1 KNN算法
1.1 KNN算法简介
KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类对应的关系。输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k近邻算法中k的出处,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类作为新数据的分类。
说明:KNN没有显示的训练过程,它是“懒惰学习”的代表,它在训练阶段只是把数据保存下来,训练时间开销为0,等收到测试样本后进行处理。
举例:以电影分类作为例子,电影题材可分为爱情片,动作片等,那么爱情片有哪些特征?动作片有哪些特征呢?也就是说给定一部电影,怎么进行分类?这里假定将电影分为爱情片和动作片两类,如果一部电影中接吻镜头很多,打斗镜头较少,显然是属于爱情片,反之为动作片。有人曾根据电影中打斗动作和接吻动作数量进行评估,数据如下:
| 电影名称 |
打斗镜头 |
接吻镜头 |
电影类别 |
| Califoria Man |
3 |
104 |
爱情片 |
| Beautigul Woman |
1 |
81 |
爱情片 |
| Kevin Longblade |
101 |
10 |
动作片 |
| Amped II |
98 |
2 |
动作片 |
给定一部电影数据(18,90)打斗镜头18个,接吻镜头90个,如何知道它是什么类型的呢?KNN是这样做的,首先计算未知电影与样本集中其他电影的距离(这里使用曼哈顿距离),数据如下:
| 电影名称 |
与未知分类电影的距离 |
| Califoria Man |
20.5 |
| Beautigul Woman |
19.2 |
| Kevin Longblade |
115.3 |
| Amped II |
118.9 |
现在我们按照距离的递增顺序排序,可以找到k个距离最近的电影,加入k=3,那么来看排序的前3个电影的类别,爱情片,爱情片,动作片,下面来进行投票,这部未知的电影爱情片2票,动作片1票,那么我们就认为这部电影属于爱情片。
1.2 KNN算法优缺点
优点:精度高,对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
引用:https://www.cnblogs.com/erbaodabao0611/p/7588840.html
1.3 曼哈顿距离
曼哈顿距离(Manhattan Distance)
顾名思义,在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
- 二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离:
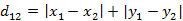
- n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的曼哈顿距离:
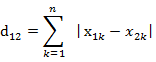
欧氏距离或曼哈顿距离:

引用:https://my.oschina.net/hunglish/blog/787596
1.4 将knn算法应用于手写字体识别:
提供数据:
mnist-010.csv文件:
第一列为label
之后784列为每个像素数据,值为0或1(大于180的置1,小于180的置0)
务必将训练集与测试集分开
2.0 代码如下:
导入数据
import pandas as pd import numpy as np #将数据载人矩阵,前40000为训练库,后2000为实验矩阵 path =r"C:\Users\dhw\Desktop\work\term paper\Home work_9\mnist_010.csv" def opendata(path): df = pd.read_csv(path) list_label = df['label'] df_pixel = df.drop(['label'], axis = 1) array_pixel = np.array(df_pixel).reshape((42000,784)) array_train = array_pixel[:40000] array_data = array_pixel[40000:] list_train = list_label[:40000] list_data = list_label[40000:] return list_train return list_data return array_train return array_data #csv文件数据打印如下 # label pixel0 pixel1 ... pixel781 pixel782 pixel783 #0 1 0 0 ... 0 0 0 #1 0 0 0 ... 0 0 0 #2 1 0 0 ... 0 0 0 #3 4 0 0 ... 0 0 0 #4 0 0 0 ... 0 0 0 #... ... ... ... ... ... ... ... #41997 7 0 0 ... 0 0 0 #41998 6 0 0 ... 0 0 0 #41999 9 0 0 ... 0 0 0
2.1 代码中函数解析:
(1)建立一个4×2的矩阵c, c.shape[1] 为第一维的长度,c.shape[0] 为第二维的长度。
>>> c = array([[1,1],[1,2],[1,3],[1,4]]) >>> c.shape (4, 2) >>> c.shape[0] 4 >>> c.shape[1] 2
(2)利用pandas库 将数据中的一行或一列删除
删除表中的某一行或者某一列更明智的方法是使用drop,它不改变原有的df中的数据,而是返回另一个dataframe来存放删除后的数据。
https://blog.csdn.net/nuaadot/article/details/78304642
(3)numpy 数组操作
https://blog.csdn.net/sinat_34474705/article/details/74458605
(4)矩阵切片
https://www.2cto.com/kf/201706/648996.html