目标分割Dilated Convolutions讲解

原文:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
收录:ICLR 2016 (International Conference on Learning Representations)
代码:Dilated Convolutions code
ABSTRACT
卷积网络最初是为图像分类而设计的。然而,语义分割中像素点级别的密集预测问题在结构上与图像分类不同。在这项工作中,我们开发了一个新的卷积网络模块,它是专门为密集预测设计的。该模块在不丢失分辨率的情况下,扩展卷积系统,聚合多尺度的上下文信息。该网络结构基于这样一个事实,即空洞卷积可以在不减少分辨率或覆盖率情况下,支持感受野指数增长。
※论文核心思想:为了聚合多尺度的上下文信息;
- 提出新的卷积网络模块( 空洞卷积 )。通过空洞卷积达到多尺度上下文信息聚合的效果;
- 用改进了VGG-16网络作为 前端模块 ;
- 设计出 基础上下文模块 ,旨在通过聚合多尺度上下文信息来提高密集预测的性能。
1. INTRODUCTION
语义分割的目标是为图像中的每个像素计算一个离散或连续的标签,因此语义分割具有挑战性,因为它需要将像素级精度与多尺度上下文推理相结合。最近通过使用卷积网络(LeCun et al.,1989)和反向传播(Rumelhart et al.,1986)训练,语义分割获得了显著的准确性。FCN(2015)的研究表明,原本用于图像分类的卷积网络架构可以成功地用于稠密预测(图像分割)。
现代图像分类网络通过连续的池化和下采样层降低分辨率来整合多尺度上下文信息,直到获得全局预测。恰恰相反的是,图像分割不仅需要多尺度上下文信息,而且输出具有全分辨率。 (图像分类与分割在结构要求上不同,如何对分类网进行修改是一个问题)
过去解决上述问题的两个方法:
1. 之前的FCN中有两个关键技术,一个是池化来减少图像尺寸并增大感受野(为捕获上下文信息),另一个是上采样扩大图像尺寸。但是先减小后增大尺寸的过程中,肯定有一些信息损失掉了。对于这种方法,作者提出一个疑问:是否真的需要下采样层?
2. 另一个方法则是提供图像的多个重新缩放版本(multiple rescaled verions of the image)作为网络的输入,并将这些多个输入的预测结果结合起来。对于这种方法,作者同样提出一个疑问:对多个重新放缩的图像进行分开分析是否必要?
基于这些疑问,作者提出了一种新的卷积网络模块,它能够整合多尺度的上下文信息,同时不丧失分辨率与覆盖率,也不需要分析多个重新放缩的图像。这种模块是为稠密预测专门设计的,没有pooling或下采样。这个模块是基于空洞卷积,空洞卷积支持感受野指数级的增长,同时还不损失分辨率与覆盖率。 (提出新的卷积模块来解决上述问题)
2. DILATED CONVOLUTIONS
※空洞卷积初步了解:
使用卷积核大小为3×3、空洞率(dilated rate)为2、stride为1的空洞卷积对输入为7×7的特征图进行卷积生成3×3的特征图,示意图如下。
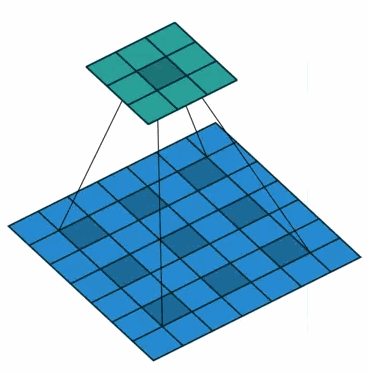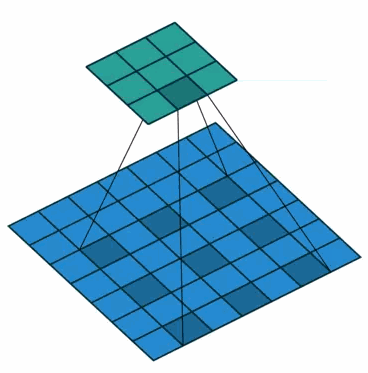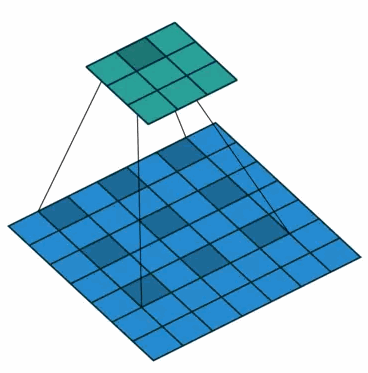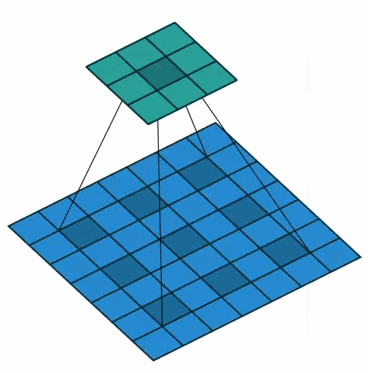
※为什么空洞卷积能够扩大感受野并且保持分辨率呢?
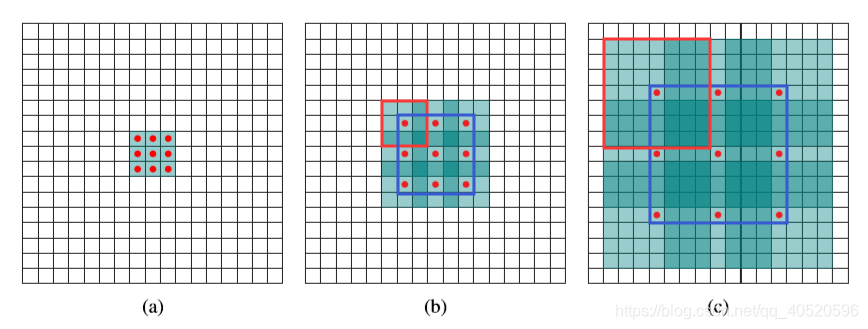
(a) 普通卷积,扩张率为1的3x3卷积,卷积核的感受野为3 = 22-1;
(b) 扩张卷积,扩张率为2的3x3卷积,卷积核的感受野为7 = 23-1;卷积核覆盖的区域大小为5x5(图中蓝框),但是这个时候感受野大小并不是5x5,因为(a)中的元素的感受野就已经为3x3了,覆盖的5x5区域要往外多加
=1个像素,如(b)中红框所示。即1-dilated和2-dilated堆叠起来就能达到7x7的感受野;
(c) 扩张卷积,扩张率为4的3x3卷积,卷积核的感受野为15 = 24-1;卷积核覆盖的(b)区域大小为9x9(图中蓝框),但是由于(b)中的元素的感受野大小为7x7,因此,在这个9x9的区域大小之外还要扩张出
=3个像素,如©中红框所示。即1-dilated、2-dilated、4-dilated堆叠起来就能达到15x15的感受野。
从上图中可以看出,卷积核的参数个数保持不变,但是感受野的大小随着“dilation rate”参数的增加呈指数增长,最重要的是,在这个过程中没有进行下采样。
3. MULTI-SCALE CONTEXT AGGREGATION
在这一部分中,作者提出了自己设计的一种基础上下文模块,上下文模块旨在通过聚合多尺度上下文信息来提高密集预测网络结构的性能。该模块采用C个通道特征图作为输入,并生成C个通道特征图作为输出。输入和输出具有相同的形式,因此该模块可以插入到现有的密集预测网络结构中。
本文设计的基本上下文模块有7层,每一层采用不同的扩张率的3×3×C卷积。扩张率分别是1、1、2、4、8、16和1。基础上下文模块根据卷积的通道不同又分为两种形式:basic和large
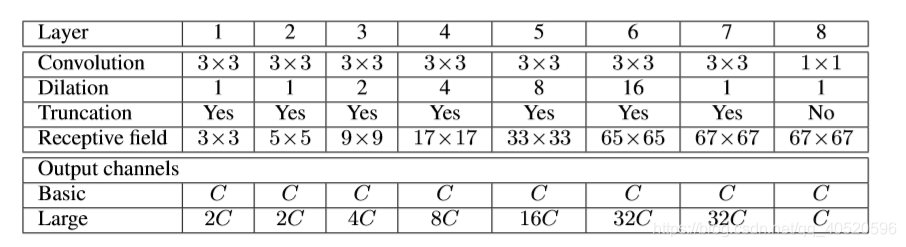
以上就完成了基本上下文网络的表示。我们的实验表明,即使是这个基本模块也能在定量和定性上提高稠密预测的精度。这一点特别值得注意,因为网络中的参数数量很少:总共有≈64C2 = (7×3×3+1×1)C2个参数。
优点:空洞卷积在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射(feature map)的大小保持不变。例如:一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为3×3=9个 < 25个。
4. Front End 前端
在第三部分中作者提到,上下文网络模块输入的是前端模块生成的64*64分辨率的特征图。接下来介绍什么是前端模块呢?
下图中fc-final之前的部分就是前端模块,之后的部分就是上下文模块。前端模块改进了VGG-16网络,将VGG-16最后两个poooling层移除,并且随后的卷积层被空洞卷积代替,pool4和pool5之间的空洞卷积的扩张率为2,在pool5之后的空洞卷积的扩张率为4。实际上,只需要前端而不需要前端之后的部分就能够进行稠密预测。
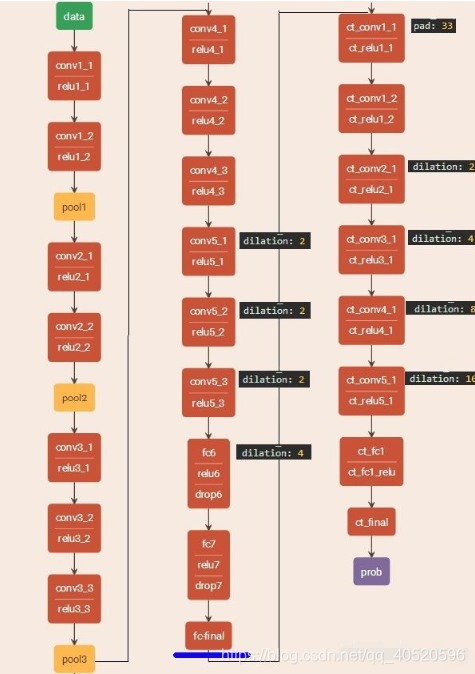
最后作者将前端模型在VOC-2012数据集上语义分割效果与FCN-8s,DeepLab,DeepLab-Msc方法的比较,如下图:

