一、K近邻算法概述
KNN算法属于我们监督学习里面一种分类算法,避开那些文邹邹的话语,用幼稚园的话来说,就是依据已知的,来对未知的事物进行分类。
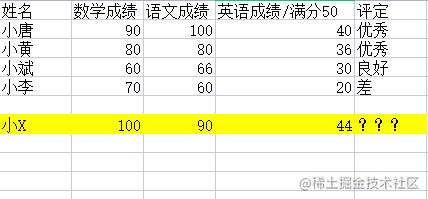
我们要求求小X的评定,我们会怎么来做?
按照我们的经验是不是看他和那一段的分数最接近,如果你是这样想的,恭喜你,KNN算法的基本思维,我们已经掌握了。
没错,就是通过比较样本之间的距离,取得出我们的结论,我们先将小X同学和所有同学的欧式距离求出。
当然还有其他什么曼哈顿距离,切比夫斯距离呀等等等,欧拉距离相当简单,本文以欧拉距离为例
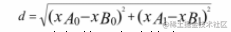
就是每一列数据差值的平方开根号,然后按照大小顺序对其进行排序,我们再圈定一个范围K值(就是选多少个数据)来对我们的选取的例子进行投票,因为选取的这些数据的评定都是确定的,所以我们直接统计标签个数即可。
我们先定义k=3(求出欧式距离后,排序后前三的取值)
这里很明显由于,小X所求的欧式距离,很明显,入选的有小唐,小黄,小斌。
统计票数
优秀 2票 良好1票
所以小X同学是优秀!
细心的同学已经发现,就是在我们两者之间的差值比较大的时候,会对我们的权重造成影响,举个极端一点的列子
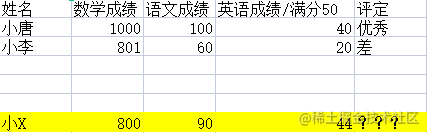
这样子得出的小X同学和小唐同学的欧式距离是不是特别大,(1000-800)^2是不是远大于其他科目的值,所以我们的数据需要规格化

二、K近邻三要素
距离度量
就是我们刚刚的欧式距离啦!不过我们这这里给他做一个规格化,让他的每一个取值范围,在0~1。就是求出我们每一列的最大值和最小值,把他们的和作为分母,列当前的值减去最小值作为分子
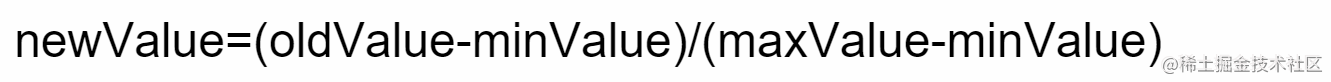
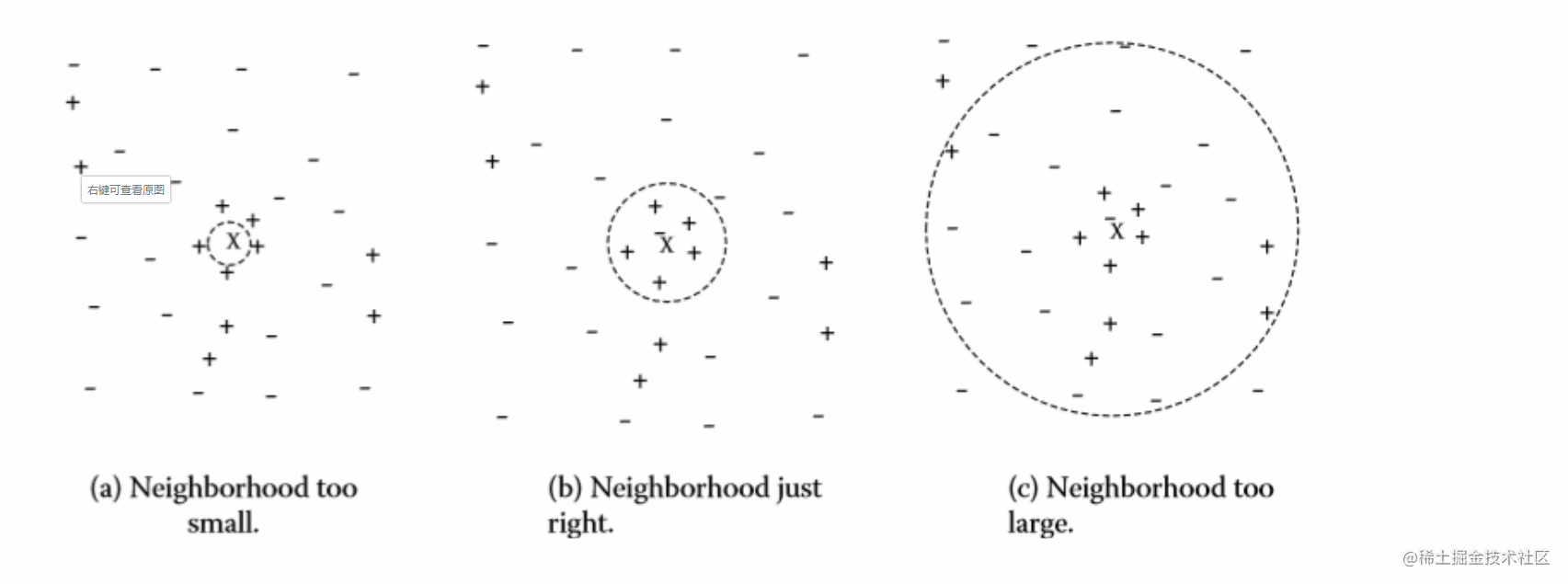
k值选择
k值(就是距离排序后,取前k个)的选择也是一门学问
图a取值过小时,会造成我们样本过小
图b取值刚好
图c取值过大,会造成误差过大
分类决策规程
最常用的就是投票,谁多,谁就是!
代码
'''
Created on 3/9,2020
@author: ywz
'''
"""
1、距离计算
2、k值
3、决策机制
"""
import numpy as np # import 导入包/模块 as:取别名
from numpy import * # * 表示numpy 所有的函数方法
def classify_knn(inx, data_set, labels, k):
"""
:param inx: vec need to predict classify
:param data_set: samples
:param labels: classes
:param k: the k of knn
:return: the class of predict
"""
data_set_size = data_set.shape[0]
# numpy中的tile函数:复制(被复制对象,(行数,列数))
diff_mat = tile(inx, (data_set_size, 1)) - data_set
sqrt_diff_mat = diff_mat**2
# axis表示求和的方向,axis=0表示同一列相加,axis=1表示同一行相加
sqrt_distance = sqrt_diff_mat.sum(axis=1)
distances = sqrt_distance**0.5
# print('type of distances:', type(distances)) # numpy.ndarray
# print(distances)
# distances.argsort()得到的是从小到大排序的索引值
sorted_distances = distances.argsort()
class_count = {}
for i in range(k):
vote_label = labels[sorted_distances[i]]
if vote_label not in class_count:
class_count[vote_label] = 0
class_count[vote_label] += 1
# print("class_count:", class_count)
class_predict = max(class_count.items(), key=lambda x: x[1])[0]
return class_predict
def file2matrix(filename):
"""
:读取文件,返回文件中的特征矩阵和标签值
:param filename:
:return: features_matrix, label_vec
"""
fr = open(filename) # open-->文件句柄
lines = fr.readlines() # read,
print("lines:")
print(lines)
num_samples = len(lines)
mat = zeros((num_samples, 3))
class_label_vec = []
index = 0
for line in lines:
line = line.strip()
list_line = line.split('\t')
mat[index, :] = list_line[0:3]
class_label_vec.append(int(list_line[-1]))
index += 1
return mat, class_label_vec
mat, class_label_vec = file2matrix("datingTestSet2.txt")
# print(mat.shape)
# print(class_label_vec.shape) # ???
def auto_norm(data_set):
"""
:param data_set:
:return:
"""
min_val = data_set.min(0)
max_val = data_set.max(0)
ranges = max_val - min_val
norm_data_set = zeros(shape(data_set))
num_samples = data_set.shape[0]
# 归一化:newValue = (oldValue - minValue) / (maxValue - minValue)
norm_data_set = data_set - tile(min_val, (num_samples, 1))
norm_data_set = norm_data_set/tile(ranges, (num_samples, 1))
return norm_data_set, ranges, min_val
def test_knn(file_name):
"""
:return:
"""
ratio = 0.1
data_matrix, labels = file2matrix(file_name)
nor_matrix, ranges, minval = auto_norm(data_matrix)
num_samples = data_matrix.shape[0]
num_test = int(ratio*num_samples)
k_error = {}
k = 3
error_count = 0
predict_class = []
# 数据集中的前num_test个用户假设未知标签,作为预测对象
for i in range(num_test):
classifier_result = classify_knn(nor_matrix[i, :], nor_matrix[num_test:, :],
labels[num_test:], k)
predict_class.append(classifier_result)
if classifier_result != labels[i]:
error_count += 1
print("k={},error_count={}".format(k, error_count))
k_error[k] = error_count
print("误差情况:", k_error)
print("预测情况:", predict_class[:10])
print("真实情况:", labels[:10])
return k_error
# for k in range(1, 31):
# error_count = 0
# for i in range(num_test):
# classifier_result = classify_knn(nor_matrix[i, :], nor_matrix[num_test:, :],
# labels[num_test:], k)
# if classifier_result != labels[i]:
# error_count += 1
# print("k={},error_count={}".format(k,error_count))
# k_error[k] = error_count
# print(k_error)
best = min(k_error.items(), key=lambda x: x[1])
return best
if __name__ == '__main__':
samples_file = "datingTestSet2.txt"
best = test_knn(samples_file)
print(best)