最近开始正式学机器学习的算法了,按照我的习惯学每个新的算法都喜欢记笔记,刚开始可能会有很多错误的地方以及很多遗漏的地方如果大家发现了还请多多指正。
文章目录
KNN简介:
KNN算法属于分类算法,也可以解决回归问题,英文名称为K-NearestNeighbor,直译过来就是K个最的邻居。他可以通过计算并找到要预测的数据和训练数据中前K个最近的数据,然后对他们进行统计和权重的投票计算,最终得出预测数据的结果。
算法的思路
假设有一个数据集,其中每个样本含有两个属性。那么这样的一个数据集就可以在一个二维的样本空间里进行描述,比如:
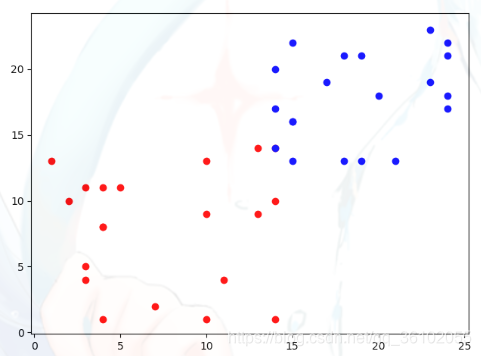
用x轴和y轴代表每个样本的两个属性,用不同的颜色代表每个样本的不同的标签,这样就可以在二维空间中直观的看到整个数据集了。
当新来一个需要预测的数据x时,依然可以把它放在其中描述,这里用绿色颜色进行表示
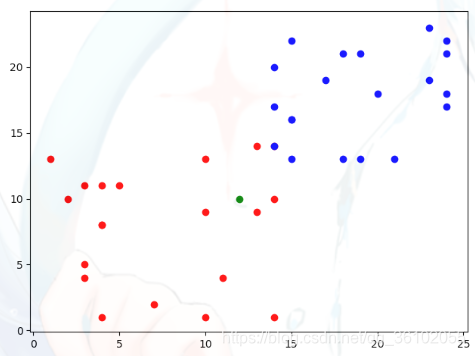
我们取k = 3,即我们取距离绿色点最近的三个点,这里距离我们采用欧拉距离,即直线距离。可以直观的看到,距离绿色点最近的三个点就是这些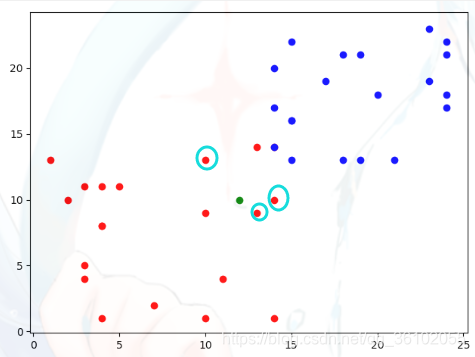
通过观察可一发现,他们都是红色即(红色:蓝色 = 3 : 0,新来的点为红色点的可能性更大),所以此时KNN算法就认为新来的绿色点也可能是红色点,此时KNN算法就完成了对新来的数据的预测。
总结一下就是
- 计算新的数据与所有训练集的样本的距离
- 取其中距离新的数据最近的k个样本
- 根据这个k个样本各自的权重进行统计
- 预测得出新来的点的类别
关于距离,这里采用的是欧拉距离,即 ( X 1 i − y 1 ) 2 + ( X 2 i − y 2 ) 2 \sqrt{(X_1^i - y_1)^2 + (X_2^i - y_2)^2} (X1i−y1)2+(X2i−y2)2
其中 X 1 i X_1^i X1i表示第i个样本的第1个属性的值,而 y 1 y_1 y1则表示预测数据的第1个属性。
X可以看做是一个矩阵,而y可以看做是一个向量。
实际上可以对这个式子进行推广,即 ∑ j = 1 n ( X j i − y j ) 2 \sqrt{\sum\limits_{j = 1}^n(X_j^i - y_j)^2} j=1∑n(Xji−yj)2表示当维度维n时的欧拉距离。
简单的实和sklearn的中的KNN的简单使用
简单的实现
知道了思路之后就可以简单的实现一下了
首先导入numpy
import numpy as np
对于一个n个样本m个特征的数据集可以看做是n X m的矩阵。
定义一个函数为KNN。
参数分别代表样本矩阵,标记向量,k,要预测的向量。
def KNN(X_train, y_train, k, x):
pass
第一步计算距离
用distance来存放
def KNN(X_train, y_train, k, x):
distance = np.sqrt(np.sum((X_train - x) ** 2, axis=1))
这里利用了numpy的sum,让其沿着列的方向进行求和,最终得到一个距离和的向量,然后再开平方。
接下来进行排序,获得每个元素的下标,使用argsort函数。
然后使用切片的方式获得前k个
def KNN(X_train, y_train, k, x):
distance = np.sqrt(np.sum((X_train - x) ** 2, axis=1))
nearst_indexes = np.argsort(distance)[0: k]
然后再入一个Counter类用于统计每种标签出现的次数
from collections import Counter
def KNN(X_train, y_train, k, x):
distance = np.sqrt(np.sum((X_train - x) ** 2, axis=1))
nearst_indexes = np.argsort(distance)[0: k]
votes = Counter(y_train[nearst_indexes])
最后取出出现次数最多的那个标签,并返回
def KNN(X_train, y_train, k, x):
distance = np.sqrt(np.sum((X_train - x) ** 2, axis=1))
nearst_indexes = np.argsort(distance)[0: k]
votes = Counter(y_train[nearst_indexes])
return votes.most_common()[0][0]
到此,一个简单的KNN算法就写完了
sklearn的中的KNN的简单使用
导入数据集
首先导入sklearn自带的一些数据集
from sklearn import datasets
然后这里使用最常使用的鸢尾花数据集,这里没个数据集都类似于一个小型字典,可以.来引用也可可以用key值来调用,输出一下键值就可以发现,一共有"数据,标签,标签名,描述,特征名"这些键,其中data和target就是所要使用的训练数据
iris = datasets.load_iris()
print(iris.keys())
'''
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
'''
打印一下DECSR里面有对这个数据集的详细描述
使用KNN
导入KNN算法
from sklearn.neighbors import KNeighborsClassifier
然后创建一个KNN分类算法的实例,然后可以设置一下k等于3
knn_classifier = KNeighborsClassifier(n_neighbors=3)
然后调用fit方法,即拟合,传入data和target
iris = datasets.load_iris()
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(X=iris['data'], y=iris['target'])
然后传入需要预测的数据就可以了,由于sklearn支持预测的是多个数据,所以建议传入数据时是一个二维的矩阵,比如:
iris = datasets.load_iris()
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(X=iris['data'], y=iris['target'])
x_predict = [[6.9, 3.0, 5.1, 2.1]]
print(knn_classifier.predict(x_predict))
'''
[2]
'''
可以打印出对应在target_names中的值
iris = datasets.load_iris()
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(X=iris['data'], y=iris['target'])
x_predict = [[6.9, 3.0, 5.1, 2.1]]
print(iris['target_names'][knn_classifier.predict(x_predict)[0]])
'''
virginica
'''
最终得到预测结果是virginica种鸢尾花
分类精确度
分离数据
手动分离
数据集里包含了所有的数据,然而在实际使用时往往不能全部使用,需要分离出一部分用于测试,看看我们得到的模型的效果如何。
以鸢尾花为例,首先先看一下鸢尾花数据集的target
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
可以发现是十分规整的,所以这里需要事先对其进行打乱,然后分离出所需要的测试数据。
首先先生成一个下标的排列,然后使用shuffle打乱
iris = datasets.load_iris()
shuffle_indexes = np.arange(0, len(iris['target']))
np.random.shuffle(shuffle_indexes)
然后根据打乱的下标,取出一部分作为测试数据,比如这里取出20个,剩下的用于训练
iris = datasets.load_iris()
shuffle_indexes = np.arange(0, len(iris['target']))
np.random.shuffle(shuffle_indexes)
X_test = iris['data'][shuffle_indexes[:20]]
X_tarin = iris['data'][shuffle_indexes[20:]]
y_test = iris['target'][shuffle_indexes[:20]]
y_train = iris['target'][shuffle_indexes[20:]]
使用sklearn分离
使用sklearn的train_test_split方法可以自动帮忙分离训练数据和测试数据,其种test_size参数用于设置训练集占比
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], test_size=0.2)
精确度
这里可以使用一种很简单的方法进行度量分类的精确度
首先先把进行创建实例和进行拟合,并传入测试数据
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], test_size=0.2)
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(X_train, y_train)
results = knn_classifier.predict(X_test)
然后把预测标签和真实的标签进行对比并统计正确的数目。
最后用正确数目比上总的数目就可以得到一个精确度
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], test_size=0.2)
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(X_train, y_train)
results = knn_classifier.predict(X_test)
accuracy = np.sum(results == y_test) / len(y_test)
print(accuracy)
'''
0.9666666666666667
'''
KNN的超参数
k
超参数就在算法开始学习之前就设置好的参数。
比如在KNN算法之中最明显的超参数就是k,选取不同的k得到的精确度肯定是有一定差异的。
对于k的选取,一方面可以根据经验来判断,但是经验不一定在任何地方都适用。
所以很容易就可以想到一种简单的方法来寻找更好的k。
只需要每次枚举k,然后计算精确度,然后获取最大值就可以了。
weights
当时用KNN算法时,根据的是距离预测数据的最近的k个数的投票数目,但是在这k个之中有的点或许离新增数据比较远,有的比较近,显然是不能都用一票统计。此时就需要对k个点中的每个点都加以权值,然后进行统计选择。
可以对k个点的每个点到新增数据的距离取倒数当做权值,这样距离越远权值越小,越近权值越大可以很好的表述权重。
p
对于距离,上面计算时一直使用的是欧式距离,即直线距离。
( ∑ j = 1 n ( X j i − y j ) 2 ) 1 2 (\sum\limits_{j = 1}^n(X_j^i - y_j)^2)^{\frac{1}{2}} (j=1∑n(Xji−yj)2)21
还有一种距离叫做曼哈顿距离,他的表示形式是
( ∑ j = 1 n ∣ X j i − y j ∣ 1 ) 1 (\sum\limits_{j = 1}^n|X_j^i - y_j|^1)^{1} (j=1∑n∣Xji−yj∣1)1
可以发现他们的表达形式十分相似,由此既可以进行推广得到明可夫斯基距离
( ∑ j = 1 n ∣ X j i − y j ∣ p ) 1 p (\sum\limits_{j = 1}^n|X_j^i - y_j|^p)^{\frac{1}{p}} (j=1∑n∣Xji−yj∣p)p1
在权重和距离相关时,使用不同的距离显然也会对结果造成影响,所以使用不同的p得到的距离也会影响精确度
Grid search
sklearn中支持网格搜索来进行对超参数的搜索
先导入GridSearchCV
from sklearn.model_selection import GridSearchCV
然后在一个列表中写好要搜索的参数
比如:
parameter_grid = [
{
"weights": ['uniform'],
'n_neighbors': [i for i in range(1, 10)]},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 10)],
'p': [i for i in range(1, 8)]}
]
每个一个字典里是一个独立的搜索,然后里面填写相应的参数,参数对应的是列表,里面写要搜索的具体种类。
然后就可以创建一个KNN分类器和GridSearchCV把参数和分类器都穿给GridSearchCV,创建一个GridSearchCV实例,后面的n_jobs表示搜索时开启的核数,传入-1表示最大
digit = datasets.load_digits()
knn_classifier = KNeighborsClassifier()
X_train, X_test, y_train, y_test = train_test_split(digit.data, digit.target, test_size=0.2)
parameter_grid = [
{
"weights": ['uniform'],
'n_neighbors': [i for i in range(1, 10)]},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 10)],
'p': [i for i in range(1, 8)]}
]
grid_search = GridSearchCV(knn_classifier, parameter_grid, n_jobs=-1)
最后传入训练数据进行拟合,结束后打印best_estimator_就可以查看最佳的参数,打印best_score_就可以查看
digit = datasets.load_digits()
knn_classifier = KNeighborsClassifier()
X_train, X_test, y_train, y_test = train_test_split(digit.data, digit.target, test_size=0.2)
parameter_grid = [
{
"weights": ['uniform'],
'n_neighbors': [i for i in range(1, 10)]},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 10)],
'p': [i for i in range(1, 8)]}
]
grid_search = GridSearchCV(knn_classifier, parameter_grid, n_jobs=4)
grid_search.fit(X_train, y_train)
print(grid_search.best_estimator_)
'''
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
'''
数据归一化
在KNN算法中,距离是一个很重要的度量,但是在使用距离来描述样本与预测数据的关系时可能会发生一些问题,比如
特征:长度,角度(弧度制)
样本一:180, 2.18
样本二:160, 1.23
在这么一组数据中可以明显发现,在计算距离时长度占了大头,也就是说数据容易受到长度这个特征的影响,而不容易受到角度的影响,所以需要对数据进行一定的映射,使其在同一个尺度上,这就是数据归一化。
最值归一化
最值归一化即使利中特征中的最大最小值使用归一化即:
x = x − x m i n x m a x − x m i n x = \frac{x-x_{min}}{x_{max} - x_{min}} x=xmax−xminx−xmin
实际上就是把最大值与最小值的差看成一个区间,然后计算每个数在此区间上的长度比,最终把所有数据映射到0到1之间。
这种做法的优点就是简单明了,但是缺点就是容易受极值的影响,而且适用于有明显边界的数据。
均值归一化
均值归一化利用数据的均值和方差对数据进行处理
x = x − x m e a n s x = \frac{x - x_{mean}}{s} x=sx−xmean
均值归一化不能把数据映射到0到1之间,但是可以让数据的方差变为1,均值变为0。
均值归一化适用于所有的数据。
测试数据与训练数据的归一化
在归一化时,有测试数据和训练数据,测试数据汇算出来一个方差和平均值,而测试数据也会计算出一个,此时就需要注意,对于测试数据进行归一化时,应该使用训练数据的方差和平均值,而不是自身的。
原因很简单,因为当新来一个数据预测数据时往往无法计算方差和平均值。
sklearn封装了归一化的方法。
先导入StandardScaler
from sklearn.preprocessing import StandardScaler
然后拆分数据
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
创建StandardScaler实例,然后用训练数据去拟合
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
standarscaler = StandardScaler()
standarscaler.fit(X_train)
然后就可以进行归一化了
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
standarscaler = StandardScaler()
standarscaler.fit(X_train)
X_train = standarscaler.transform(X_train)
X_test = standarscaler.transform(X_test)