一、KNN
k-Nearest Neighbour algorithm,也叫KNN算法、K近邻算法。
是机器学习中最简单、最基础的一个入门算法。
在认识任何一个算法之前,都要先了解这个算法适合的数据结构,所以我们适合KNN的数据说起。
1、准备数据

2、数据探索
3、KNN原理及相关数学
计算预测样本与训练样本之间的距离,找出与预测样本最近的K个训练样本的标签,然后以少数服从多数的原则(majority-voting),将预测样本与K个最邻近样本中所属类别占比较多的归为一类。 其指导思想是“近朱者赤,近墨者黑”,即由你的邻居来推断出你的类别。
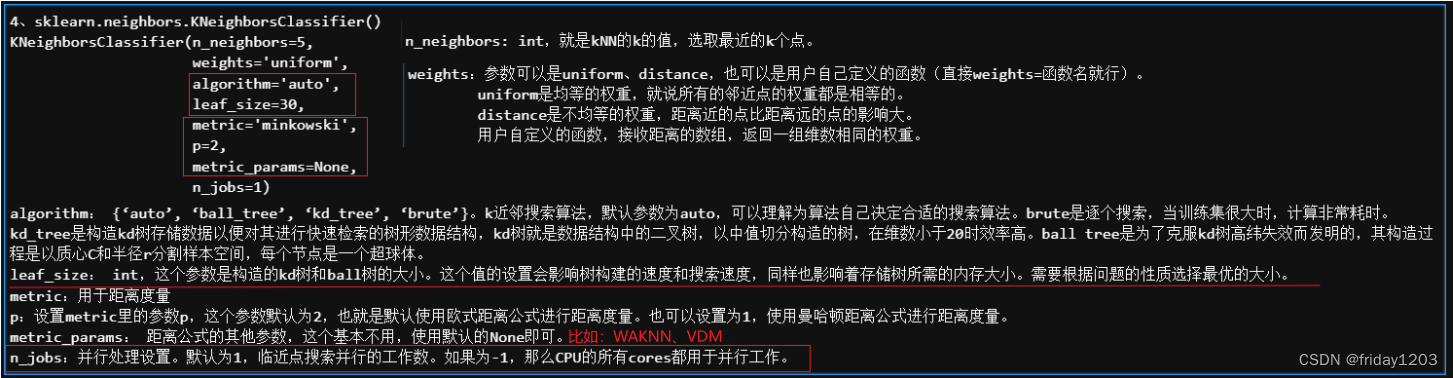
4、调包实现:sklearn.neighbors.KNeighborsClassifier()
这是机器学习框架sklearn中的KNN算法,我是建议大家直接调包使用即可。因为KNN的原理非常简单,你也可以自己动手写一个算法也是可以的,但是如果你的数据量是数百万条样本甚至数千万条样本,那你自己写的算法就显得差强人意了,因为sklearn中打包好的算法,不仅实现了最近邻的距离计算,还优化了索引速度,就是训练数据喂入模型,模型fit后,算法就先自动将训练数据进行树结构存储,以便后续预测的时候可以快速索引,而实现这个功能是构建kd树等算法实现的,而构建kd树的算法又不是算法工程师擅长,它需要很多计算机底层的优化技术,是开发工程师重点考虑的内容,所以我不建议大家自己手写这个算法,直接掉包使用即可。而且KNN是一个及其简单入门级别的算法,很多情况下都是拿来测试数据的潜力的,所以更不需要自己手写了。所以下面详细介绍一下KNeighborsClassifier()的参数:
5、KNN建模预测
from sklearn.neighbors import KNeighborsClassifier #模型
from sklearn.preprocessing import LabelBinarizer #处理标签列
#(1)处理标签
binarized = LabelBinarizer()
label = binarized.fit_transform(data['性别']) #label是一个二维数据
#(2)建模
k=5 #必填参数
knn = KNeighborsClassifier(n_neighbors = k) #实例化一个KNN分类器
clf = knn.fit(data.iloc[:, :-1], label.ravel()) #要把label拉平,变成一维的
#(3)预测
predict = clf.predict(x)
predicted_label = binarized.inverse_transform(predict)
predicted_labelarray(['female', 'male'], dtype='<U6')
6、小结:
(1)KNN算法最早用于分类任务,但随着算法的优化也可以进行回归预测。
(2)KNN是一个惰性模型,就是它不用提前学习,当开始预测时,逐个遍历训练数据进行距离计算。所以这个模型的最大缺点就是慢。
(3)当样本不均衡时,算法几乎失效。
(4)当样本分布重叠的时候,这个算法也不合适。
(5)注意标签,标签必须是数值型,而且必须是一维的。
(6)K的设置。K最好是设置奇数个,防止平局。k=1时成为最近邻模型。
下面我用代码生成两类数据,然后可视化看看: 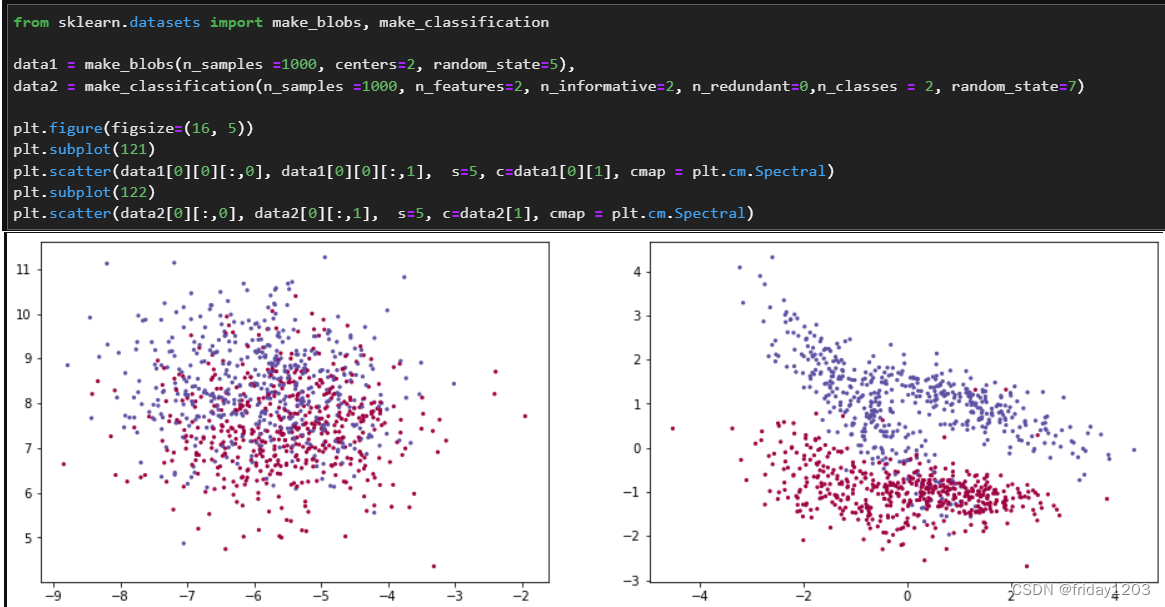
可见,如果你的数据是左图,你用KNN是及不合适,如果你的数据分布类似右图,那KNN的效果还是不错的。所以一个算法的好坏主要是看是否匹配你的数据,所以使用任何一个算法的前提都是要非常了解你的数据。当然我这里举例的数据是只有2个特征的数据,可以可视化,实际中我们经常遇到的数据是高维的,根本无法可视化,此时KNN就只能是你拿来看看数据的潜力的小工具了。
7、补充:
KNN还可以改编到多标签分类场景下。Multi-Label Machine Learning(MLL算法)就是预测模型中存在多个y值的情况。当然不止KNN,像决策树、线性回归、SVM、RidgeCV都可以,这里展示一个KNN的多标签回归预测案例:
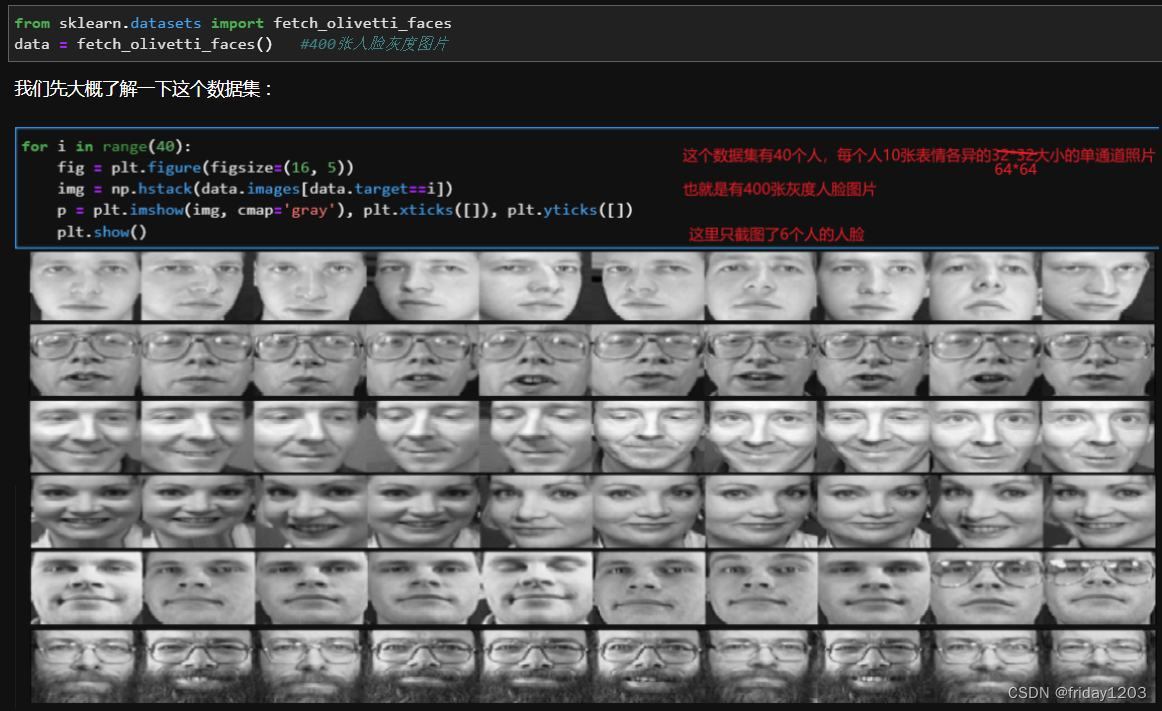
#制作训练集和测试集:我们随机挑5张图片作为测试集,剩下的图片全部作为训练集。然后把训练集的人脸的上半部分作为特征,下半部分作为多标签
import random
random.seed(6)
choice = [random.randint(0, 40)*10 for i in range(5)] #[360, 50, 310, 160, 20]我们挑出这5张作为测试集的索引
test_img = data.data[choice] #这是测试集的5张全脸图片
train_img = data.data[[i for i in list(range(400)) if i not in choice]] #这是训练集的395张全脸
trainx = train_img.reshape(395, 64, 64)[:, :32, :] #这是训练集的395张上半脸
trainy = train_img.reshape(395, 64, 64)[:, 32:, :] #这是训练集的395个标签
testx = test_img.reshape(5, 64, 64)[:, :32, :] #这是测试集的5张上半脸from sklearn.neighbors import KNeighborsRegressor
estimator1 = KNeighborsRegressor()
estimator1 = estimator1.fit(trainx.reshape(395, 2048), trainy.reshape(395, 2048))
predict1 = estimator1.predict(testx.reshape(5,2048))from sklearn.ensemble import ExtraTreesRegressor
estimator2 = ExtraTreesRegressor(n_estimators=10, max_features=32, random_state=123)
estimator2 = estimator2.fit(trainx.reshape(395, 2048), trainy.reshape(395, 2048))
predict2 = estimator2.predict(testx.reshape(5,2048))from sklearn.linear_model import LinearRegression
estimator3 = LinearRegression()
estimator3 = estimator3.fit(trainx.reshape(395, 2048), trainy.reshape(395, 2048))
predict3 = estimator3.predict(testx.reshape(5,2048))from sklearn.linear_model import RidgeCV
estimator4 = RidgeCV()
estimator4 = estimator4.fit(trainx.reshape(395, 2048), trainy.reshape(395, 2048))
predict4 = estimator4.predict(testx.reshape(5,2048)) 上面四个算法的预测效果如下: 
#这是绘图代码
plt.figure(figsize=(12, 8))
plt.subplot(1,5,1), plt.imshow(test_img[0].reshape(64,64), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,2), plt.imshow(test_img[1].reshape(64,64), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,3), plt.imshow(test_img[2].reshape(64,64), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,4), plt.imshow(test_img[3].reshape(64,64), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,5), plt.imshow(test_img[4].reshape(64,64), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.figure(figsize=(12, 8))
plt.subplot(1,5,1), plt.imshow(np.concatenate((testx[0], predict1[0].reshape(32, 64)), axis=0), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,2), plt.imshow(np.concatenate((testx[1], predict1[1].reshape(32, 64)), axis=0), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,3), plt.imshow(np.concatenate((testx[2], predict1[2].reshape(32, 64)), axis=0), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,4), plt.imshow(np.concatenate((testx[3], predict1[3].reshape(32, 64)), axis=0), cmap='gray'), plt.xticks([]), plt.yticks([])
plt.subplot(1,5,5), plt.imshow(np.concatenate((testx[4], predict1[4].reshape(32, 64)), axis=0), cmap='gray'), plt.xticks([]), plt.yticks([])哈哈哈。。。有没有发现这个多标签回归还挺惊艳!竟然可以当个生成模型来用!