机器学习算法很多,常见的有朴素贝叶斯,逻辑回归,决策树,等等今天让我们开启对朴素贝叶斯的认识。。。
分类技术认识:
定义:给定一个对象X,将其划分为到预定义好的某一个类别Yi中。
-输入 : X
-输出: Y (取值于有限集合{y1,y2,y3....yn})
应用:邮件是否垃圾,病人分类,点击是否有效等等。
通俗理解:
这里输入对象是一篇文章X,那么到底是军事还是财经就是Y。
常见的分类有二值分类(男女)和多值分类(文章分类{政治,体育,科幻})
分类任务解决流程:

新闻分类
一:特征分类:X = {昨日,是,市场...} 【特征分类的前提是进行中文分词】
二:特征选择:X ={国内,国外...} 【对中文分词后的结果进行关键词提取】。
三:模型选择:朴素贝叶斯分类器【选择分类模型】
四:训练数据准备:
五:模型训练:
六:预测(分类):
七:评测:得到评测效果
常见分类技术:
--概率选择器
--NB
--计算待选择的对象属于每个类别的概率,选择概率最大的类别作为输出
--空间分割
--SVM :支持向量机 如下图: 缺点不适合样本量过大

上图有四种不同样本的类别,在空间上进行打点,经过学习得到一些线条,比如蓝色的部分,通过几条线,可以很清楚的把不同的样本分割开了,这就相当于在一个二维空间里,划线将样本进行分割,这样的算法就是空间分割类的算法,SVM就是这样的。
前面说了很多现在进入今天的正题,学习常见的分类算法朴素贝叶斯分类器。
三 朴素贝叶斯分类器:
公式:
P(yi|X)=P(yi)P(X|yi)/P(X)
公式进行拆解过程:
yi是指某一个分类
Y={军事、财经、体育}
X=一篇文章
xi=文章中具体某一个词
P(yi|X):给定一篇文章,属于某一个类别的概率值
P(yi):先验概率
给大家100篇文章,其中50篇是军事、30篇财经、20篇体育
P(y=军事) = 50/100
P(y=财经) = 30/100
P(y=体育) = 20/100
P(X):这篇文章的概率=是一个固定值,可以忽略掉 ,一定会出现该文章概率为1。
因此:P(yi|X)=P(yi)P(X|yi)/P(X)
可以进一步简写为:P(yi|X)≈ P(yi)P(X|yi)
P(X|yi):对于y指定的类别中,出现X的概率
P(xi|yi):对于y指定的类别中,出现x这个词的概率
y=军事,x=军舰 军事这个类别一共有多少个词,其中出现军舰的次数是多少 就是军事文章中出现军舰的概率。
X={军舰、大炮、航母}
P(X|y=军事) = P(x=军舰|y=军事)*P(x=大炮|y=军事)*P(x=航母|y=军事)
前提:独立同分布=》朴素贝叶斯【复杂问题简单化】
P(yi|X)≈ P(yi)P(X|yi) ==最终朴素贝叶斯
对每一个标签都求对应概率,最大者为该分类。
朴素贝叶斯推导过程:
朴素贝叶斯公式可以由条件概率公式推导而来,下面是推导的具体过程:
1.P(X|Y) = P(X,Y)/P(Y)
2.P(X,Y)=P(X|Y)*P(Y)
3.P(X,Y)=P(Y,X)
4.P(Y,X)=P(Y|X)*P(X)
5.P(X,Y)=P(Y|X)*P(X)
将5中P(X,Y)带入1得6:
6.P(X|Y) = P(Y|X)*P(X)/P(Y)
最终朴素贝叶斯公式:
P(yi|X)=P(yi)P(X|yi)/P(X)
五:【模型训练和参数估计】
实现模型训练和参数估计采用的策略是:最大似然估计
最大似然估计:通过离线的行为,将背后的概率进行呈现,包含的特点,训练数据量越大得到的参数越准确,
越接近于真实。训练数据太少,其中一个文章的标签打错啦,就是噪音,容易被干扰。
条件概率公式:
P(xj|yi) = P(xj,yi)/p(yi)
P(xj|yi) 计算不好直接计算进而转变为最大似然估计来解决:
为了完成NB分类问题,我们需要2类参数来支持
1、先验概率P(yi)
2、条件概率P(X|yi)
参数需要计算出来的,在这里参数就是模型
先验概率:
p(yi)计算方法一模一样
条件概率:
分子:军事类文章中包含“谷歌”这个词的个数
分母:军事类文章中所有词的个数
p(x="谷歌"|y="军事"):分子 / 分母
P(xj|yi) 有2种方法:
第一种都是文章的个数,第二种都是词的个数
第一种:
分子:军事类文章中包含“谷歌”这个词的文章个数
分母:军事类文章个数
p(x="谷歌"|y="军事"):分子 / 分母
第二种:推荐使用这种方式
分子:军事类文章中包含“谷歌”这个词的个数
分母:军事类文章中所有词的个数
p(x="谷歌"|y="军事"):分子 / 分母
通过朴素贝叶斯得到一堆模型,这个模型效果很好,模型的本质就是一堆概率。
七 模型评估评测问题
需要使用混淆矩阵(或者混淆表)对效果做评测:
一般评估正样本,混淆表只能对于二分类进行评测,若是多分类只能指定一个类别,其余的就是其他类别 。
是以模型的角度为主:
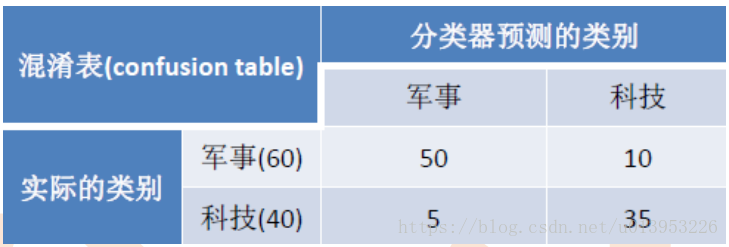
准确度Accuracy: (50+35)/(35+5+10+50) 【预测正确样本个数除以总个数】
精确率Precision(y1):50/(50+5)=90.9%
召回率Recall(y1):50/(50+10)=83.3%
精确率:一开始不知道文章的label,模型我从100文章中预测了55是军事,但是其中只有50是军事,模型的精确率就是 50/55 。
召回率:就是有60篇是军事,模型判断出来了50,但是有10篇文章没被模型判断出来, 若是模型校验的话就存在10片文章丢失的情况,丢失的文章就是损失。
推荐系统里面:100高质量的物品,其中只有90个进入了候选队列,还有10个处于流离失所状态,没有被召回
在实际的应用中阶段性不一样最要求不一样在:推荐系统在NoSQL索引库中侧重于召回率,在排序模型中侧重于精确率。
通过正确率,召回率,可以得到一个PR曲线【P:正确率 R:召回率】,PR曲线一般是准确率高,召回率低,召回率高,准确率低。
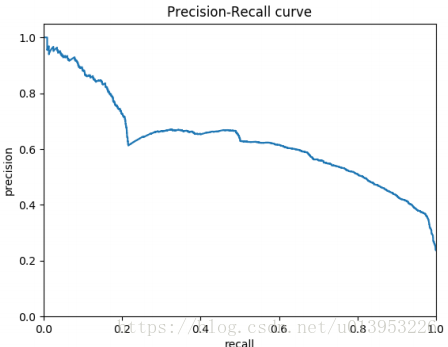
PR曲线是个评测指标,用来协助你去选择阀值的,那么我们看下ROC曲线的评测指标

纵轴:真阳率,召回率,TP/(TP+FN) 横轴:假阳率FP/(FP+FN)
那么ROC曲线有什么用,其实ROC曲线是为了得到AUC曲线,即ROC曲线下的面积


得到ROC不是真正的目的,最终为了得到AUC,AUC就是ROC曲线下的面积。
AUC的面积就是1,所以ROC曲线下面的面积一定是0-1之间的小数。
ROC曲线的意义就是为了得到AUC。
但是这样的计算太麻烦。
另一种理解AUC的方法:负样本排在正样本前面的概率。通过awk方式来解决:
cat auc.raw | sort -t$'\t' -k2g |awk -F'\t' '($1==-1){++x;a+=y;}($1==1){++y;}END{print 1.0-a/(x*y);}'
x*y是正负样本pair对
a代表错误的个数
a/x*y 错误的概率
1-a/x*y 正确概率
举例1:
A 0.1 B 0.9
:假设:任何两个样本之间打分,都应该按照顺序去排序,若是按照这样的顺序排列了,就是正确的,排反了,否则就是错误的
(A,B)正确
(B,A)错误
若是所有的负样本全部排在正样本前面,则AUC就是100%
若模型打的分比较小,模型认为该样本为负例,若是真负例,就应该排在前面的概率才对。

举例2:
军事 +1 +1代表军事
财经 -1 -1代表财经
1.来了一个样本是真实标签:军事题材【+1】的文章,然后用模型对其打分,
2.通过模型对文章进行预测,预测的时候会打分,为预测分数
3.通过预测分数预测数预测标签是:军事
4.预测和真实的都是军事说明模型预测成功了
5.若预测为财经,则说明该模型打错啦
6.真实标签为+1 ,预测标签为-1
7.模型给你文章打分,分数越高就趋近于+1 否则趋近于-1 ,因此有一个阈值大于某一个之上才是正例,否则就是负例。
8.所以通过阈值控制预测标签,阈值就是人工设定的。 若默认为0 所有模型对文章打的分数大于0为正例,小于等于0为负例。
按理说模型预测正确,前面是-1的概率很大,
完美情况下,模型预测全部正确的话,前面全部是-1,后面全部是+1
举例2:
证明概率不会大于1:
100个样本
极端情况下:前面有50个+1,后面有50个-1
一共:50*50=2500 pair对
y=50
x=50
a=50*50=2500
最终:1-a/(x*y) 概率为0,即最差情况下AUC为0 ,但是一般AUC最差结果为0.5【此时的AUC没有任何的区分能力】
AUC只对二分类:多个类别,只有对每一个类别分别做一个AUC。