k近邻(k-nearest neighbor,K-NN)
- 1968年提出了最初的邻近算法
- 是一种基于分类和回归的算法
- 基于实例的学习、懒惰学习
算法思想:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个邻居的信息来预测。
通常,在分类任务中,可使用“投票法”,即选择这k个样本中出现最多的类标标记作为预测结果;
在回归任务中,可使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果。
算法主要影响因素:(1)算法超参数 K;(2)模型向量空间的距离度量。
分类算法步骤:
- 为了判断未知实例的类别,以所有已知类别的实例作为参照;
- 选择参数K;
- 计算未知实例与所有已知实例的距离;
- 选择最近的K个已知实例;
- 根据少数服从多数的投票原则,让未知实例归类为K个最近邻实例中最多数的类别;
实例:
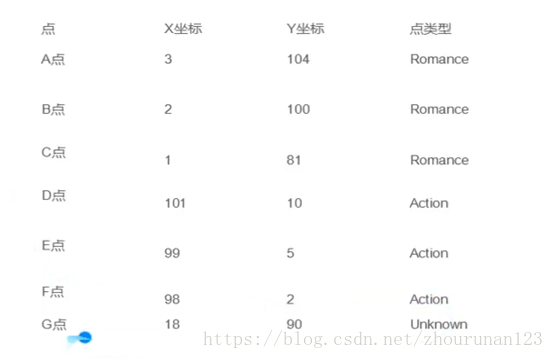
import math
def ComputeEuclideanDistance(x1,y1,x2,y2):
d = math.sqrt(math.pow((x1-x2),2) + math.pow((y1-y2),2))
return d
d_ag = ComputeEuclideanDistance(3,104,18,90)
d_bg = ComputeEuclideanDistance(2,100,18,90)
d_cg = ComputeEuclideanDistance(1,81,18,90)
d_dg = ComputeEuclideanDistance(101,10,18,90)
d_eg = ComputeEuclideanDistance(99,5,18,90)
d_fg = ComputeEuclideanDistance(98,2,18,90)
print('d_ag',d_ag)
print('d_bg',d_bg)
print('d_cg',d_cg)
print('d_dg',d_dg)
print('d_eg',d_eg)
print('d_fg',d_fg)

若K=3,与其最近的3个点为A B C,所以G为romance类