KNN 算法原理
K-近邻算法(KNN)通过测量 特征值之间的距离 进行分类。
比如有一个训练集,且训练集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)数据的分类标签。一般选择样本数据集中前 k 个最相似的数据,k 为不大于 20 的整数。
最后,选择这 k 个最相似数据中出现次数最多的分类,作为新数据的分类标签。
KNN 的优缺点
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
KNN 算法实现
KNN 算法的一般流程
(1)收集数据:可以使用任何方法;
(2)准备数据:计算距离所需要的数值,最好是结构化的数据格式;
(3)分析数据:可以使用任何方法;
(4)训练算法:不需要
(5)测试算法:计算错误率
(6)使用算法:首先需要输入样本数据(特征)和结构化的输出结果(标签),然后运行 KNN 算法判定输入数据分别属于哪个分类,最后应用由计算得出的分类结果执行后续的处理。
KNN 算法伪代码
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增的次序排序;
(3)选取与当前点距离最小的 k 个点
(4)确定前 k 个点所在类别的出现频率
(5)返回前 k 个点出现频率最高的类别作为当前点的预测分类
KNN 算法代码实现
1. 准备工作:使用python导入数据
创建名为 KNN.py 的 python 文件,首先在该模块中定义一个产生数据集(包括特征和标签)的函数。
from numpy import *
import operator
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
- numpy 是科学计算包;
- operator 是运算符模块,KNN 在执行排序操作时将使用 operator 模块提供的函数;
2. 准备工作:验证第 1 步导入数据是否正常
从终端进入 KNN 文件所在目录,执行 python 解释器程序,导入刚才的 KNN 模块,检查是否能向 group 和 labels 正常赋值。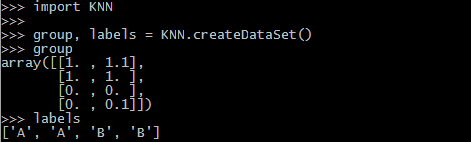
- label 包含的元素个数 = group 矩阵行数(矩阵说法不太准确,应该是多维数组,不过按矩阵理解更简单)
3. 从文本文件中解析数据
在 KNN.py 中添加 KNN 算法代码:代码解析见下面的说明
def classify0(inX, dataSet, labels, k):
# 计算距离
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# 为距离进行升序排序
sortedDistIndicies = distances.argsort()
# 选出前 k 个样本的标签并统计出现的次数
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
- classify0() 函数有 4 个输入参数:① 需要被分类的测试样本 inX(只有特征,没有标签),② 训练样本特征矩阵 dataSet,③ 训练样本标签向量 labels,④ 选择最近邻的数目 k 。
- 首先获取样本数据集特征矩阵的行数(dataSet.shape[0]),即有多少个样本,因为后面要计算测试样本的各个特征与每个样本的对应特征的差值。这里 .shape[0] 获取矩阵行数。详细用法见 shape 函数用法
- tile() 的作用是重复某个数组,比如 tile( A,n) 是将数组 A 重复 n 次,这里 n 可以是元组,(inX, (dataSetSize, 1)) 就是将数组 inX 在行方向上重复 dataSetSize 次,列方向上重复一次(即不重复),接着就可以将两个矩阵进行相减运算。详细用法见 tile 函数用法
- 样本点间的距离计算采用欧式距离 ,计算两个向量点 xA 和 xB 之间的距离:
例如:点 (1, 0, 0, 1) 和 (7, 6, 9, 4) 之间的距离计算为:
所以接下来的三行代码都是在计算两个样本点之间的欧式距离:平方、求和并开根号。注意这里 sum 函数有一个参数 axis=1,意思是将矩阵按行相加。详细用法见 sum 函数用法 - 测试样本和各个样本点之间的距离计算出来以后,就要对距离进行排序,这里用 .argsort() 函数数组中的元素从小到大排列,并返回其对应的 index (索引)序列。详细用法见 argsort 函数用法
- 定义一个字典 classCount,目的是记录标签出现的次数。在前面对距离排好序以后,我们每次拿出一个最小的距离,就要去找到它对应的样本标签。那么怎么才能对某个标签出现的次数做一个统计呢?所以用字典类型就可以将标签和它出现的次数对应起来,也方便后面进行查询。字典中 key 就是标签名,对应的 value 就是它在 k 次选取中出现的次数。
- 进入 for 循环就是执行 k 次选取啦,k 是人为选取的,voteIlabel 每次都可以获得一个当前距离最小的样本标签,然后对该标签出现的次数进行统计并存放在字典 classCount 中,那么 get 方法就可以对它进行计数,注意由于第一次查找键值 voteIlabel 所对应的值是不存在的,所以设置一个默认值 0 。get() 的具体使用方法见 get 函数的用法
- 做完 k 次选取统计后,再对字典 classCount 进行排序,这里 items() 以列表形式返回字典中的键值对,排序规则 key 为按照键值对第1个域(即键值对的“值”)进行降序排序。sorted 函数用法,items 函数用法,operator.itemgetter 函数用法
- 最后返回排序结果的第一个键值对的 “键”,即出现次数最多的标签值。
4. 执行 KNN 算法
调用写好的 KNN 算法,在终端 python 提示符中输入命令执行 KNN 对测试数据 [0, 0] 进行分类,分类结果为 ‘B’。也可以改变输入 [0, 0] 为其他值,测试程序的运行结果。
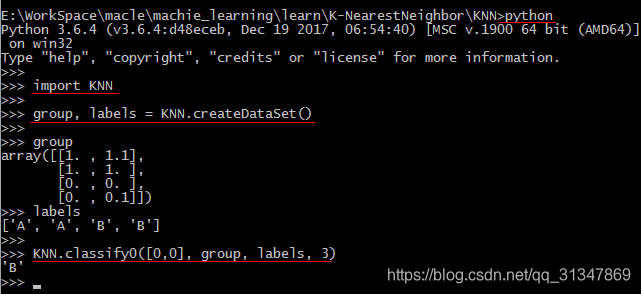
KNN 算法代码运行细节
算法本身比较简单,但我还是用上面具体的例子一步步地运行下来,方便我们看到在算法内部数据是如何变化的,帮助理解每一句代码的作用以及为什么要这么做。
1. 首先创建数据集
此时 group 和 labels 都被赋予了对应的值,可以看到 group 是 numpy.ndarray 类型,labels 是 list 类型。
group = {ndarray} [[1. 1.1]\n [1. 1. ]\n [0. 0. ]\n [0. 0.1]]
labels = {list} <class 'list'>: ['A', 'A', 'B', 'B']
- ndarray 是一个多维的数组对象,和 list 的区别参见【小记】python 中 array 和 list 的区别
2. 传入 KNN 算法所需参数
此时调用 classify0(inX, dataSet, labels, 3),得到如下结果:
dataSet = {ndarray} [[1. 1.1]\n [1. 1. ]\n [0. 0. ]\n [0. 0.1]]
inX = {list} <class 'list'>: [0, 0]
k = {int} 3
labels = {list} <class 'list'>: ['A', 'A', 'B', 'B']
3. 得到数据集特征矩阵的行数,也就是.shape[0] 的作用
dataSetSize = {int} 4
4. 计算测试样本和各样本之间的欧式距离
diffMat = {ndarray} [[-1. -1.1]\n [-1. -1. ]\n [ 0. 0. ]\n [ 0. -0.1]]
sqDiffMat = {ndarray} [[1. 1.21]\n [1. 1. ]\n [0. 0. ]\n [0. 0.01]]
sqDistances = {ndarray} [2.21 2. 0. 0.01]
distances = {ndarray} [1.48660687 1.41421356 0. 0.1 ]
5. 对距离进行排序
sortedDistIndicies = {ndarray} [2 3 1 0]
注意:这里返回的是排序后各个值的索引
6. 定义一个字典
classCount = {dict} {}
可以看到 classCount的类型是 dict
7. 进入for循环统计前 3 个距离最近的样本的标签出现次数
i = {int} 0
voteIlabel = {str} 'B'
classCount = {dict} {'B': 1}
i = {int} 1
voteIlabel = {str} 'B'
classCount = {dict} {'B': 2}
i = {int} 2
voteIlabel = {str} 'A'
classCount = {dict} {'B': 2, 'A': 1}
8. 按照标签出现的次数,对标签进行降序排序
sortedClassCount = {list} <class 'list'>: [('B', 2), ('A', 1)]
9. 输出结果
result = {str} 'B'
以上就是 KNN 算法的简单实现,接下来还可以落实到具体的应用问题中。本文作者尽力做到详尽,只是水平有限,还需要继续学习,如果有不对的地方感谢指正。