原文:GCN
收录:CVPR 2017 (IEEE Conference on Computer Vision and Pattern Recognition)
代码:GCN-github
ABSTRACT
- 在如今网络架构设计中,在相同的计算复杂度下,往往是使用小卷积核堆叠(例如1x1、3x3)来模拟大卷积核,因为堆叠小卷积核比大卷积核更有效;
- 但是在语义分割领域,我们需要密集的逐像素预测,我们发现此时大卷积核(和有效的感受野)起着重要的作用,因此为解决分类和定位问题,提出了 Global Convolutional Network;
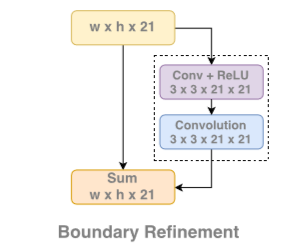
- 使用一个基于残差的边界细化(residual-based boundary refinement)来处理对象边界。
1. INTRODUCTION
图像分割包含两部分内容,即 定位、分类,由于这两部分互相矛盾,因此能够完美处理这两者之间关系的模型才是好的模型。
Q1:分类与定位矛盾体现在何处,该如何解决?
① 矛盾之处:
分类:分类模型应该对变换不敏感(例如:移动、旋转、缩放),模型需要具有平移不变性;
定位:定位模型对变换很敏感的,若模型具有非常好的平移不变性,那就很难以确定物体的具体空间位置,精度会很低。
(定位需要对物体的每个像素都判断其语义信息,并根据语义信息来找到位置)
② 解决方法:
分类:卷积kernel尽可能大,以实现特征映射和逐像素分类器之间的密集连接,若卷积核和特征图一样大(全局卷积),那就能利用全局信息;
定位:是全卷积网络,不能包含FC层和全局池化层,全局池化将会导致位置信息的丢失。

如上图所示,对网络A、B、C进行分析:
- 在分类网络A中,所有特征都输入给一个分类器,由分类器来判断物体的种类;
- 在传统分割网络B中,逐像素的分类结果由位置以及相对应的特征图来确定,发现特征图与分类结果之间是稀疏连接的,
- 文章所提出的网络C,则是实现特征图与每个分类结果之间的密集连接,使每一个像素的分类结果都能利用全局信息。
2. Related Work
首先回顾下之前网络的一些工作:
上下文嵌入:Dilated-Net 通过空洞卷积达到多尺度上下文信息聚合的效果,DeeplabV2使用空间金字塔池化(卷积的组合),直接从feature map嵌入上下文。
分辨率增加:FCN 首先提出了反卷积来提高小分数图的分辨率。此外,DeconvNet和SegNet引入了反池化(即池化的逆)和一个类似玻璃的网络来学习上采样过程。最近,LRR[12]认为对特征图进行上采样比得分图(score map)更好。Deeplab 和 Dilated-Net 并没有上采样过程,而是提出了一种特殊的空洞卷积,可以直接增大feature map,从而得到更大的score map。
边界对齐:条件随机域(CRF)因其良好的数学形式而常被采用。Deeplab 直接采用denseCRF作为CNN之后的后处理方法,这是一种构建在全连通图上的CRF变体。
3. Global Convolutional Network

Q1:GCN为什么要使用非常大的卷积kernel?
由于分类器是局部连接而不是全局连接到feature map,所以分类器很难处理输入的不同变化,如上图所示,器与输入对象的中心对齐,因此它被期望为对象提供语义标签,最开始 A 中VRF(有效感受野)能完全包含整个目标,但是到了 B 发现图像经过放大之后,VRF只能包含一小部分,这个只会更不利于分类;但在 B 里使用GCN则可以使感受野扩大成 C 那样,几乎覆盖了全图像。因此GCN一定要有非常大的卷积核,最好能够覆盖整个特征图。
Q2:GCN使用大的卷积核会造成参数量剧增,怎么处理?
我们之前也知道将大卷积核用多个小卷积核来取代是为了减少计算量,使用小卷积核堆叠就是为了在同样理论感受野的前提下减少了参数,增加了非线性,但显然把3x3再换回5x5,7x7甚至更大,计算量也会同样指数级扩大,而且过多的参数也会使网络难以收敛。
因此论文把一个大的k × k的卷积核分解为两个1 × k与k × 1,并且中间不使用ReLU等激活函数,且我们的计算复杂度和参数个数仅仅为O(2/k)。

Boundary Refinement 基于残差的边界细化 (BR) :作用则是增加边界的效果,模块的结构也非常简单,就是一个基础的残差模块。