原理理解
KNN就是K最近邻算法,是一种分类算法,意思是选k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。在k个样本中,比重最大的那一类即可把目标归为这一类。
有句话说的好 物以类聚 人以群分 我们想要看某个人是好人还是坏人是什么 ,就得看看他相处的朋友中好的人多还是坏的人多,虽然这个解释比较牵强,但是在KNN算法中原理就是这样的。
KNN算法的目的是:搜寻最近的K个已知类别样本用于未知类别样本的预测。
同时在KNN算法中K的取值非常重要,如下图,当K=3和K=5时,所得出的结果是截然不同的。

算法流程
K近邻算法的一般流程:
1、收集数据:可以使用任何方法。
2、准备数据:距离计算所需要的数值,最好是结构化的数据格式。
3、分析数据:可以使用任何方法。
4、训练算法:此步骤不适用于 K 近邻算法。
5、测试算法:计算错误率。
6、使用算法:首先需要输入样本数据和结构化的输出结果,然后运行K 近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
代码实践
- 电影类别分类
- 癌症预测
- 鸢尾花分类
- 手写数字识别
电影类别分类
Code
# -*- coding: UTF-8 -*-
import collections
import numpy as np
def createDataSet():
#四组二维特征
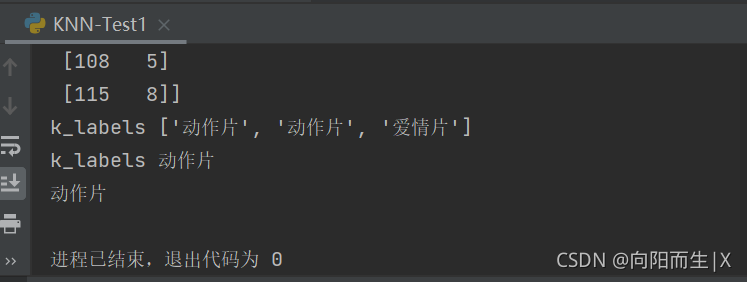
group = np.array([[1,101],[5,89],[108,5],[115,8]])
print(group)
#四组特征的标签
labels = ['爱情片','爱情片','动作片','动作片']
return group, labels
def classify(inx, dataset, labels, k):
# 计算距离 其实就是计算点一定之间的距离
dist = np.sum((inx - dataset)**2, axis=1)**0.5
#print("dist",dist)
# k个最近的标签
# dist.argsort 将x中的元素从小到大排列,提取其对应的index(索引)
k_labels = [labels[index] for index in dist.argsort()[0 : k]]
print('k_labels', k_labels)
# 出现次数最多的标签即为最终类别
#主要功能:可以支持方便、快速的计数,将元素数量统计,然后计数并返回一个字典,键为元素,值为元素个数。
print('k_labels',collections.Counter(k_labels).most_common(1)[0][0])
label = collections.Counter(k_labels).most_common(1)[0][0]
return label
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [55,20]
#kNN分类
#test_class = classify0(test, group, labels, 3)
test_class = classify(test, group, labels, 3)
#打印分类结果
print(test_class)
癌症预测
Code
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter # 为了做投票
# raw_data_x属于特征值,分别属于患病时间和肿瘤大小
raw_data_x = [[3.3935, 2.3312],
[3.1101, 1.7815],
[1.3438, 3.3684],
[3.5823, 4.6792],
[2.2804, 2.8670],
[7.4234, 4.6965],
[5.7451, 3.5340],
[9.1722, 2.5111],
[7.7928, 3.4241],
[7.9398, 0.7916]]
# raw_data_y属于目标值,0代表良性肿瘤,1代表恶性肿瘤
row_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
class KNNClassifier:
def __init__(self, k):
assert k > 1, "K值必须大于1"
self.k = k
self.x_train = None
self.y_train = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train和y_train训练分类器
x_train: 训练数据的特征
y_train: 训练数据的目标
"""
assert x_train.shape[0] == y_train.shape[0], "x_train的大小必须等于y_train的大小"
assert self.k <= x_train.shape[0], "x_train的大小必须大于K"
self.x_train = x_train
self.y_train = y_train
def euc_dis(self, instance1, instance2):
"""
计算两个样本instance1和instance2之间的欧式距离
instance1: 第一个样本, array型
instance2: 第二个样本, array型
"""
dist = np.sqrt(sum((instance1 - instance2) ** 2))
return dist
def knn_classify(self, testInstance):
"""
给定一个测试数据testInstance, 通过KNN算法来预测它的标签。
testInstance: 测试数据,这里假定一个测试数据为array型
"""
distances = [self.euc_dis(x, testInstance) for x in self.x_train]
kneighbors = np.argsort(distances)[:self.k]
count = Counter(self.y_train[kneighbors])
return count.most_common()[0][0]
def score(self, x_test, y_test):
"""根据测试样本x_test进行预测,和真实的目标值y_test进行比较,计算预测结果的准确度"""
predictions = [self.knn_classify(x) for x in x_test]
correct = np.count_nonzero((predictions == y_test) == True)
return float(correct)/len(x_test)
def __repr__(self):
return "KNN(k={})".format(self.k)
if __name__ == "__main__":
# 从数据集中选择2个样本为测试样本, 其余的均为训练样本
x_train = np.array(raw_data_x[:-2])
y_train = np.array(row_data_y[:-2])
x_test = np.array(raw_data_x[-2:])
y_test = np.array(row_data_y[-2:])
knn = KNNClassifier(3)
knn.fit(x_train, y_train)
score = knn.score(x_test, y_test)
print("测试精确度为: %.3f" % score)
# 未知的待分类样本
x_test2 = np.array([8.9093, 3.3657])
result = knn.knn_classify(x_test2)
if result == 0: result = "良性肿瘤"
else: result = "恶性肿瘤"
print("对[8.9093, 3.3657]的预测结果为:【%s】" % result)
鸢尾花分类
Sklearn 已经成为最给力的Python机器学习库(library)了。scikit-learn支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块运用到了sklearn
https://scikitlearn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
https://sklearn.apachecn.org/docs/master/7.html
Sklearn小测试
from sklearn.neighbors import KNeighborsClassifier
X = [[0], [1], [2], [3], [4], [5], [6], [7], [8]]
y = [0, 0, 0, 1, 1, 1, 2, 2, 2]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X, y)
# fit函数 使用X作为训练数据,y作为目标值(类似于标签)来拟合模型。
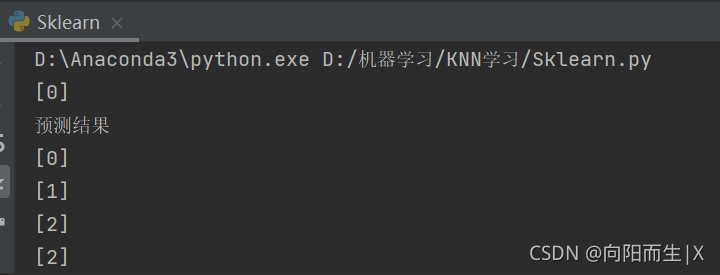
print(neigh.predict([[1.1]]))
##这里预测使用的值是1.1得到的结果是0 表明1.1应该在0这个类里面
print(neigh.predict([[1.6]]))
print(neigh.predict([[5.2]]))
print(neigh.predict([[7.2]]))
print(neigh.predict([[8.2]]))
Code
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
class KNN(object):
# 获取鸢尾花数据 三个类别(山鸢尾/0,虹膜锦葵/1,变色鸢尾/2),每个类别50个样本,每个样本四个特征值(萼片长度,萼片宽度,花瓣长度,花瓣宽度)
def get_iris_data(self):
iris = load_iris()
iris_data = iris.data
iris_target = iris.target
return iris_data, iris_target
def run(self):
# 1.获取鸢尾花的特征值,目标值
iris_data, iris_target = self.get_iris_data()
#print("iris_data, iris_target",iris_data, iris_target)
# 2.将数据分割成训练集和测试集 test_size=0.25表示将25%的数据用作测试集
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)
# 3.特征工程(对特征值进行标准化处理)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 4.送入算法
knn = KNeighborsClassifier(n_neighbors=5) # 创建一个KNN算法实例,n_neighbors默认为5,后续通过网格搜索获取最优参数
knn.fit(x_train, y_train) # 将测试集送入算法
y_predict = knn.predict(x_test) # 获取预测结果
# 预测结果展示
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_predict)):
print("第%d次测试:真实值:%s\t预测值:%s"%((i+1),labels[y_test[i]],labels[y_predict[i]]))
print("准确率:",knn.score(x_test, y_test))
if __name__ == '__main__':
knn = KNN()
knn.run()
手写体识别
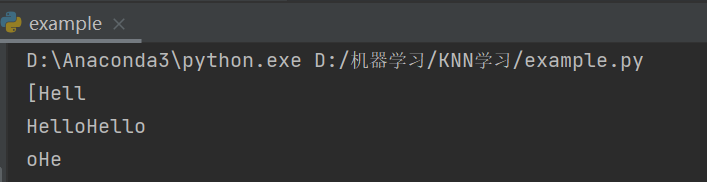
str='[HelloHello]'
print(str.split('o')[0])#得到的是第一个o之前的内容
print(str.split("[")[1].split("]")[0])#得到的是[前 ]后的内容
print(str.split('l')[2])#第二个和第三个l之间的内容
Code
# -*- coding: UTF-8 -*-
import numpy as np
#operator 模块是 Python 中内置的操作符函数接口,它定义了算术,比较和与标准对象 API 相对应的其他操作的内置函数。
import operator
from os import listdir
from sklearn.neighbors import KNeighborsClassifier as kNN
def img2vector(filename):
#创建1x1024零向量
returnVect = np.zeros((1, 1024))
#打开文件
fr = open(filename)
#按行读取
for i in range(32):
#读一行数据
lineStr = fr.readline()
#每一行的前32个元素依次添加到returnVect中
for j in range(32):
returnVect[0, 32*i+j] = int(lineStr[j])
#返回转换后的1x1024向量
return returnVect
def handwritingClassTest():
#测试集的Labels
hwLabels = []
#listdir 返回trainingDigits目录下的文件名
trainingFileList = listdir('trainingDigits')
#print('trainingFileList',trainingFileList)
#返回文件夹下文件的个数
m = len(trainingFileList)
#初始化训练的Mat矩阵,测试集
trainingMat = np.zeros((m, 1024))
#从文件名中解析出训练集的类别
for i in range(m):
#获得文件的名字
fileNameStr = trainingFileList[i]
#获得分类的数字 str.split 获取字符’_‘之前的内容
classNumber = int(fileNameStr.split('_')[0])
#将获得的类别添加到hwLabels中
hwLabels.append(classNumber)
#将每一个文件的1x1024数据存储到trainingMat矩阵中
#trainingMat 是创建了一个m行,1024列的(内容全是零)数组,
#trainingMat[i,:] 是把img2vector方法返回的列表放进trainingMat的第i行
trainingMat[i,:] = img2vector('trainingDigits/%s' % (fileNameStr))
#print('trainingMat',trainingMat)
#构建kNN分类器
neigh = kNN(n_neighbors = 3, algorithm = 'auto')
#拟合模型, trainingMat为测试矩阵,hwLabels为对应的标签
neigh.fit(trainingMat, hwLabels)
#返回testDigits目录下的文件列表 listdir 返回文件名
testFileList = listdir('testDigits')
#错误检测计数
errorCount = 0.0
#测试数据的数量
mTest = len(testFileList)
#从文件中解析出测试集的类别并进行分类测试
for i in range(mTest):
#获得文件的名字
fileNameStr = testFileList[i]
#获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
#获得测试集的1x1024向量,用于训练
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
#获得预测结果
# classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3
classifierResult = neigh.predict(vectorUnderTest)
print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))
if(classifierResult != classNumber):
errorCount += 1.0
print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount/mTest * 100))
if __name__ == '__main__':
handwritingClassTest()
思考
优点
- 理论成熟,思想简单,既可以用来做分类又可以做回归
- 可以用于非线性分类
缺点
- 对训练数据依赖度特别大
- 向量的维度越高,欧式距离的区分能力就越弱
借鉴
https://jackcui.blog.csdn.net/article/details/75172850
https://blog.csdn.net/qq_41689620/article/details/82421323
Sklearn中文文档
https://blog.csdn.net/XiaoYi_Eric/article/details/79952325
KNN算法实现肿瘤预测案例