贝叶斯是用来描述两个条件概率直接的关系。我知道:
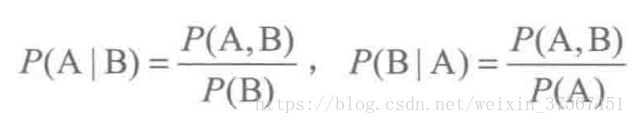
由上式进一步推导得:
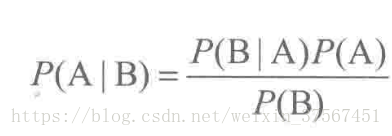
由此,推广到随机变量的范畴,设X,Y为两个随机变量,得到贝叶斯公式:
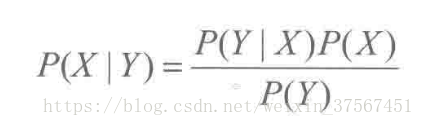
其中,P(Y)叫做先验概率,P(Y|X)叫做后验概率,P(Y,X)是联合概率。
在机器学习的视角下,我们把X理解成“具有某种特征”,把Y理解为“类别标签”,

贝叶斯方法把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率,属于监督学习。
朴素贝叶斯理论源于随机变量的独立性,之所以称之为朴素是因为其思想基础的简单性:就文本分类而言,从朴素贝叶斯的角度来看,句子中的两两词之间的关系是相互独立的,即一个对象的特征向量中的每个维度都是相互独立的。这是朴素贝叶斯理论的思想基础。在多维的情况下,朴素贝叶斯分类的表示为如下内容。
1.设x={a1,a2...am}是一个待分类项,而每个a为x的一个属性特征。
2.有类别集合C={y1,y2...yn}.
3.计算p(y1|x),p(y2|x)....p(yn|x).
4.如果p(yk|x)=max{p(y1|x),p(y2|x)....p(yn|x)}.,则x属于yk.
那么,现在的关键就是如何计算第(3)步中的各个条件概率。
1.找到一个已知分类的待分类集合,也就是训练集。
2.统计得到的各个类别下各个特征属性的条件概率估计,即
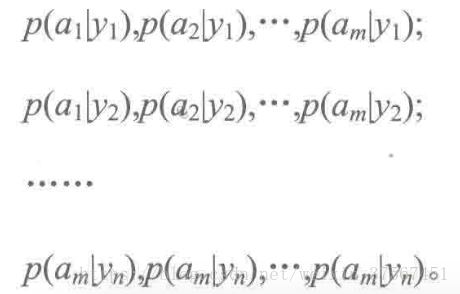
3.如果各个特征属性是条件独立的(或者假设它们之间是相互独立的),则根据贝叶斯定理有如下推导:
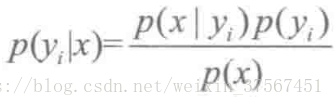
因为分母对于所有类别为常数,只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
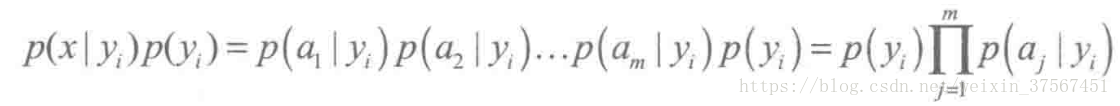
根据上述分析,朴素贝叶斯分类的流程可以表示如下:
1.训练数据生成训练样本集:TF-IDF。
2.对每个类别计算p(yi).
3.对每个特征属性计算所有划分的条件概率。
4.对每个类别计算p(x|yi)p(yi)
5.以p(x|yi)p(yi)的最大项作为x的所属类别。