目标分割RefineNet讲解

原文:RefineNet
收录:CVPR 2017 (IEEE Conference on Computer Vision and Pattern Recognition)
代码:RefineNet-github
ABSTRACT
- 在深度CNNs中,重复的子采样操作(池化或卷积操作)会导致初始图像分辨率显著下降,为解决信息损失问题,我们提出RefineNet,充分利用下采样过程中可用的所有信息。 (本工作是U-Net的一个变种)
- 介绍链式残差池化(chained residual pooling ),可以高效的获取背景信息。
※论文核心思想:
- 提出新的网络结构RefineNet,是为了来 解决如何有效地利用中间层特性这个问题 ;
- RefineNet使用 恒等映射的短距离和远距离残差连接 ,这使得整个系统能够有效地进行端到端训练。
1. INTRODUCTION
Q1:多阶段的池化和卷积通常会使最终的图像预测降低32倍,从而丢失很多更精细的图像信息,有哪些解决方法以及这些方法弊端?
- 将反卷积作为上采样操作,但是缺点则是下采样毕竟舍去一部分信息,肯定无法准确恢复在下采样过程中丢失的低层次视觉特征。因为 低层次视觉信息对边框、细节的准确预测十分重要 ,所以没办法输出准确的高分辨率预测。
- 空洞卷积:没有下采样,而且在不增加参数个数前提下,获得更大的感受野。被成功应用于DeepLab,此时DeepLab代表了语义分割的最新进展,但弊端有两个:
1、它需要在高分辨率特征上计算卷积,而这些特征通常高维,计算量很大,而且在使用空洞卷积时,往往限制最后的输出尺寸为原始输入的1/8;
2、空洞卷积过程产生的粗糙特征可能也会丢失一部分重要细节。
- 利用中间层的特征生成高分辨率的预测结果:如FCN、Hypercolumns等,尽管中间层包含从早期卷积层编码低级空间视觉信息,如边缘;同时补充深层编码的高级语义信息如对象等。但是缺乏强空间信息。
所有层次特征都有助于语义分割。高层次的语义特征有助于图像区域的类别识别,而低层次的视觉特征有助于生成清晰、详细的边界,用于高分辨率预测。
Q2:如何有效地利用中间层特性?
为此,我们提出了一种新颖的网络架构,它有效地利用多级特性来生成高分辨率预测。我们的主要贡献如下:
1、一种多路径的提炼网络,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨率(粗粒度)语义特征和细粒度低级语义特征,生成高分辨率的特征;
2、级联的refineNet可以end-to-end训练,因为RefineNet的所有组件均采用恒等映射的残差连接residual connection,使得梯度可以通过短距离和长距离的残差连接传播,从而实现端到端训练;
3、提出链式残差池化,能够从大的图像区域提取背景上下文。
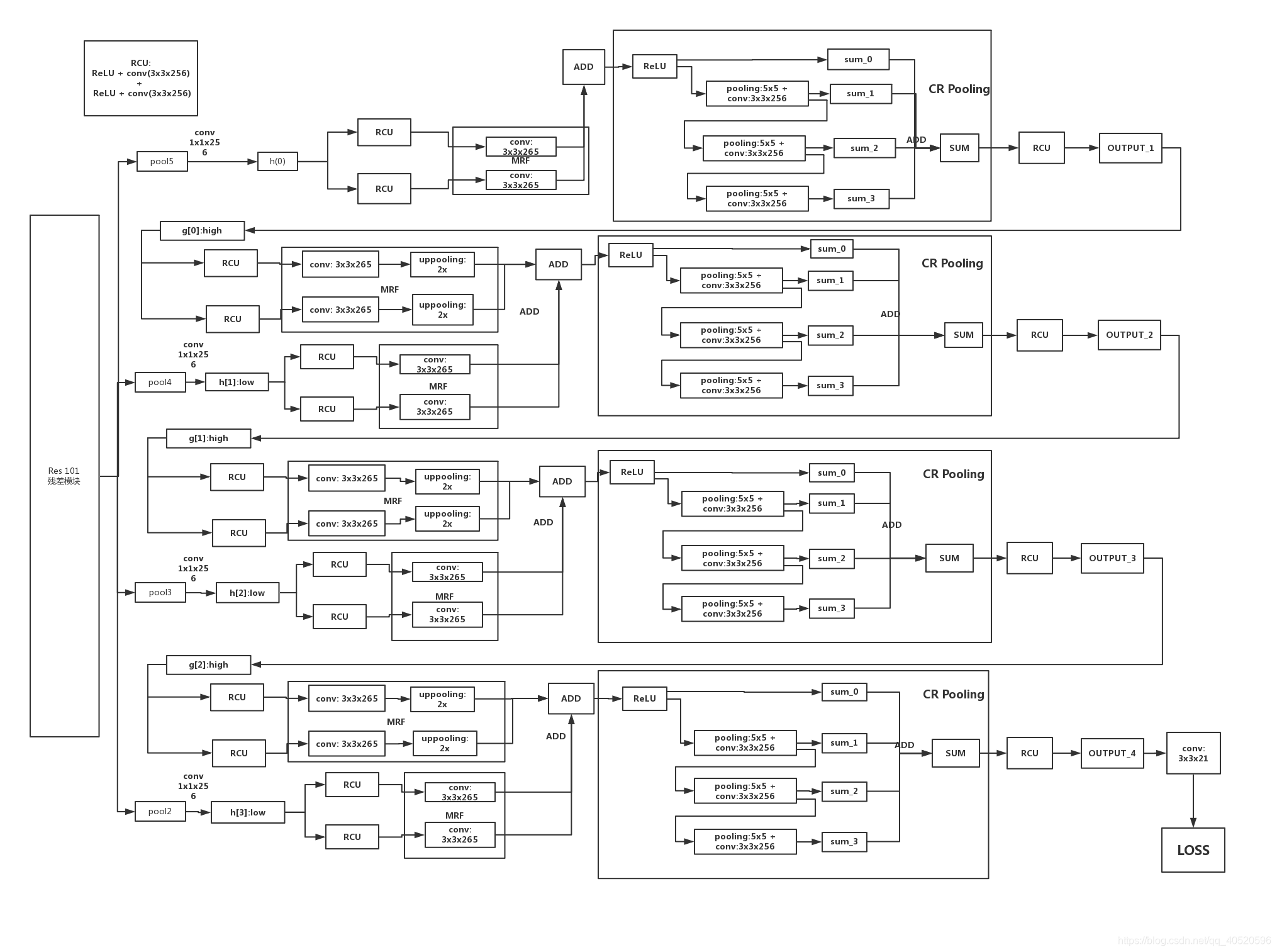
2. STRUCTURE
本文网络向下的路径以ResNet为基础,向上的路径则是使用新提出的RefineNet作为基础,并作为本路径特征与ResNet中低层特征的融合器。一个基本的框架如下图所示: 其中左边的四组特征图是从ResNet的四个对应的block输出。此框架与U-Net没有太大区别。不过RefineNet是一个灵活的模块,其输入的尺度个数可以变化,因此整个网络的拓扑结构可以有很多改变。
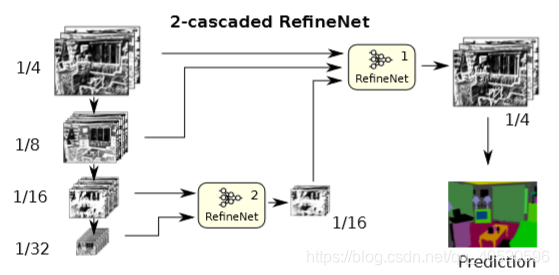
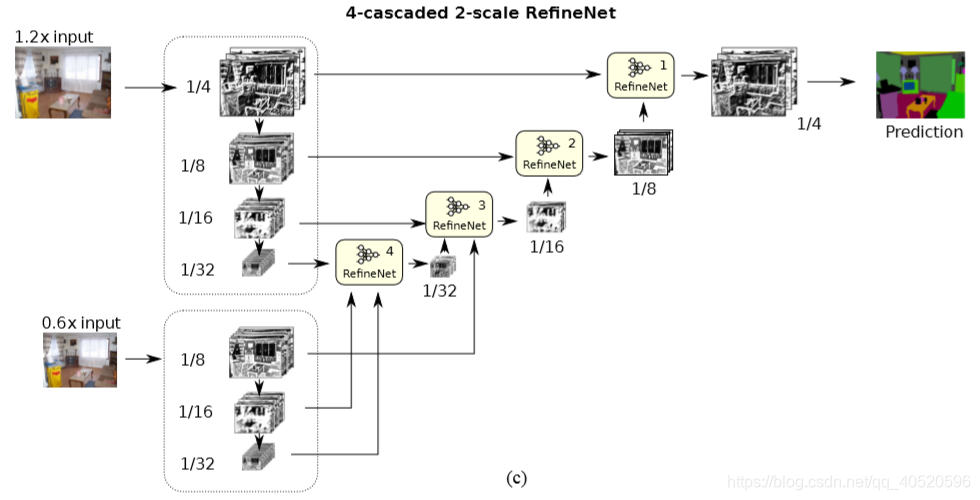
RefineNet利用多层次特征以及长距离残差连接生成高分辨率预测结果。如上图所示, 将预训练的ResNet分成四部分。根据特征图的采样率,用4个RefineNet单元构成4级联结构。将一个ResNet模块的输出以及级联结构中的上一个RefineNet模块作为当前RefineNet模块的输入 。
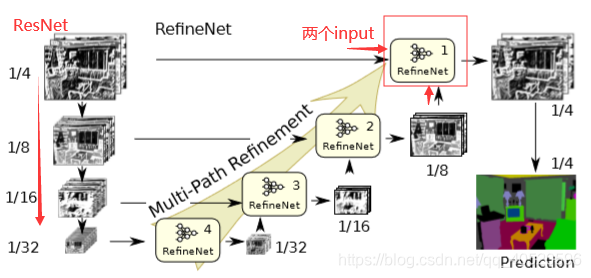
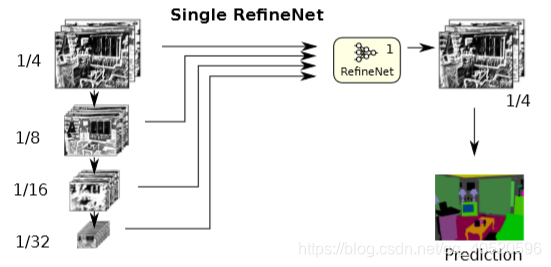
但是上图这样的结构并不唯一,可以对其进行扩展。例如:
① 仅使用一个RefineNet模块:
② 使用两个RefineNet模块级联:
③ 四个RefineNer模块四级联且使用两种尺度的输入:
3. RefineNet
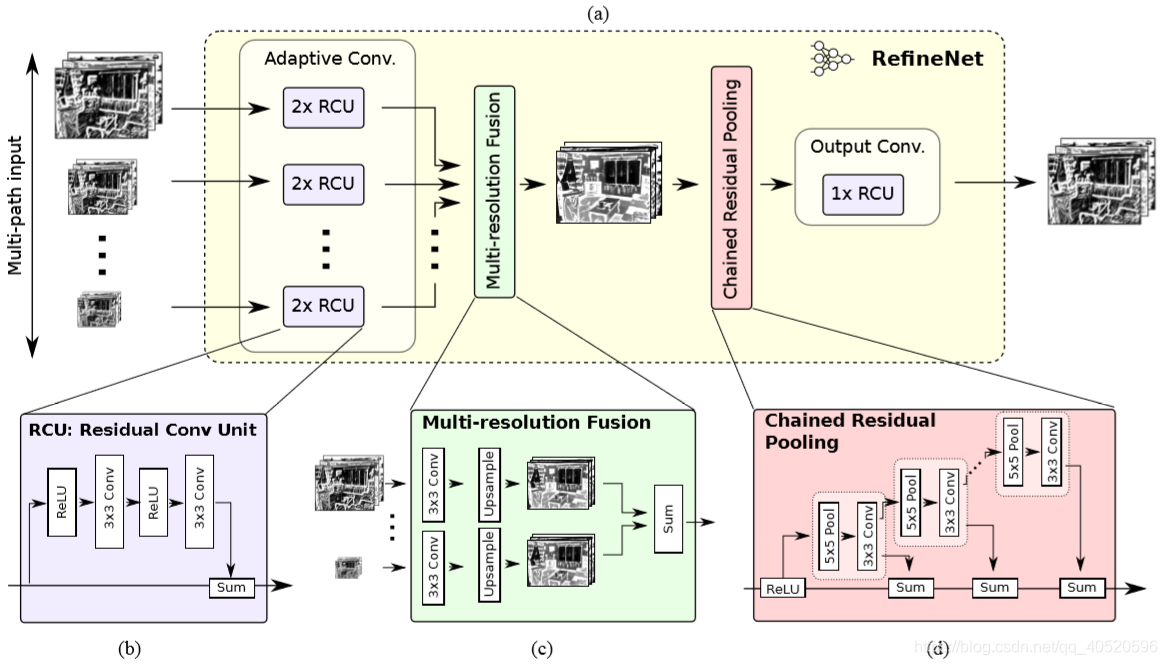
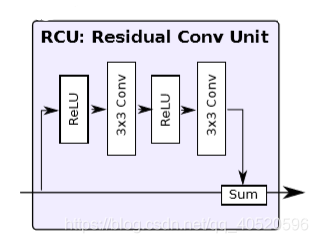
3.1. Residual convolution unit (RCU)
RCU(Residual convolution unit)是原始ResNet中卷积单元的简化版本(去掉了批处理规范化层batch-normalization layers),RCU模型的作用是对预训练的ResNet的权重进行微调,每一个输入经过连续两个RCU模块。除RefineNet 4中为512个卷积核外,其余所有输入路径上的卷积核个数均为256。
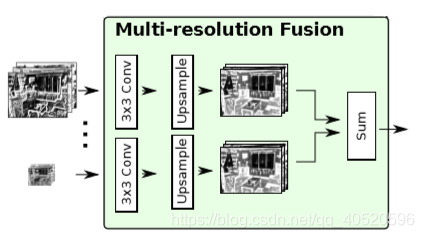
3.2. Multi-resolutionfusion
作用是将所有路径上的输入通过这个模块融合到高分辨率特征图上。对输入的特征图做适当的卷积然后产生同样维度的特征映射。所有特征上采样至最大的输入尺寸,然后对所有通道的结果求和(若只有一个输入路径,例如RefineNet-4,则输入路径将直接经过此块而不做任何更改)。
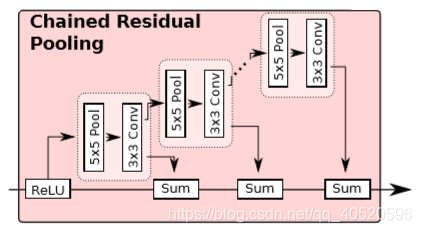
3.3. Chained residual pooling
链式残差池化的目的是为了针对大的图像区域捕获其上下文背景信息。它能够通过多种窗口大小进行有效池化并通过可学习的权重整合。模块主要包含残差结构、池化层、卷积层。池化卷积的目的是学习用来矫正的残差。这里值得注意的一点是,前一级的残差结果作为下一级的残差学习模块的输入,而不是直接从矫正过后的分割结果中再学习一个残差。之后再经过一个RCU模块,平衡所有权重,最后得到与输入分辨率一致的分割结果。
3.4. Output convolutions
即一个RCUs构成。
最后附上网络详细网络: