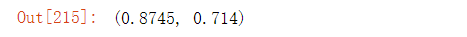数据及代码下载:
https://github.com/w1449550206/Word-cloud-production-based-on-Naive-Bayes.git
#词云 词云中不要出现太多的词语
import numpy as np
import pandas as pd
import jieba as jb
#文本中本来是没有特征 词数统计
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import warnings
warnings.filterwarnings('ignore')
df_news = pd.read_table('./data/val.txt',header=None,names=['labels','title','url','content'])

df_news.info()

df_news.head().content

抽取数据
#进行分类的文本在content当中
contents = []
content = df_news.content
for line in content:
arr = np.array(jb.lcut(line))
new_arr = []
#空文本
if len(arr) > 0:
#有没有空字符串,有可能
for a in arr:
#把单个字过滤掉
if len(a) > 1:
new_arr.append(a)
contents.append(new_arr)
contents = np.array(contents)
contents[:10]

#停用词就是常用的对数据分类没有帮助的词语,在每一种类型的文章中大概率都会出现
#/n C中 =\n
stopwords = pd.read_table('./data/stopwords.txt',sep='/n',header=None,names=['word'],encoding='utf8')
swList = stopwords.word.tolist()
content_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
#如果词语不在垃圾词库中,说明它是有用的特征
if word not in swList:
#分类
line_clean.append(word)
#用来做词云
all_words.append(word)
content_clean.append(line_clean)
#计算每种词语的出现次数 all_words groupby().count()
df_all_words = pd.DataFrame({'all_words':all_words})
words_count = df_all_words.groupby('all_words').all_words.agg({"count":np.size})
#词语需要的是dict类型,不忍dataframe
#all_words 当作key count 作为 value
word_dict = words_count.sort_values('count',ascending=False).iloc[:100].to_dict()['count']
w = words_count.sort_values('count',ascending=False).reset_index()
w_dict = {x[0]:x[1] for x in w.values}
准备词云库
from wordcloud import WordCloud #pip install wordcloud -i https://pypi.douban.com/simple
import matplotlib.pyplot as plt
from PIL import Image
- font_path 使用什么字体,字体的路径
- width 图片的宽度
- height 图片的高度
- min_font_size 最小字体的px
- max_font_size 最大字体的px
- background_color 图片的背景颜色
- mask 生产词云的背景轮廓图片
bg = np.array(Image.open('./data/bg.png'))
#进行实例化
wc_model = WordCloud(font_path='./data/simhei.ttf',max_font_size=180,mask=bg,mode='RGBA')
w=' '.join(word_dict.keys())
#把字典数据填入到模型当中
wc_model.fit_words(word_dict)

plt.figure(figsize=(12,8))
plt.imshow(wc_model)
plt.axis('off')
#用户画像喜欢用

LDA主题模型
from gensim import corpora,models,similarities #语料库,词袋模型
import gensim#pip install gensim -i https://pypi.douban.com/simple
content_clean[:2]

#语料字典
dictionary = corpora.Dictionary(content_clean)
#语料字典 -> 稀疏矩阵
corpus = [dictionary.doc2bow(x) for x in content_clean]
#词袋模型
#corpus 记录行中每个词语出现过了多少次,词语用索引代替了
#id2word 词语本身
#num_topics 类别的数量
lda = models.ldamodel.LdaModel(corpus=corpus,id2word=dictionary,num_topics=10)
#输出主题 25000+
#查看第5个主题(类别)
#topn 显示的特征数量
lda.print_topic(5,topn=20)

lda.print_topics(num_topics=5,num_words=10)

分类
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
from sklearn.metrics import classification_report #分类类型评估
#获取特征
data = []
for i in range(len(content_clean)):
data.append(' '.join(content_clean[i]))
data = np.array(data)
target = df_news.labels
#进行文本向量化
tfidf = TfidfVectorizer()
sparse_matrix = tfidf.fit_transform(data)
#获取特征
tfidf.get_feature_names()

# 是一种数据类型
sparse_matrix

X_train,X_test,y_train,y_test = train_test_split(sparse_matrix,target,test_size=1000)
GB = GaussaianNB().fit(X_train.toarray(),y_train)
GB.score(X_train.toarray(),y_train),GB.score(X_test.toarray(),y_test)

MNB = MultinomialNB().fit(X_train,y_train)
MNB.score(X_train,y_train),MNB.score(X_test,y_test)
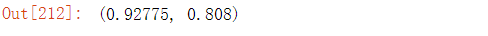
target.unique()

BNB = BernoulliNB().fit(X_train,y_train)
BNB.score(X_train,y_train),BNB.score(X_test,y_test)