一.K-近邻算法


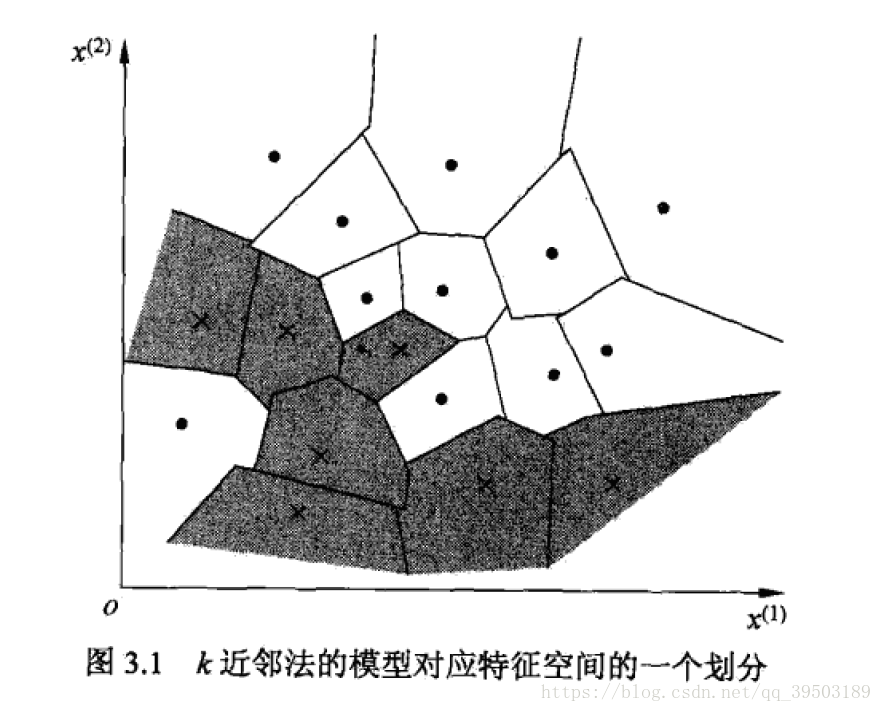
1.距离的度量:

1.2 k值的选择:


1.3 分类决策规则:

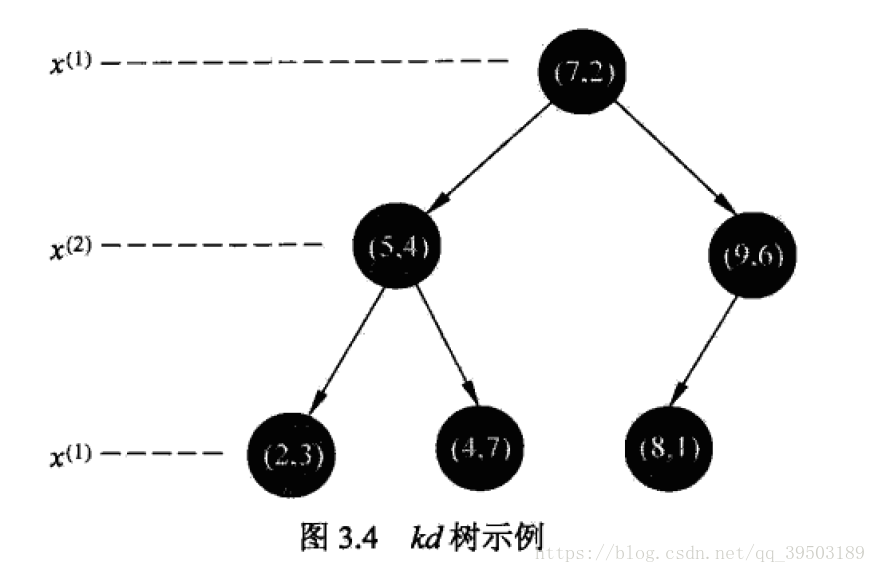
二.kd树:

3.2:平衡kd树:


3.2.2:搜索kd树:

扫描二维码关注公众号,回复:
2664622 查看本文章


3.3用kd树的最近邻搜索:


4.KNN总结:


5.具体流程:
k-近邻算法的一般流程
(1) 收集数据:可以使用任何方法。
(2) 准备数据:距离计算所需要的数值,最好是结构化的数据格式。
(3) 分析数据:可以使用任何方法。
(4) 训练算法:此步骤不适用于k-近邻算法。
(5) 测试算法:计算错误率。
(6) 使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输
入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;
- 可用于数值型数据和离散型数据;
- 训练时间复杂度为O(n);无数据输入假定;
- 对异常值不敏感。
缺点:
- 计算复杂性高;空间复杂性高;
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
- 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。
- 最大的缺点是无法给出数据的内在含义。
参考资料:
- 李航《统计学习方法》
- jack-cui博客:https://blog.csdn.net/c406495762/article/details/75172850