前言:
好了,又来写博文了,最近在学《机器学习实战》和《统计学习方法》这两本书,一本重编程方法,一本重数学理论,我接触到的学机器学习的也大多看这两本书,这里就先推荐给大家作为学习路线参考,两本书相互照应,学习时可以两本齐头并进。
然后呢,因为内容比较难,所以看书之后又看视频和CSDN博客,我看的视频是bilibili里的深度眸的
【机器学习实战】【python3版本】【代码讲解】;给个视频链接,https://www.bilibili.com/video/av36993857/?p=1
视频里也会推荐一些大牛的博客
最后呢,此文为本人学习笔记,仅是自己的学习记录,文中一些截图为jack-cui博主的博文:
https://blog.csdn.net/c406495762/article/details/75172850
好了,下面的大家就不必看了,全是我抄的jack-cui的代码。
KNN算法(K近邻)原理
knn算法是机器学习的最简单的一个算法,可以用一分钟解释清楚原理的那种。俗话说物以类聚,人以群分,KNN就是利用的这种原理,通过观察,计算离一个目标最近的k个对象的类别,来判断该目标的类别,比如,取k为5(k一般取奇数,原因很简单),距离该目标最近的4个为正方形,1个为圆形,那么就判定该目标为正方形。关于k值得选择呢,看书吧:

我在最初听说这个算法的原理的时候,很怀疑该原理的正确性,觉得过于简单粗爆,但祖先传了几百年上千年的俗话“物以类聚,人以群分”不是没有道理的。如果数据集给的好,KNN算法的预测准确率还是相当之高的。
然后就要面临几个问题,我们现在知道了K是取周围就近的K个对象,K是我们人为定义的,然后我们还需要知道,要怎么求距离??这里我们先提一下,数据集肯定都是数,不论这些数的意义代表什么,皆可计算,计算公式一般采用欧式距离,像我们高中学的计算两点之间距离的公式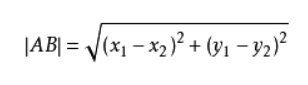
就是运用的欧氏距离。
好了,到这里我们应该就知道KNN算法是个怎样的“小虫子”了,给一个K值,通过欧氏距离计算离目标最近的K个对象,通过这K个对象来判断该目标的类型。就这么简单,下面通过两个例子讲解下代码。
例子一:分类一个电影是爱情片还是动作片
具体讲解内容参照《机器学习实战》,下面主要解释代码实现过程
首先,我们应该输入数据集,因为数据集比较小,我们可以通过下面代码进行手打输入,当数据集大的时候,就需要靠读取数据集文件,在后面我们会讲到。
#创建数据 第一个例子
def createDetaSet():
group = array([[1.0,101],[5,89],[108,5],[115,8]])
labels = ['爱情片','爱情片','动作片','动作片']
return group,labels
在输入一些电影的打斗次数和接吻次数以及该电影各自的类别标签后,我们想知道一接吻101次,打斗次数20的电影是什么类型,就需要计算距离了,因为只有两个标准(一个打斗,一个接吻),因此就用两点之间距离公式来计算就可以,除了常用的欧氏距离,还有下面一些距离准测:

通过计算我们可以得到如下结果:
•(101,20)->动作片(108,5)的距离约为16.55
•(101,20)->动作片(115,8)的距离约为18.44
•(101,20)->爱情片(5,89)的距离约为118.22
•(101,20)->爱情片(1,101)的距离约为128.69
如果我们取k=3,那么离目标最近的三个为动作片,动作片,爱情片,我们便可以说该目标电影为动作片。
但距离计算代码怎么写呢?
@inX : 需要测试样本
@dataSet : 训练样本集
@labels : 训练样本标签
@K : K近邻
#分类算法
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #shape[]函数 返回dataSet 的行,列 0表示行,1表示列
#timplement_array_function函数将inX向量在行上复制dataSetSize行,在列上复制一行
diffMat = timplement_array_function(inX,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2 #求平方
sqDistances = sqDiffMat.sum(axis = 1) #sum()函数:sum(0)表示列相加,sum(1)表示行相加
distances = sqDistances**0.5 #欧式距离计算
sortedDistIndicies = distances.argsort() #排序算法
classCount = { }
for i in range(k): #拿前k个
#依次取前k个的标签
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #选择距离最近的K个点
sortedClassCount = sorted(classCount.iteritems(),
key=operator.itemgetter(1),reverse= Ture) #排序
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
最后,在主函数中调用上述代码即可:
#创建数据集
group, labels = createDataSet()
#测试集
test = [101,20]
#kNN分类
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)
运行结果:

最后总结一下k近邻的实现流程:
k-近邻算法实战之约会网站配对效果判定
实战题目:
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所消耗时间百分比
- 每周消费的冰淇淋公升数
datingTestSet.txt里的数据集大致为这样:

之前我们通过createDetaSet()函数导入的小量数据集,但像上图如此庞大的数据集我们一般会采用导入数据集文件的方法,及通过读取文档,对文档进行拆分,剔除符号等操作来将数据集转换成矩阵或者列表等:
#将文件转换为数据
def file2matrix(filename):
fr = open(filename) #打开文件
arrayOLines = fr.readlines() #读取所以内容
numberOfLines = len(arrayOLines) #得到文件行数
returnMat = zeros((numberOfLines,3)) #创建返回用的Numpy矩阵
classLabelVector = []
index = 0
for line in arrayOLines:
line = license.strip() #截掉所有回车符
listFromLine = line.split('\t') #使用\t字符将上一步得到的整行数据分割成一个元素列表
returnMat[index,:] = listFromLine[0:3] #将前三个取出存储在returnMat中
classLabelVector.append(int(listFromLine[-1])) #解析文件数据到列表
index += 1
return returnMat,classLabelVector #返回特征数据 和 样本标签
导入数据后,还是和前面一样,运行如下主函数:
filename = "datingTestSet.txt" #打开文件名
datingDataMat,datingLabels = kNN.file2matrix(filename) #处理数据并返回
print(datingDataMat)
print(datingLabels) #打印
运行结果:

数据可视化
我们可以看到上面的数据并不能直接显示出我们想要的,我们并不能直观的在上面看出任何东西,因此我们需要运用python自带的绘图包Matplotlib进行绘制图形,Matplotlib的使用方法参照下面几篇博文即可:
https://blog.csdn.net/gdkyxy2013/article/details/80294021
https://blog.csdn.net/qq_20989105/article/details/82784010
https://blog.csdn.net/xHibiki/article/details/84866887
"""
函数说明:可视化数据
Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
无
"""
def showdatas(datingDataMat, datingLabels):
#设置汉字格式
font = FontProperties(size=14) #fname=r"c:\windows\fonts\simsun.ttc",
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
#当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig, axs = plt.subplots(nrows=2, ncols=2,sharex=False, sharey=False, figsize=(13,8))
numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i == 1:
LabelsColors.append('black')
if i == 2:
LabelsColors.append('orange')
if i == 3:
LabelsColors.append('red')
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x=datingDataMat[:,0], y=datingDataMat[:,1], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比',FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数',FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占',FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数',FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数',FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数',FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')
#画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数',FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比',FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数',FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
#设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses =mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses =mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
#添加图例
axs[0][0].legend(handles=[didntLike,smallDoses,largeDoses])
axs[0][1].legend(handles=[didntLike,smallDoses,largeDoses])
axs[1][0].legend(handles=[didntLike,smallDoses,largeDoses])
#显示图片
plt.show()
还要注意开头需要加上以下导入文件语句:
import numpy as np #导入科学计算包numpy
import operator #导入运算符模块
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
运行截图:

好了,到此就结束了,因为自己python基础打的不太好,也不能给出更多的代码详解了,好好学基础去了。