论文全称:《MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS》
论文地址:https://arxiv.org/pdf/1511.07122v2.pdf
论文代码:
python TensorFlow版本 https://github.com/ndrplz/dilation-tensorflow
python Keras版本 https://github.com/DavideA/dilation-keras
lua torch版本 https://github.com/torch/nn/blob/master/doc/convolution.md#nn.SpatialDilatedConvolution
C++ caffe版本 https://github.com/fyu/caffe-dilation
论文综述
这篇论文提出了一种卷积的模块,从而可以聚合多尺度上下文信息而不丢失分辨率或分析已缩放的图像。该模块可以以任何分辨率插入到现有的体系结构中。该模块是基于空洞卷积的,它支持接受域的指数扩展,而不会丢失分辨率或覆盖率。
空洞卷积
dilated convolution算子在过去被称为“convolution with a dilated filter”。它在小波分解算法a trous中起着关键作用。这篇文章之所以称之为dilated convolution而不是convolution with a dilated filter 是因为论文里面没有使用任何“dilated filter”,而是对卷积算子本身进行了修改,以不同的方式使用滤波器参数。dilated convolution算子可以利用不同的膨胀因子在不同的范围内应用相同的滤波器。
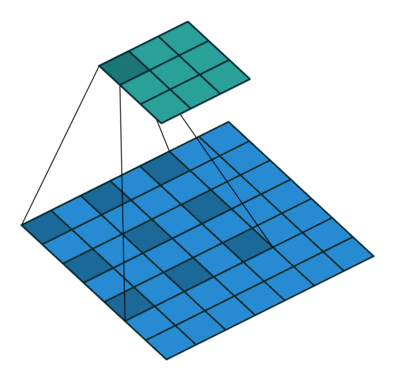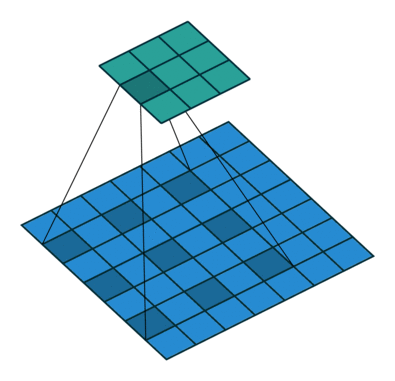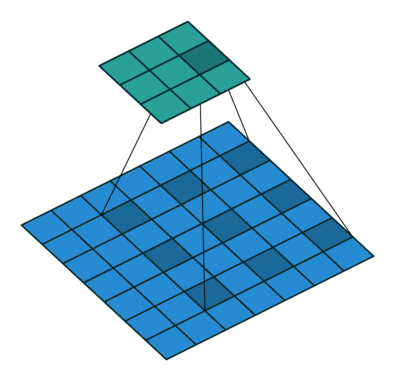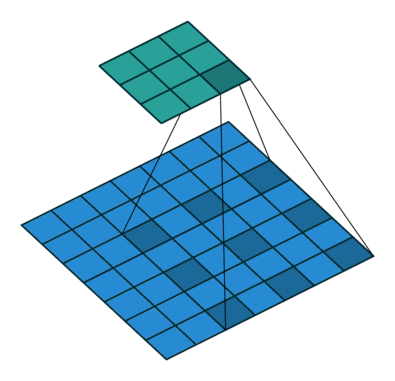
下面看一下dilated conv原始论文中的示意图:


(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中。
一个简单的例子,[动态图来源:vdumoulin/conv_arithmetic]: