6.3 朴素贝叶斯估计
6.3 朴素贝叶斯估计
- 基于第一章 的
贝叶斯准则,将条件风险转化为了先验概率和似然。 - 又基于第二章
极大似然估计获得了通过优化似然函数得到极大似然估计的方法。 - 采用“属性条件独立性假设”:假设每个属性独立地对分类结果发生影响。
6.3.1 原理
朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
基于贝叶斯公式来估计后验概率 P ( c ∣ x ) P(c|x) P(c∣x)的主要困难在于:类条件概率 P ( x ∣ c ) P(x|c) P(x∣c)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。
(基于有限训练样本直接估计联合概率,在计算上斗争会遭遇纽合爆炸问题,在数据上将会遭遇样本稀疏问题,属性数越多,问题越严重.)
为避开这个障碍,朴素贝叶斯分类器(naÏve Bayes classifier)采用了"属性条件独立性假设" (attribute conditional independence assumption): 对已知类别,假设所有属性相互独立.换言之,假设每个属性独立地对分类结果发生影响.
基于属性条件独立性假设。根据式子 P ( c ∣ x ) = P ( c ) P ( x ∣ c ) p ( x ) = P ( c ) P ( x ∣ c ) ∑ P ( c ) P ( x ∣ c ) P(c|x)=\frac{P(c)P(x|c)}{p(x)}=\frac{P(c)P(x|c)}{\sum P(c)P(x|c)} P(c∣x)=p(x)P(c)P(x∣c)=∑P(c)P(x∣c)P(c)P(x∣c)可以重写为
P ( c ∣ x ) = P ( c ) P ( x ∣ c ) p ( x ) = P ( c ) P ( x ) ∏ i = 1 d P ( x i ∣ c ) P(c|x)=\frac{P(c)P(x|c)}{p(x)}=\frac{P(c)}{P(x)}\prod_{i=1}^dP(x_i|c) P(c∣x)=p(x)P(c)P(x∣c)=P(x)P(c)i=1∏dP(xi∣c)
其中 d d d为属性数目, x i x_i xi为 x x x在第 i i i个属性上的取值。
由于对所有类别来说 P ( x ) P(x) P(x)相同,因此基于式 h ∗ ( x ) = a r g m a x c ∈ Y P ( c ∣ x ) h^*(x)=argmax_{c\in Y}P(c|x) h∗(x)=argmaxc∈YP(c∣x)的贝叶斯判定准则有
h n b ( x ) = a r g m a x c ∈ Y P ( c ) ∏ i = 1 d P ( x i ∣ c ) h_{nb}(x)=argmax_{c\in Y}P(c)\prod_{i=1}^dP(x_i|c) hnb(x)=argmaxc∈YP(c)∏i=1dP(xi∣c)
这就是朴素贝叶斯分类器的表达式。
朴素贝叶斯的训练过程就是基于训练集D来估计类先验概率P©,并为每个属性估计条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)。
离散属性
对离散属性而言,令 D c , x i D_{c,x_i} Dc,xi表示 D c D_c Dc中在第 i i i个属性上取值为 x i x_i xi的样本组成的集合,则条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)可估计为
P ( x i ∣ c ) = D c , x i D c P(x_i|c)=\frac{D_{c,x_i}}{Dc} P(xi∣c)=DcDc,xi
连续属性
对连续属性可考虑概率密度函数,假定 p ( x i ∣ c ) ∼ N ( μ c , i , σ c , i 2 ) p(x_i|c)\sim N(\mu_{c,i},\sigma_{c,i}^2) p(xi∣c)∼N(μc,i,σc,i2),其中 μ c , i \mu_{c,i} μc,i和 σ c , i 2 \sigma_{c,i}^2 σc,i2,分别是第 c c c类样本在第 i i i个属性上取值的均值和方差,则有
p ( x i ∣ c ) = 1 2 π σ c , i e x p ( − ( x i − μ c , i ) 2 2 σ c , i 2 ) p(x_i|c)=\frac{1}{\sqrt{2\pi}\sigma_{c,i}}exp(-\frac{(x_i-\mu_{c,i})^2}{2\sigma_{c,i}^2}) p(xi∣c)=2πσc,i1exp(−2σc,i2(xi−μc,i)2)
下面是别人的PPT,写的比较好。截图了下面


为了避免其他属性携带的信息被训练集中未出现的属性值"抹去’,在估计概率值时通常要进行"平滑" (smoothing) ,常用"拉普拉斯修正" (Laplacian correction)。拉普拉斯修正实质上假设了属性值与类别均匀分布。
6.3.2 具体流程
首先看数据集。
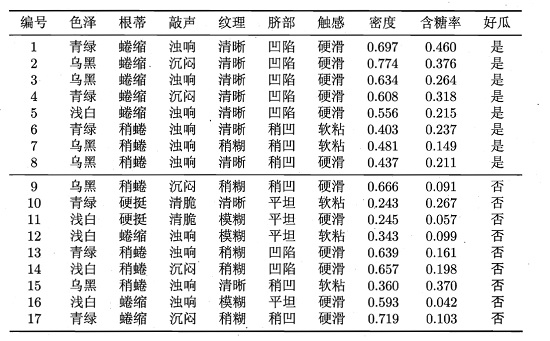
然后我们对一个测试集进行分类
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 测试1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | ? |
x x x是所有样本, x i x_i xi是每个属性, c c c是好瓜
首先我们计算出先验概率 P ( c ) P(c) P(c),显然有
P ( P( P(好瓜=是 ) = 8 17 ≈ 0.471 )=\frac{8}{17}\approx0.471 )=178≈0.471
P ( P( P(好瓜=否 ) = 9 17 ≈ 0.529 )=\frac{9}{17}\approx0.529 )=179≈0.529
对每个属性估计条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)
下面是离散值
P 青 绿 ∣ 是 = P ( 色 泽 = 青 绿 ∣ 好 瓜 = 是 ) = 3 8 = 0.375 P_{青绿|是}=P(色泽=青绿|好瓜=是)=\frac{3}{8}=0.375 P青绿∣是=P(色泽=青绿∣好瓜=是)=83=0.375
P 青 绿 ∣ 否 = P ( 色 泽 = 青 绿 ∣ 好 瓜 = 否 ) = 3 9 ≈ 0.333 P_{青绿|否}=P(色泽=青绿|好瓜=否)=\frac{3}{9}\approx0.333 P青绿∣否=P(色泽=青绿∣好瓜=否)=93≈0.333
P 蜷 缩 ∣ 是 = P ( 根 蒂 = 蜷 缩 ∣ 好 瓜 = 是 ) = 5 8 = 0.625 P_{蜷缩|是}=P(根蒂=蜷缩|好瓜=是)=\frac{5}{8}=0.625 P蜷缩∣是=P(根蒂=蜷缩∣好瓜=是)=85=0.625
P 蜷 缩 ∣ 否 = P ( 根 蒂 = 蜷 缩 ∣ 好 瓜 = 否 ) = 3 9 ≈ 0.333 P_{蜷缩|否}=P(根蒂=蜷缩|好瓜=否)=\frac{3}{9}\approx0.333 P蜷缩∣否=P(根蒂=蜷缩∣好瓜=否)=93≈0.333
P 浊 响 ∣ 是 = P ( 敲 声 = 浊 响 ∣ 好 瓜 = 是 ) = 3 8 ≈ 0.375 P_{浊响|是}=P(敲声=浊响|好瓜=是)=\frac{3}{8}\approx0.375 P浊响∣是=P(敲声=浊响∣好瓜=是)=83≈0.375
P 浊 响 ∣ 否 = P ( 敲 声 ∣ 好 瓜 = 否 ) = 4 9 ≈ 0.444 P_{浊响|否}=P(敲声|好瓜=否)=\frac{4}{9}\approx0.444 P浊响∣否=P(敲声∣好瓜=否)=94≈0.444
P 清 晰 ∣ 是 = P ( 纹 理 = 清 晰 ∣ 好 瓜 = 是 ) = 7 8 = 0.375 P_{清晰|是}=P(纹理=清晰|好瓜=是)=\frac{7}{8}=0.375 P清晰∣是=P(纹理=清晰∣好瓜=是)=87=0.375
P 清 晰 ∣ 否 = P ( 纹 理 = 清 晰 ∣ 好 瓜 = 否 ) = 2 9 ≈ 0.222 P_{清晰|否}=P(纹理=清晰|好瓜=否)=\frac{2}{9}\approx0.222 P清晰∣否=P(纹理=清晰∣好瓜=否)=92≈0.222
P 凹 陷 ∣ 是 = P ( 脐 部 = 凹 陷 ∣ 好 瓜 = 是 ) = 5 8 = 0.625 P_{凹陷|是}=P(脐部=凹陷|好瓜=是)=\frac{5}{8}=0.625 P凹陷∣是=P(脐部=凹陷∣好瓜=是)=85=0.625
P 凹 陷 ∣ 否 = P ( 脐 部 = 凹 陷 ∣ 好 瓜 = 否 ) = 2 9 ≈ 0.222 P_{凹陷|否}=P(脐部=凹陷|好瓜=否)=\frac{2}{9}\approx0.222 P凹陷∣否=P(脐部=凹陷∣好瓜=否)=92≈0.222
P 硬 滑 ∣ 是 = P ( 触 感 = 硬 滑 ∣ 好 瓜 = 是 ) = 6 8 = 0.75 P_{硬滑|是}=P(触感=硬滑|好瓜=是)=\frac{6}{8}=0.75 P硬滑∣是=P(触感=硬滑∣好瓜=是)=86=0.75
P 硬 滑 ∣ 否 = P ( 触 感 = 硬 滑 ∣ 好 瓜 = 否 ) = 6 9 ≈ 0.667 P_{硬滑|否}=P(触感=硬滑|好瓜=否)=\frac{6}{9}\approx0.667 P硬滑∣否=P(触感=硬滑∣好瓜=否)=96≈0.667
下面是连续值
p 密 度 : 0.697 ∣ 是 = p ( 密 度 = 0.697 ∣ 好 瓜 = 是 ) = 1 2 π × 0.129 e − ( 0.697 − 0.574 ) 2 2 × 0.12 9 2 ≈ 1.959 p_{密度:0.697|是}=p(密度=0.697|好瓜=是)=\frac{1}{\sqrt{2\pi}\times 0.129}e^{-\frac{(0.697-0.574)^2}{2\times 0.129^2}}\approx1.959 p密度:0.697∣是=p(密度=0.697∣好瓜=是)=2π×0.1291e−2×0.1292(0.697−0.574)2≈1.959
p 密 度 : 0.697 ∣ 否 = p ( 密 度 = 0.697 ∣ 好 瓜 = 否 ) = 1 2 π × 0.195 e − ( 0.697 − 0.496 ) 2 2 × 0.19 5 2 ≈ 1.203 p_{密度:0.697|否}=p(密度=0.697|好瓜=否)=\frac{1}{\sqrt{2\pi}\times 0.195}e^{-\frac{(0.697-0.496)^2}{2\times 0.195^2}}\approx1.203 p密度:0.697∣否=p(密度=0.697∣好瓜=否)=2π×0.1951e−2×0.1952(0.697−0.496)2≈1.203
p 含 糖 : 0.460 ∣ 是 = p ( 含 糖 = 0.460 ∣ 好 瓜 = 是 ) = 1 2 π × 0.101 e − ( 0.460 − 0.279 ) 2 2 × 0.10 1 2 ≈ 0.788 p_{含糖:0.460|是}=p(含糖=0.460|好瓜=是)=\frac{1}{\sqrt{2\pi}\times 0.101}e^{-\frac{(0.460-0.279)^2}{2\times 0.101^2}}\approx0.788 p含糖:0.460∣是=p(含糖=0.460∣好瓜=是)=2π×0.1011e−2×0.1012(0.460−0.279)2≈0.788
p 含 糖 : 0.460 ∣ 否 = p ( 含 糖 = 0.460 ∣ 好 瓜 = 是 ) = 1 2 π × 0.108 e − ( 0.460 − 0.154 ) 2 2 × 0.10 8 2 ≈ 0.066 p_{含糖:0.460|否}=p(含糖=0.460|好瓜=是)=\frac{1}{\sqrt{2\pi}\times 0.108}e^{-\frac{(0.460-0.154)^2}{2\times 0.108^2}}\approx0.066 p含糖:0.460∣否=p(含糖=0.460∣好瓜=是)=2π×0.1081e−2×0.1082(0.460−0.154)2≈0.066
于是,好瓜
P ( 好 瓜 = 是 ) × P 青 绿 ∣ 是 × P 蜷 缩 ∣ 是 × P 浊 响 ∣ 是 × P 清 晰 ∣ 是 × P 凹 陷 ∣ 是 × P 硬 滑 ∣ 是 × P 密 度 : 0.697 ∣ 是 × P 含 糖 : 0.460 ∣ 是 ≈ 0.052 P ( 好 瓜 = 否 ) × P 青 绿 ∣ 否 × P 蜷 缩 ∣ 否 × P 浊 响 ∣ 否 × P 清 晰 ∣ 否 × P 凹 陷 ∣ 否 × P 硬 滑 ∣ 否 × P 密 度 : 0.697 ∣ 否 × P 含 糖 : 0.460 ∣ 否 ≈ 6.80 × 1 0 − 5 P(好瓜=是)\times P_{青绿|是}\times P_{蜷缩|是}\times P_{浊响|是}\times P_{清晰|是}\times P_{凹陷|是}\times P_{硬滑|是}\times P_{密度:0.697|是}\times P_{含糖:0.460|是}\approx0.052 \\ P(好瓜=否)\times P_{青绿|否}\times P_{蜷缩|否}\times P_{浊响|否}\times P_{清晰|否}\times P_{凹陷|否}\times P_{硬滑|否}\times P_{密度:0.697|否}\times P_{含糖:0.460|否}\approx6.80\times 10^{-5} P(好瓜=是)×P青绿∣是×P蜷缩∣是×P浊响∣是×P清晰∣是×P凹陷∣是×P硬滑∣是×P密度:0.697∣是×P含糖:0.460∣是≈0.052P(好瓜=否)×P青绿∣否×P蜷缩∣否×P浊响∣否×P清晰∣否×P凹陷∣否×P硬滑∣否×P密度:0.697∣否×P含糖:0.460∣否≈6.80×10−5
由于 0.052 > 6.8 × 1 0 − 5 0.052>6.8\times 10^{-5} 0.052>6.8×10−5.我们判断测试1位好瓜
6.3.3 拉普拉斯修正
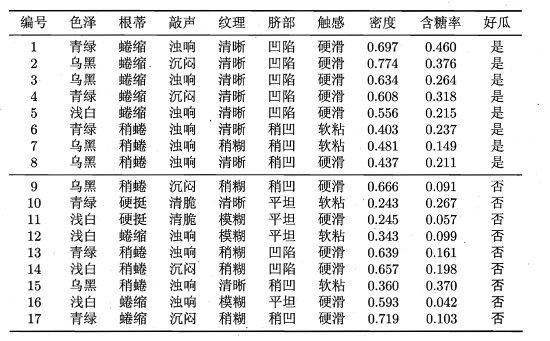
对于此数据集,对"敲声=清脆”的测试用例。
P 清 脆 ∣ 是 = P ( 敲 声 = 清 脆 ∣ 好 瓜 = 是 ) = 0 8 = 0 P_{清脆|是}=P(敲声=清脆|好瓜=是)=\frac{0}{8}=0 P清脆∣是=P(敲声=清脆∣好瓜=是)=80=0
由于连乘的公式概率值为0,不管其他分类结果如何。结果都是否。不符合常理
所以为了避免其他属性携带的信息被训练集中未出现的属性值"抹去"。常用拉普拉斯修正
令N表示训练集D中可能的类别, N i N_i Ni表示第i个属性可能的取值数。
P ^ ( c ) = ∣ D c ∣ + 1 ∣ D ∣ + N \widehat{P}(c)=\frac{|D_c|+1}{|D|+N} P (c)=∣D∣+N∣Dc∣+1
P ^ ( x i ∣ c ) = D c , x i + 1 ∣ D c ∣ + N i \widehat{P}(x_i|c)=\frac{D_{c,x_i}+1}{|D_c|+N_i} P (xi∣c)=∣Dc∣+NiDc,xi+1
所以其中类先验概率
P ^ ( 好 瓜 = 是 ) = 8 + 1 17 + 2 ≈ 0.474 , N = 2 \widehat{P}(好瓜=是)=\frac{8+1}{17+2}\approx0.474 ,N=2 P (好瓜=是)=17+28+1≈0.474,N=2,因为类别就两种,好瓜和坏瓜。类别为2
P ^ ( 清 脆 ∣ 是 ) = P ^ ( 敲 声 = 清 脆 ∣ 好 瓜 = 是 ) = 0 + 1 8 + 3 \widehat{P}(清脆|是)=\widehat{P}(敲声=清脆|好瓜=是)=\frac{0+1}{8+3} P (清脆∣是)=P (敲声=清脆∣好瓜=是)=8+30+1,因为可以取值为清脆,浊响,沉闷。取值数为3
参考资料
https://zhuanlan.zhihu.com/p/26262151
https://blog.csdn.net/weixin_39762441/article/details/111159764