Dilated Convolutions
目录
1 概述
本模型提出了一种新的卷积神经网络模块,主要是为了解决密集预测的问题。本模型采用了膨胀卷积,使感受野得到了指数级的拓展,而不损失覆盖率和分辨率。它可以聚集多尺度的背景信息,能应用在任何解决方案的框架当中。
现在主要有两种方法来解决多尺度推理和密集预测的问题,其中一种是不断地进行反向卷积,来恢复下采样过程当中所丢失的信息,另外一种是对输入的图像进行多尺度的变换。但是这同样引起了我们的质疑,下采样是必要的吗?对输入进行多尺度变换是必要的吗?
我们最终在PASCAL VOC 2012数据集上面进行了验证,把这种新的卷积神经网络模块加入到现有的语义分割架构之中,发现准确度有了明显的提升。
2 膨胀卷积操作

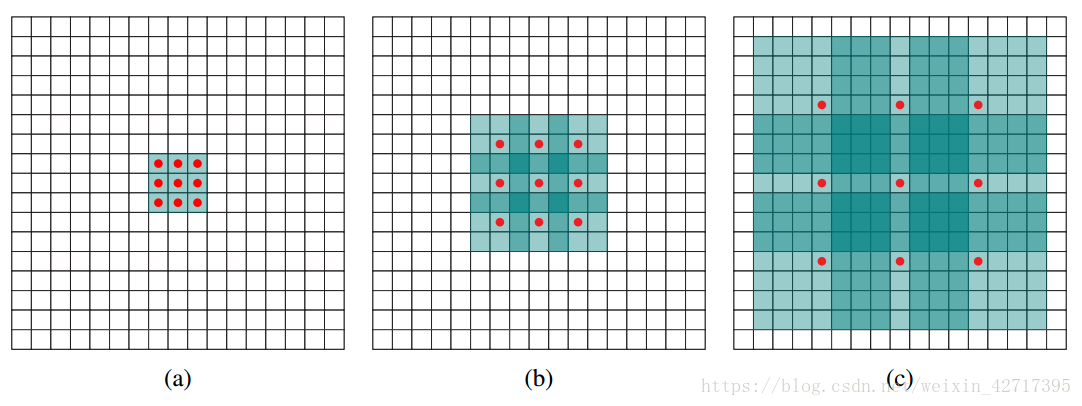
图2-1 膨胀卷积示意图

3 背景模型-多尺度聚集背景信息
背景模块通过收集多尺度的背景信息来提升架构密集预测的准确度。在基础背景模型中我们定义每层有C个通道,则卷积算子的维度为3*3*C。在此基础上进行了1,1,2,4,6,8,16倍的膨胀操作。模型结构如图3-1所示。最后的输出进行1*1的卷积,每一个卷积都会经过max(.,0)函数的截取操作。
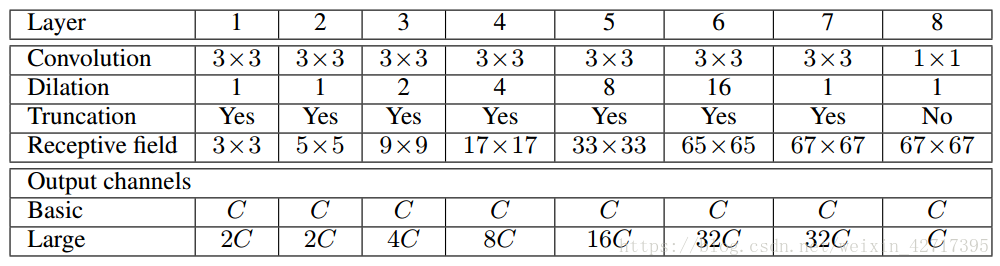
图3-1 模型结构示意图
在最初的尝试中我们并没有提高精确度,实验证明初始化步骤中出现了问题。卷积神经网络通常在随机分布里面采样来初始化,但是这样效果并不好。我们发现了一种更加高效的方法:
其中a是输入特征图的索引,b为输出特征图的索引。这使得每层简单的将输入传递给下一个,但并不会影响反向传播对信息的传输,同样可以提高精确度。这个基础背景模型同时提高了密集预测的质量和数量,但却有很小的参数量,约为64。
我们训练了一个大型背景模型,它在更深层使用更大特征图。和是连续的两个层,服从正态分布,是一个随机噪声,初始化操作为:

4 前端模型
我们训练了一个前端预测模型,把一张彩色图片作为输入,并把一个C=21的特征图作为输出。使用了VGG-16网络,去掉了所有的池化层,对所有池化层之后的特征层使用2倍的膨胀卷积操作。

图4-1 PASCAL VOC 2012训练集模型指标对比示意图
这个简化的模型在PASCAL VOC 2012训练集上面进行训练,训练是通过SGD(随机梯度下降)进行的,参数分别设置为:mini-batch=14,learning rate=10^-3,momentum=0.9,iterations=60K。
我们和FCN-8s和Deeplab进行对比,结果如上图所示,指标数据来自于VOC-2012。结果表明,我们的模型简单又准确,与其他两种方法相比,高出了5个百分点。
5 模型实验
我们的模型实现是基于Caffe框架的,膨胀卷积已经成为了标准Caffe的一部分。实验主要分两个部分进行,在第一阶段,同时在PASCAL VOC 2012和MS COCO数据集上面进行SGD训练,参数分别设置为:mini-batch=14,momentum=0.9。先以learning rate=10^-3进行100K次迭代,先以learning rate=10^-4进行40K次迭代。在第二阶段,只在PASCAL VOC 2012进行Fine-tuning,以learning rate=10^-5进行50K次迭代。从PASCAL VOC 2012验证集上所得到的图像不用于训练。
前端训练的模型,在VOC-2012验证集上面的mIoU达到了69.8%,在测试集上达到了71.3%。这个数据是由前端模块单独实现的,还没有添加背景模块和结构化预测模块。之后我们将Basic和large的背景模型都添加进前端模型。
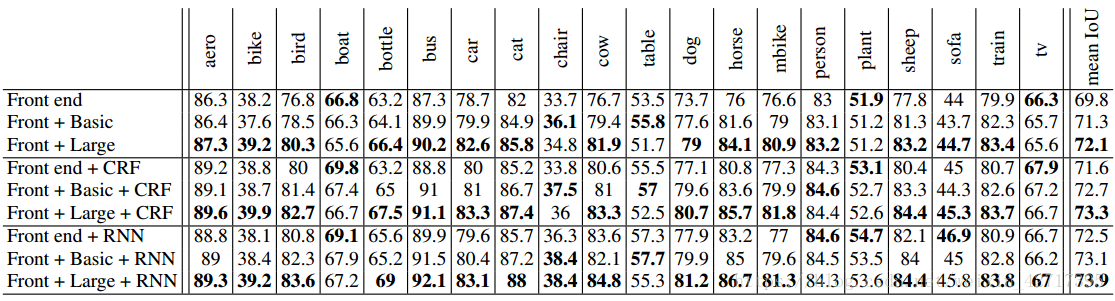
图4-2 VOC-2012验证集模型指标对比示意图
如图4-2所示,第一类中,并没有加入结构化预测。第二类中,采用了CRF来执行结构化预测,并通过在验证集上的网格预测来进行CRF的参数训练。第三类中,采用了CRF-RNN来进行结构化预测。
从实验结果可以看出来:
1)背景模型提升了准确率。
2)大型背景模型更大程度的提升了准确率。
3)背景模型和结构化预测可以协同工作。
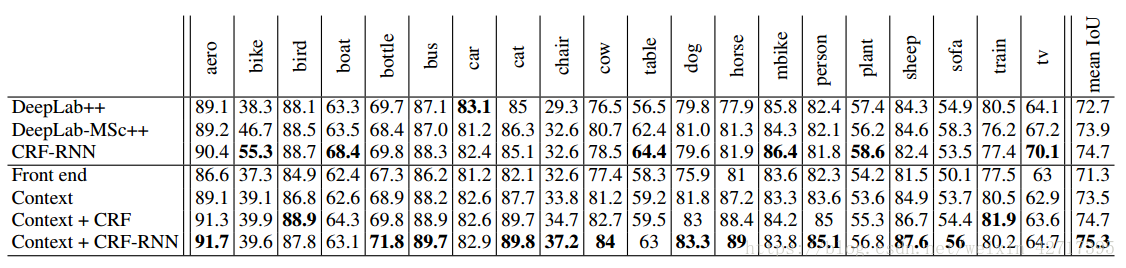
图4-3 VOC-2012测试集模型指标对比示意图
最后,我们将模型提交到VOC-2012测试集上面。从图4-3的结果可以看出来,大型背景模型在前端模块的基础上提升了准确率。没有使用结构化预测的背景模型,优于DeepLab-CRF-COCO-LargeFOV。背景模型联合CRF-RNN进一步提升了CRF-RNN的效果。
6 结论
- 膨胀卷积由于其扩大了感受野的大小,非常适用于密集预测。
- 设计了一种基于膨胀卷积的新型网络结构,当将之用于现有的语义分割系统时,可以很大程度上提高准确度。
- 附录中给出了模型在三个数据集上对城市场景的表现:CanVid、KITTI、Cityscapes,并给出了在训练过程中的参数配置,在github上发布了训练模型的代码。