参考资料:https://blog.csdn.net/zizi7/article/details/77369945
https://blog.csdn.net/Quincuntial/article/details/78743033
通过膨胀卷积操作聚合多尺度的信息
主要贡献:
- 使用膨胀卷积(扩张卷积)
- 提出 ’context module‘ ,用来聚合多尺度的信息
说明:
池化在分类网络中能够扩大感知域,同样降低了分辨率。所以作者提出了膨胀卷积层。
以FCN和SegNet 为代表的图像分割方法与传统的 CNN 一样,先对图像做卷积再做池化。其中池化的意义一方面是降低计算量,另一方面是增大感受野
因为图像分割的输出是一张图片,而不是一个特征向量,因此上面两种方法将池化后的图像做上采样(反卷积),使尺寸与输入一致。在减小到增大尺寸的过程中,很大一部分信息丢失掉了。
Dilated Convolutions【1】在conv5_1、conv5_2、conv5_3、fc6 从 ct_conv1_1 使用膨胀(空洞)卷积的方法实现了“去掉下采样操作的同时不降低网络的感受野”的效果。

1. 扩张卷积
Dilated Convolutions,翻译为扩张卷积或空洞卷积。扩张卷积与普通的卷积相比,除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野。感受野是卷积核在图像上看到的大小,例如3×3 卷积核的感受野大小为9。
2. 示意图
下图是扩张卷积的示意图。


感受野的计算公式:

图1以 dilation=2 为例介绍了如何做二维空洞卷积(先做0填充,然后卷积即可)

图2. 对3∗3的卷积核做0填充,实现空洞卷积(参考自这里)
网络结构
文章使用的网络为 VGG-16 + context model,图4为官方代码里 dilation8_pascal_voc_deploy.prototxt 的结构示意图(可视化工具)
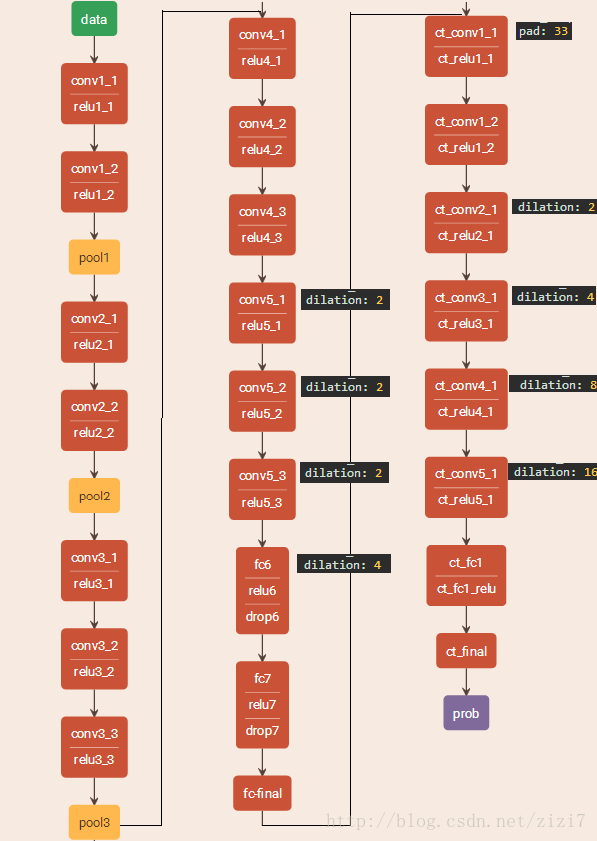
图3. VGG-16 + context model 的网络结构
可以看到,方法对 VGG16 的部分卷积层做了 空洞卷积改造:conv5_1、conv5_2、conv5_3、fc6
从 ct_conv1_1 开始为文章提出的 context model 网络。
3. 优点
扩展卷积在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射(feature map)的大小保持不变。一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为9个,是5×5卷积参数数量的36%。