KNN(K-Nearest Neighbor)最邻近规则分类
算法思想:计算待分类样本点到K个离其最近已知类别样本点的距离,其类别属于这K个样本中占主导的部分
(少数服从多数),故此算法的核心就是计算待测点与K个已知样本点的距离。这里的距离可以是指欧式距离,也可以
使用其他的距离衡量,比如余弦距离、相关度、曼哈顿距离等;

在这里K的选取为奇数(不会产生歧义)一定会分别出类别。(K的选取不同可能会使待归类点属于分属于不同的类别)

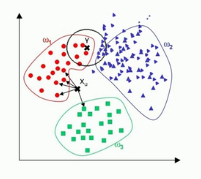
如上图所示K取1的时候,待归类样本点(红色点)归类到1类别中,但当K取5的时候则归类到2类别中。
KNN算法缺点:1、KNN算法的时间负责度较高(需要比较所有已知样本与待分类样本)复杂度约为两者的乘积;
2、当样本分布不均时,会使得归类产生误差。待归类样本容易受主导样本点的影响;
如上图所示K的范围覆盖为黑色区域,但由于蓝色样本点密集红色样本点系数,蓝色样本点占主导则把待归类样本“X”,归为
蓝色类别,但在实际情况下归为红色类别较好。
KNN算法实战(fight)所用数据集为逻辑回归的数据集合(图中黑色X为待检测样本点坐标为【0.195.0.19】)

KNN算法实现代码(不通用,仅限于理解此算法)
import numpy as np
from matplotlib import pyplot as plt
import random
dataSet=[]
point=np.array([0.195,0.19])#待归类点
with open('DataSet') as f:
for line in f:
line=line.strip('\n').split(' ')
if(line[2]=='0'):
line[2]='-1'
dataSet.append([float(line[0]),float(line[1]),int(line[2])])
data=np.array(dataSet)#学习集
#KNN算法
dataall=[]
belongclass=[]
for i in data:
dataall.append([i[0],i[1]])
belongclass.append(i[2])
dataall=np.array(dataall)
copypoint=np.tile(point,(dataall.shape[0],1))
d=np.sqrt(np.sum(np.power(dataall-copypoint,2),axis=1))
d=np.argsort(d)#求解欧式距离
K=5
Belong={}
for i in range(K):
vote=belongclass[d[i]]
Belong.update({vote:Belong.get(vote,0)+1})#少数服从多数
if(max(Belong,key=Belong.get)==1):
print('蓝色')
else:
print('红色')
print()#1是蓝色,-1为红色,样本点归类
for i in data:
if(i[2]==1):
plt.scatter(i[0],i[1],c='b')
else:
plt.scatter(i[0], i[1],c='r')
plt.plot(point[0],point[1],'X',c='black')
plt.show() 运行结果: 分类效果还可以,样本数据够多且样本分布均匀时分类效果较好。
分类效果还可以,样本数据够多且样本分布均匀时分类效果较好。
KNN算法伪代码:
S1=样本点集合 #m个
S2=待归类点集合 #n个
K=选取临近样本点的个数 #int类型,且最好为奇数
计算S2中所有的点到S1已知样本点的距离;#时间复杂度为O(mn)
对于每一个S2中的待分类点执行下述操作
for i in range(K):#选取K个到待归类点距离相对较近的样本点
统计其类别种类及其所占权重
#时间复杂度为O(Kn) #线性时间复杂度
输出权值较大的类别作为该待归类点的类别。