目标分割DeepLab v2

原文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
收录:TPAMI 2017 (IEEE Transactions on Pattern Analysis and Machine Intelligence)
其中DeepLab 是由Google团队提出的,至今有四个版本(v1-v4)
ABSTRACT
回顾下Deeplab v1 ,其主要是在FCN 的基础上对VGG网络进行调参fine tuning,并在最后加上一个全连接的CRF,保证对FCN 得到的结果在局部细节(边界)上进行优化。
DeepLab v2 是在Deeplab v1 的基础上进行改进。改进点有三个,具体如下:
- Atrous Convolution 代替原来上采样的方法,比之前得到更高像素的score map,在不增加参数数量或计算量的情况下,有效地扩大感受野,以获得更多的上下文信息;
- ASPP(atrous spatial pyramid pooling) :基于空间空洞金字塔池化的多尺度分割方法,即多尺度特征提取,在多个尺度上捕获对象和图像特征和语境;
- 全连接的CRF,利用低层的细节信息对分类的局部特征(边缘)进行优化。
※论文核心思想:
- 提出空间空洞金字塔池化ASPP;
- 空洞卷积 Atrous Convolution;
- 全连接的条件随机场(CRF);
与DeepLab v1区别在于DeepLab v2使用ResNet和VGGNet进行实验,而DeepLab v1仅使用VGGNet,还有在于ASPP。
1. INTRODUCTION
图像语义分割三个 挑战 以及我们的 解决方案:
Q1:传统分类DCNNs中连续的池化和下采样将导致空间分辨率明显下降,不利于图像分割
A1:我们去掉最后几个最大池化层下采样,而在随后的卷积层中进行上采样,从而得到了采样率更高的特征图。
Q2:对象多尺度检测问题
常用方法:将不同尺度重新调节至尺度相同并聚合特征图或分数图,但计算量大大增加 ;
A2:对特征层重采样,得到多尺度的图像文本信息,使用具有不同采样率的多个并行的空洞卷积层来有效地实现多尺度采样,提出的技术称为ASPP。
Q3:以物体为中心的分类器,需要保证空间转换不变性 ,导致细节信息丢失
A3:使用跳跃层结构,从多个网络层中抽取高层次特征进行预测,并且使用全连接条件随机场增强捕捉精细细节能力,进行边界预测优化。扫描二维码关注公众号,回复: 9567911 查看本文章

DeepLab v2优点:
- 速度很快,DCNN 8fps,CRF需要0.5秒;
- 结构简单,DCNN和CRF的组合
2. METHODS
2.1. Atrous Convolution
问题:传统DCNN由于连续的最大池化和下采样导致分辨率严重下降,若使用FCN,但又会带来增加内存和计算时间的问题 。
1-D演示:

其中rate是膨胀因子,空洞卷积公式如下:
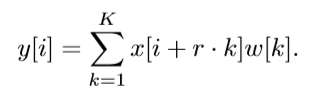
公式中的 y是输出信号,x是输入信号,w是卷积模板,K是滤波器长度,r则是输入信号的采样间隔。具体介绍在 DeepLab v1 中。
2-D演示:
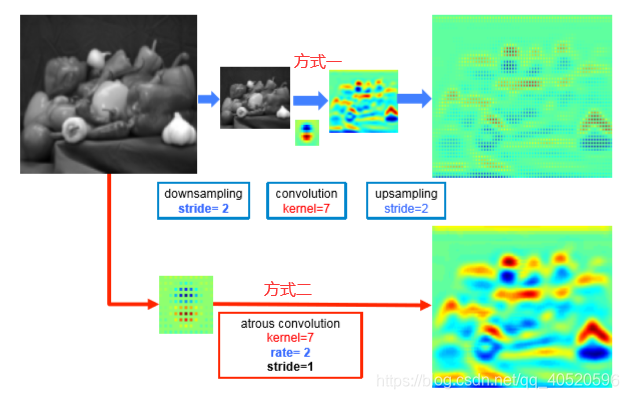
空洞卷积有两种实现方式:
方式一.:先下采样输入特征图,使得变为1/2,隔行去采样最后产生r2个子特征图,然后正常卷积,最后插值返回与输入大小相等的特征图。
方式二:先对卷积核上采样,将卷积核参数之间插入(r-1)个0。例如K大小的卷积核上采样之后大小为k+(k-1)(r-1) 。
2.2. ASPP
作者尝试了两种方案物体多尺度问题:
- 通过resize多尺度输入图片,最终结果取对象像素点位置最大的响应结果。
- 受spatial pyramid pooling(SPP)启发,得到ASPP结构。
具体结构如图所示:
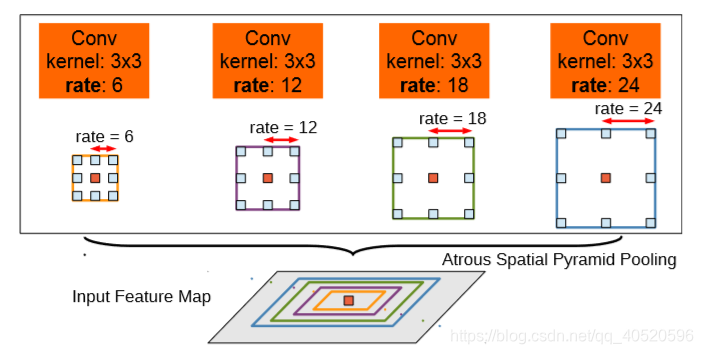
通过不同的rate构建不同感受野的卷积核,用来获取多尺度对象信息。
2.3. CRF
传统上,条件随机域(CRFs)已被用于平滑噪声分割图。通常,这些模型包含耦合相邻节点的能量项,有利于相同标签分配空间近端像素。定性的说,这些短程的CRF主要功能是清除在手工特征基础上建立的弱分类器的虚假预测。
由上图可知,得分图通常相当平滑并产生均匀分类结果,使用短程CRFs可能是有害的,因为我们的目标应该是恢复详细的局部结构,而不是进一步平滑它。使用对比敏感能量函数(Rother et al., 2004)结合局部范围的CRFs可以潜在地改善局部化。
为了克服短距离CRF的这些限制,我们将我们系统与Krahenbuhl&Koltun(2011)的完全连接的CRF模型相结合。该模型采用能量函数
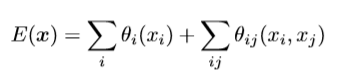
其中 x 是像素的分配标签,上面公式分为一元势能函数θi(xi)和二元势能函数θij(xi,yj)。
一元势能函数:
其中 为DCNN对像素 i 处分配的标签的概率
二元势能函数:刻画变量之间的相关性以及观测序列对其影响,实质是像素之间的相关性,对于图像中的任意一对像素 i 和 j ,无论它们之间的距离有多远,
即模型的因子图是完全连通的。
其中 (当 )
(当 ) 即Potts模型
是高斯核,取决于为像素 i 和 j 提取的特征(表示为 f ),并由 加权,由于采用位置和颜色组合,因此内核:
其中 p 表示像素位置, I 表示像素颜色强度,超参数σα,σβ,σγ控制高斯核的“尺度”。
