不会再写基础的东西。因为已经是第六篇论文了。
right@:
| arXiv:1511.07122 [cs.CV] |
Published as a conference paper at ICLR 2016
Introduction
我现在很喜欢读introduction以及literature review,因为很多观点都是总结。比如这篇文章认为传统的conv+pooling的结构用于图片分类效果很好,现在人们想要做dense prediction,逐像素标注,也就是不止知道这个图片是一只鸟还要知道,它在哪,轮廓。不止知道这是卧室还要知道哪些像素是床,哪些是窗户。
由于图片分类识别率很高,于是人们想要把conv+pooling改的可以完成dense pred任务。那么什么结构应该保留,什么结构不需要。什么结构有什么作用,就是个open question。
作者认为,pooling是为了扩大感受野,但是会造成模糊,毕竟上采样,对于逐像素标注不是很友好。这里插一句,很多网络都为了解决这个模糊现象。比如deeplab+CRF,比如直接把超像素块扔到网络里保护边缘信息,比如deconv,segnet。还有专门将RGB与D通道分开处理,最后将multy scale特征图结合的,主要是multy scale的特征图的应用汇带来更精确地pred效果。以及一手local信息,一手global的,不让他们混了。都是从classify向dense pred跑的过程。感觉introduction不白看。私以为,pooling的作用不仅仅是为了全局,而且还是应对旋转,平移。我认为论文中的方法不能很好的应对平移旋转。
好了,那么问题来了,我怎么既要全局,局部还不模糊。
作者用了如下方法。分辨率的确不会下降,但是能否保持住局部信息,这个我质疑。
The presented module uses dilated convolutions to systematically aggregate multis-cale contextual information without losing resolution. The architecture is based on the fact that dilated convolutions support exponential expansion of the receptive field without loss of resolution or coverage.
网络两个创新点:
1 exponential dilated convolution
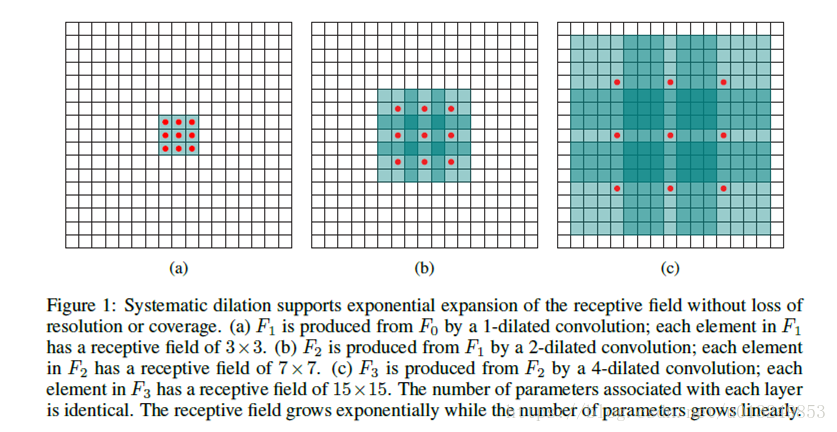
 很直观的gif动图
很直观的gif动图这两张图足以说明什么叫dilated卷积。而且步长为1,但是卷积核大小可以是指数级增长的。a卷积核只有3*3,b有5*5,c就是10*10了,卷积核除了三个红点处有数值,其他位置肯定是零。
2.multy-scale context aggregation
- c个通道的feature map进,c个通道输出
- 所以可以安插在任何其他网络里
- 作用是收集多层次上下文信息,从而提高准确率
- 实质上是pointwise truncation max(.,0)感觉像是relu啊,这。。?
网络结构如下,一共两种设计,basic比较浅,feature map通道也比较少,Large版本的结构通道比较多:
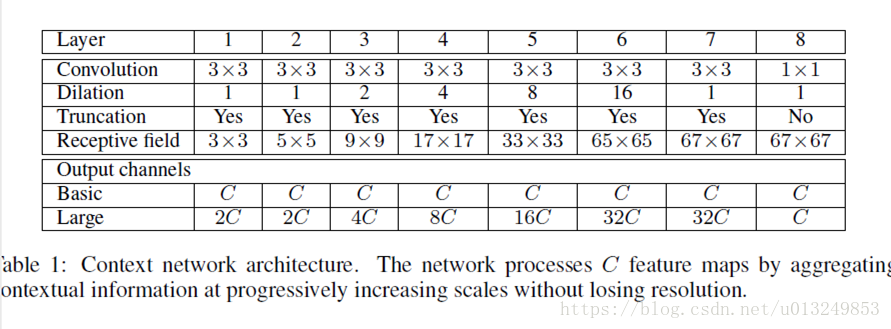
作者觉得初始化会影响最终结果,所以针对basic和large两个网络设计了两种初始化的网络参数:
basic:

large:

。第一个创新点早在deeplab就用过,full conv就提到过但是没用。而multi-scale 更像是relu,最后也没有综合起来,依旧是零散在每层中间,和现在的multi-scale不一样。
总结,恕我才疏学浅,没看懂新的是什么显层次理解就是hole+relu。