目标分割PSPNet讲解

原文:PSPNet
收录:CVPR 2017 (IEEE Conference on Computer Vision and Pattern Recognition)
代码:PSPNet-github
ABSTRACT
- 在本文中,我们通过金字塔池化模块( pyramid pooling module)和金字塔场景解析网络(PSPNet) 聚合基于不同区域的上下文信息,来提高获取全局上下文信息的能力 ;
- 我们的 全局先验表示在场景解析任务上有很好的效果 ,同时 PSPNet则为像素级的预测提供了优越的的框架 ;
- 该方法在不同的数据集上实现最先进的性能。其中2016年ImageNet场景解析挑战赛、PASCAL VOC 2012基准测试和Cityscapes基准测试都是 第一名 。
※论文核心思想:场景解析基于图像分割来实现:
- 为提高获取全局上下文信息,通过 金字塔池化模块 和 PSPNet 来聚合基于不同区域的上下文信息;
- 全局先验表示在场景解析任务上有很好的效果。
1. INTRODUCTION
基于语义分割的场景解析是计算机视觉的一个基本课题。场景解析提供了对场景的完整理解。它可以预测每个元素的标签、位置和形状。该技术在自动驾驶、机器人传感等领域有着广泛的应用前景。
场景解析的难度与场景和标签的多样性密切相关。
目前最先进的场景解析框架大多基于全卷积网络(FCN),但也存在许多短板,之后会详细分析。
主要贡献:
- 我们基于FCN的像素预测框架,提出了一种金字塔场景解析网络;
- 我们基于深度监督的loss,为深层ResNet开发了一种有效的优化策略;
- 我们为最先进的场景解析和语义分割构建一个实用的系统,其中包含了所有关键的实现细节。
2. Related Work
在深度神经网络的驱动下,场景解析和语义分割等像素级预测任务在卷积层代替全连接层分类的启发下取得了很大的进展,为了扩大网络的感受野,有些人使用空洞卷积、带有反卷积的coarse-to-fine等方法。基于先前的工作,我们选择的baseline是FCN和Dilated Convolutions。
大多数语义分割模型的工作基于两个方面:
多尺度特征融合:由于在深层网络中,高层特征包含了更多的语义和较少的位置信息。结合多尺度特征可以提高性能;
基于结构预测:例如先前方法使用CRF(条件随机场)处理,对分割结果进行细化。
Liu 等人证明使用FCN的全局平均池可以改善语义分割结果,然而,我们的实验表明,这些全局符对于具有挑战性的ADE20K数据并没有足够的有效,因此,没有使用全局池化,我们通过不同的基于区域的上下文聚合,通过金字塔式的场景解析网络来提高获取全局上下文信息的能力。
3. Pyramid Scene Parsing Network
3.1. Important Observations

通过分析FCN baseline的预测结果,我们总结了复杂场景解析中容易出现的几个常见问题:
- Mismatched Relationship:上下文关系对理解复杂场景普遍十分重要, 某种物体的出现具有一些固定的视觉模式 。例如,飞机很可能出现在跑道上或者在空中飞行,而不可能在道路上。例如上图的第一行,FCN根据外观将黄色方框中的“船”预测成为“车”。但河水上基本不会出现车。缺乏收集上下文信息的能力增加了错误分类的可能性。
- Confusion Categories:ADE20K数据集中 有许多对种类label十分难以区分 。例如field和earth、mountain和hill、wall, house, building和skyscraper。这几对物体的外表非常相似。在上图的第二排,FCN将框中的对象一部分预测为skyscraper,一部分预测成building。我们并不期望出现这种情况,整个对象应该是摩天大楼或建筑,但不应该是两者各有一点。此问题可以通过利用类别之间的关系来解决。
- Inconspicuous Classes:场景中包含任意大小的对象, 一些小尺寸的,例如街灯和广告牌往往很难找到,但它们可能非常重要 。与之相反,大尺寸的物品可能会超过FCN的感受野,从而导致不连续的预测。如上图第三行所示,枕头的外观与床单相似。不考虑全局场景中的类别的话可能会无法解析枕头。为了提高对于非常小或大的物体的性能,我们应该更加注意包含不显著类别的东西的不同子区域。
综上所述,许多错误 部分或全部与上下文关系和不同感受野的全局信息相关。因此,具有合适全局场景级先验(金字塔池化模块)的深度网络可以大大提高场景解析的性能。
3.2. Pyramid Pooling Module
通过以上分析,金字塔池模块在经验上证明了有效的全局上下文先验。
在深度神经网络中, 感受野的大小可以大致表示使用上下文信息的程度 。尽管理论上ResNet的感受野已经比输入图像还大,但CNN的实际感受野远小于理论场,尤其是在高层上,这使得 网络许多部分没有充分获得重要的全局先验知识 。
为了解决上述问题,我们提出有效的全局先验表示。
※全局平均池化:
-
全局平均池化是一个很好的全局上下文先验,是图像分类任务中常用的一种先验,Parsenet将它成功应用到了语义分割中。
(Parsenet将全局平均池化应用到语义分割上来) -
但对于ADE20K中复杂场景图像,这种方式不足以涵盖必要的信息。这些场景图像中有许多种类的对象。全局平均池化会直接将其融合形成一个单一的矢量可能会使其失去空间相关性,造成模糊。 (全局平均池化会造成模糊)
-
全局上下文和子区域的上下文都有助于区分不同类别。一个更强大的表达应该是能将不同子区域的上下文信息与感受野融合起来。 (全局上下文和子区域的上下文都有助于区分不同类别)
※金字塔池化:
在SPPNet里,最后将金字塔池化生成的不同层次的特征图进行平铺拼接,送入全连通层进行分类,该全局先验(金字塔池化)是为了去除CNN图像分类的固定大小约束而设计的。
※金字塔池化模块:

为了进一步减少不同子区域间上下文信息的丢失,我们提出了一个有层次的全局先验结构(金字塔池化模块),包含不同尺度、不同子区域间的信息。 (我们的金字塔池化模块是一个四层结构,bin大小为1×1、2×2、3×3和6×6)
金字塔池化模块融合四种不同金字塔尺度的特征:
- 红色突出显示的是最粗糙级别的单个全局池化bin输出;
- 下面金字塔分支将特征映射划分为不同的子区域,并形成针对不同位置的集合表示,金字塔池模块中不同层次的输出包含不同大小的feature map;
- 为了维护全局特性的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值直接对低维特征图进行上采样,最后,将不同级别的特征concate起来,作为最终的金字塔池化全局特性。
PSPNet网络结构详解:
- 输入图像后,使用预训练带空洞卷积的ResNet来提取特征图。最终的特征映射大小是输入图像的1/8,如上图(b)所示。
- 在生成特征图后,我们使用上图©中的金字塔池化模块来收集上下文信息。使用4层金字塔结构,池化内核覆盖了图像的全部、一半和小部分。它们被融合为全局先验信息。
- 在( c )的最后部分上采样,然后将之前的金字塔特征映射与原始特征映射合并起来,再进行卷积,生成(d)中的最终预测图。
4. Deep Supervision for ResNet-Based FCN
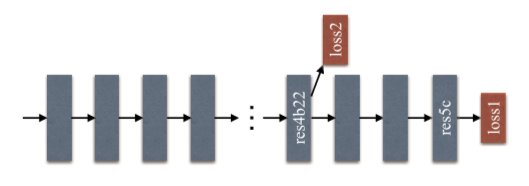
- 在ResNet101的基础上做了改进,除了使用Softmax loss来训练最终分类器的的主分支外,额外的在第四阶段添加了一个辅助的loss;
- 在第四阶段后再使用另一个分类器,即res4b22残差块
- 两个loss同时传播,辅助loss有助于优化学习过程,主loss仍是主要的优化方向,然后使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
