程序是否有问题。测试用的数据到时候也会贴出来,方便大家使用。)
"""
@Time : 2018/8/24 20:07
@Author : xudong
@File :
@Contact : [email protected]
"""
from numpy import mat, shape, ones, random
#加载数据集
def loadDataSet(filePath):
dataMat = []; labelMat = [] #分别定义一个数据集list和标签list
fr = open(filePath) #打开文件输入流
for line in fr.readlines(): #处理输入数据
lineArr = line.strip().split() #按照空格分割每一行数据集 (x1 x2 x3 ...xn y)
# 将 1.0(x0) x1 x2...值append到定义好的数据集集list中 等同博客中的 数据集矩阵X
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2])) #数据集中的真实值 y 这里需要根据自己的数据集进行修改索引位置
return dataMat, labelMat
#梯度下降法求解
def gradAscent(dataMatIn, classLabels):
'''
:param dataMatIn:
:param classLabels:
:return: weights 特征参数(权重系数) theta的值
'''
dataMatrix = mat(dataMatIn); # 将读取完的数据集X转化成 矩阵X
labelMat = mat(classLabels).transpose() #转置 y
m,n = shape(dataMatrix) #m是数据集行数,n是特征的数量
alpha = 0.001 #学习速率
maxCycles = 500 #最大迭代次数
weights = ones((n, 1)) #初始化特征参数 theta的值
for k in range(maxCycles):
error = dataMatrix * weights - labelMat # h(x) - y的值
weights = weights - alpha * dataMatrix.transpose() * error # w =: w - a(h - y)x
return weights
#随机梯度下降算法
#一次只使用一个样本点来更新回归系数(特征参数)
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix)
alpha = 0.001
weights = ones(n)
for i in range(m):
error = dataMatrix[i] * weights - classLabels[i]
weights = weights - alpha * error * dataMatrix[i]
return weights
#改进的随机梯度下降算法
#随机选取样本点和调整学习速率来更新回归系数
#这个地方随机选取样本点的函数式有点问题,请会的帮忙改成一下
def stocGradAscent1(dataMatrix, classLabels, numiter = 150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numiter):
dataIndex = range(m)
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 #更新alpha
randIndex = int(random.uniform(0, len(dataIndex)))
error = sum(dataMatrix[randIndex] * weights) - classLabels[randIndex]
weights = weights - alpha * error * dataMatrix[randIndex]
del(dataMatrix[randIndex])
return weights
#main 函数
if __name__ == '__main__':
trainDataPath = "e:/trainSet.txt";
dataMat, labelMat = loadDataSet(trainDataPath)
weights = gradAscent(dataMat, labelMat)
(tips:在上述代码中,我们使用的迭代次数来代替收敛准则,你也可以修改收敛准则,当损失函数下降的值小于0.001或者更小即为收敛。)
三、逻辑回归
(等写完NG机器学习总结-(四)逻辑回归后再来补充 这里面的知识,下面只给出逻辑回归的代码实现,并在后续的更新中给出实例,另外逻辑回归和线性回归的实现代码其实差别不大,多的只是用一层sigmoid函数包装了线性回归的模型函数 h)
四、逻辑回归python代码实现
1.逻辑回归一般过程
(1)收集数据:采用任意的方式采集获取到数据
(2)准备数据:比如数据的类型是否为数值型。一般结构化的数据最佳
(3)分析数据:对数据进行分析,特征数量、数据集大小、特征的选取等
(4)训练算法:通过算法找到最佳的特征参数
(5)测试算法:通过准备好的测试数据集来验证模型的准确性
2.python代码实现
"""
@Time : 2018/8/24 20:07
@Author : xudong
@File : logistic.py
@Contact : [email protected]
"""
from numpy.ma import exp
from numpy import mat, shape, ones, random
#加载数据集
def loadDataSet(filePath):
dataMat = []; labelMat = [] #分别定义一个数据集list和标签list
fr = open(filePath) #打开文件输入流
for line in fr.readlines(): #处理输入数据
lineArr = line.strip().split() #按照空格分割每一行数据集 (x1 x2 x3 ...xn y)
# 将 1.0(x0) x1 x2...值append到定义好的数据集集list中 等同博客中的 数据集矩阵X
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2])) #数据集中的真实值 y这里需要根据自己的数据集修改索引位置
return dataMat, labelMat
#sigmoid函数
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))
#梯度下降法求解
def gradAscent(dataMatIn, classLabels):
'''
:param dataMatIn:
:param classLabels:
:return: weights 特征参数(权重系数) theta的值
'''
dataMatrix = mat(dataMatIn); # 将读取完的数据集X转化成 矩阵X
labelMat = mat(classLabels).transpose() #转置 y
m,n = shape(dataMatrix) #m是数据集行数,n是特征的数量
alpha = 0.001 #学习速率
maxCycles = 500 #最大迭代次数
weights = ones((n, 1)) #初始化特征参数 theta的值
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights)
error = (h - labelMat) # h(x) - y的值
weights = weights - alpha * dataMatrix.transpose() * error # w =: w - a(h - y)x
return weights
#随机梯度下降算法
#一次只使用一个样本点来更新回归系数(特征参数)
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix)
alpha = 0.001
weights = ones(n)
for i in range(m):
h = sigmoid(dataMatrix[i] * weights)
error = h - classLabels[i]
weights = weights - alpha * error * dataMatrix[i]
return weights
#改进的随机梯度下降算法
#随机选取样本点和调整学习速率来更新回归系数
#这个地方随机选取样本点的函数式有点问题,请会的帮忙改成一下
def stocGradAscent1(dataMatrix, classLabels, numiter = 150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numiter):
dataIndex = range(m)
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 #更新alpha
randIndex = int(random.uniform(0, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex] * weights)) #随机选择样本
error = h - classLabels[randIndex]
weights = weights - alpha * error * dataMatrix[randIndex]
del(dataMatrix[randIndex])
return weights
#main 函数
if __name__ == '__main__':
trainDataPath = "e:/trainSet.txt";
dataMat, labelMat = loadDataSet(trainDataPath)
weights = gradAscent(dataMat, labelMat)
print(weights)这里面给出trainSet的测试集,有一百条数据trainSet.txt,然后运行代码,打印出weights如下图。

五、实例从疝气病症预测病马的死亡率
本小将使用逻辑回归来预测患有疝气病马的存活问题(分类问题死亡或存活)。这里的数据包含了368个样本和28个特征。原本的数据来自于(UCI机器学习数据库)。数据集中有30%的值是缺失的。数据集中有缺失值是个非常棘手的问题,很多研究都致力于解决这个问题。这里不作过多研究,只给出一点简单的解决方法:
- 使用特征的均值来填补缺失值
- 使用特殊值来填补缺失值,如-1
- 忽略有缺失值的样本数据
- 使用相似样本的均值来填补缺失值
- 使用另外的机器学习算法预测缺失值
处理完数据,现在数据集中特征的数量只有20个,原本的数据集中类别标签有三种,分别是“存活”,“已经死亡”,“已经安乐死”,这里将两种死亡合并成一种,另外对于本数据集中所有的缺失值都设置为0,处理完的数据集可以在csdn上下载(其csdn上默认下载要一个分,想改为0的,发现改不了,想要数据集的直接发邮件留言)。本次使用的是随机梯度下降算法(程序中的stocGradAscent0方法)求解(另外这里的随机梯度可能和我们所说的那个随机梯度下降算法不一样,因为在程序中我们使用的当前样本的一条记录去更新迭代回归参数,而在程序中stocGradAscent1方法才是我们经常提到的随机梯度下降算法,随机选取样本来更新回归参数直到收敛),因为改进的随机梯度下降算法(stocGradAscent1)bug没调出来,没跑成功(如果有路过的把这个bug改好不妨留下解决方式,十分感谢,初学python有点不熟练)。其整个代码如下:
"""
@Time : 2018/8/24 20:07
@Author : xudong
@File : logistic.py
@Contact : [email protected]
"""
from numpy import *
#加载数据集
def loadDataSet(filePath):
dataMat = []; labelMat = [] #分别定义一个数据集list和标签list
fr = open(filePath) #打开文件输入流
for line in fr.readlines(): #处理输入数据
lineArr = line.strip().split('\t') #按照空格分割每一行数据集 (x1 x2 x3 ...xn y)
# 将 1.0(x0) x1 x2...值append到定义好的数据集集list中 等同博客中的 数据集矩阵X
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2])) #数据集中的真实值 y
return dataMat, labelMat
def loadDataSet2(filePath):
dataMat = []; labelMat = []
fr = open(filePath) #打开文件输入流
for line in fr.readlines(): #处理输入数据
lineArr = line.strip().split() #按照空格分割每一行数据集 (x1 x2 x3 ...xn y)
# 将 x1 x2...值append到定义好的数据集集list中 等同博客中的 数据集矩阵X
n = len(lineArr)
lineCur = []
for i in range(n-1):
lineCur.append(float(lineArr[i]))
dataMat.append(lineCur)
labelMat.append(float(lineArr[n-1])) #数据集中的真实值 y
return dataMat, labelMat
#sigmoid函数
def sigmoid(inX):
return 1.0/(1 + ma.exp(-inX))
#梯度下降法求解
def gradAscent(dataMatIn, classLabels):
'''
:param dataMatIn:
:param classLabels:
:return: weights 特征参数(权重系数) theta的值
'''
dataMatrix = mat(dataMatIn); # 将读取完的数据集X转化成 矩阵X
labelMat = mat(classLabels).transpose() #转置 y
m,n = shape(dataMatrix) #m是数据集行数,n是特征的数量
alpha = 0.001 #学习速率
maxCycles = 500 #最大迭代次数
weights = ones((n, 1)) #初始化特征参数 theta的值
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights)
error = (h - labelMat) # h(x) - y的值
weights = weights - alpha * dataMatrix.transpose() * error
#w =: w - a(h - y)x
return weights
#随机梯度下降算法
#一次只使用一个样本点来更新回归系数(特征参数)
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix)
alpha = 0.001
weights = ones(n)
for i in range(m):
h = sigmoid(dataMatrix[i] * weights)
error = classLabels[i] - h
weights = weights - alpha * error * dataMatrix[i]
return weights
#改进的随机梯度下降算法
#随机选取样本点和调整学习速率来更新回归系数
def stocGradAscent1(dataMatrix, classLabels, numiter = 150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numiter):
dataIndex = range(1, m)
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 #更新alpha
randIndex = int(random.uniform(0, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex] * weights)) #随机选择样本
error = classLabels[randIndex] - h
weights = weights - alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
#根据死亡的概率判断死亡
def classifyVector(intX, weights):
prob = sigmoid(sum(intX * weights))
if prob > 0.5 : return 1.0
else : return 0.0
#读取病马数据为矩阵,并利用stocAscent算法求解
def colicTest(trainFile, testFile):
frTrain = open(trainFile)
frTest = open(testFile)
trainingSet = []; trainingLabel = []
#读取训练集数据并保存为trainingSet
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = [] # n = len(currLine)
for i in range(21): #range(n)
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabel.append(float(currLine[21])) # currLine(n)
#开始算法训练
trainWeight = stocGradAscent0(array(trainingSet), trainingLabel)
errorCount = 0; numTestVec = 0.0
#读取测试集并保存为testSet
for line in frTest.readlines():
numTestVec += 1.0; #测试集的数量
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeight)) != int(currLine[21]):
errorCount += 1
#计算分类出错的错误率
errorRate = (float(errorCount) / numTestVec)
print("the error rate of this test is : %f" %errorRate)
return errorRate
#多次试验测试
def multiTest(trainFile, testFile):
numTests = 10; errorSum = 0.0
for k in range(numTests):
errorSum += colicTest(trainFile, testFile)
print("after %d iterations the average error rate is: %f" %(numTests, errorSum / float(numTests)))
#main 函数
if __name__ == '__main__':
trainFile = "f:/horseColicTraining.txt"
testFile = "f:/horseColicTest.txt"
multiTest(trainFile, testFile)运行的结果如下图:
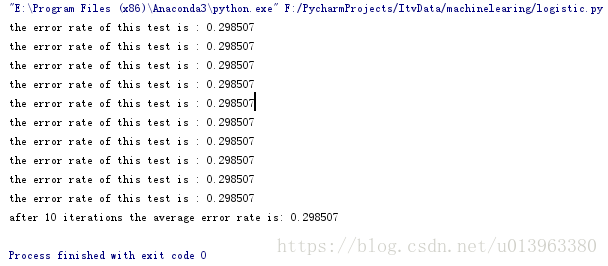
是的这里的十次运行结果是一样的,因为我们用的第二种梯度下降算法,所以结果是一样的。如果用改进的随机梯度下降算法会不一样的。