贝叶斯判定准则:最小化总体风险,只需在每个样本上选择能使条件风险R(c|x)最小的类别标记
一、极大似然估计
1.估计类的常用策略:先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布的参数进行估计。即概率模型的训练过程就是参数估计过程。
2.参数估计两大学派:频率主义学派和贝叶斯学派。
(1)频率主义:参数虽然未知,但却是客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值(最大似然)。
(2)贝叶斯学派:参数是未观察到的随机变量,本身也可以有分布,因此,可假定参数服从一个先验分布,然后基于观察到的数据来计算参数的后验分布。
二、朴素贝叶斯
(1)思想:对于给定的待分类项x,通过学习到的模型计算后验概率分布,即:在此项出现的条件下各个目标类别出现的概率,将后验概率最大的类作为x所属的类别。后验概率根据贝叶斯定理计算。
(2)关键:为避免贝叶斯定理求解时面临的组合爆炸、样本稀疏问题,引入了条件独立性假设。 即假设各个特征之间相互独立
(3)工作原理:
贝叶斯公式:
![]()

对条件概率做了条件独立假设,公式为:

(4)工作流程:
1)准备阶段:确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本。
2)训练阶段:对每个类别计算在样本中的出现频率p(y),并且计算每个特征属性划分对每个类别的条件概率p(yi | x);
3)应用阶段:使用分类器进行分类,输入是分类器和待分类样本,输出是样本属于的分类类别。 采用了属性条件独立性假设,d:属性数目,xi为x在第i个属性上的取值。
四、示例
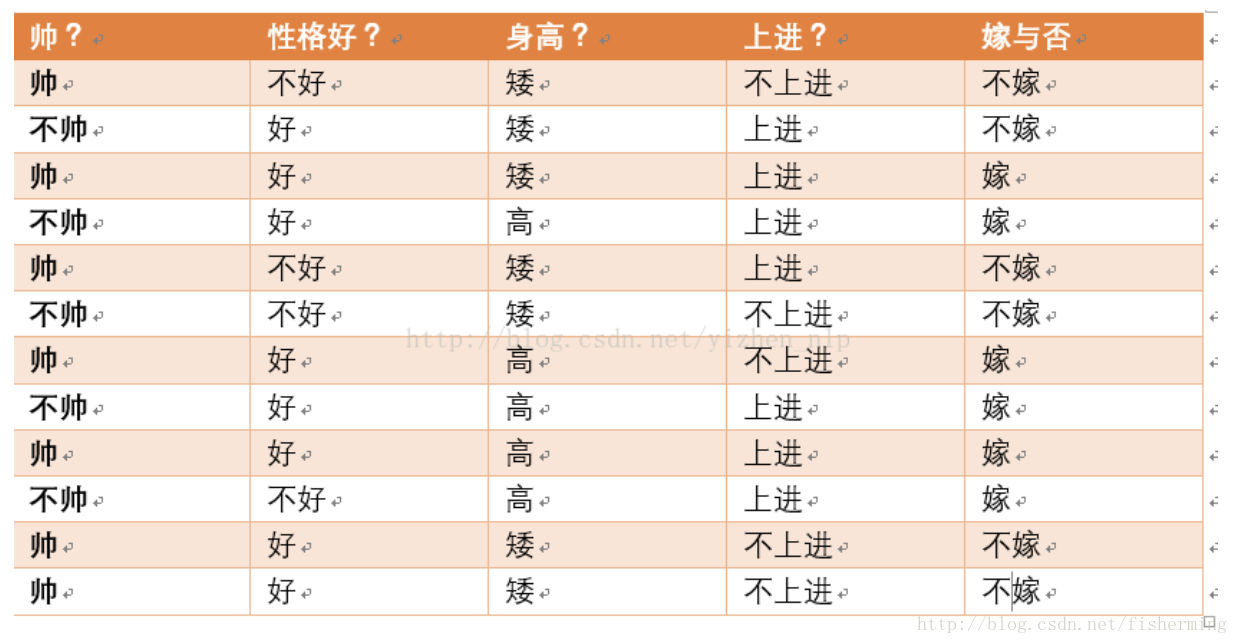
现在给我们的问题是,如果一对男女朋友,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
这是典型的二分类问题,按照朴素贝叶斯的求解,转换为P(嫁|不帅、性格不好、矮、不上进)和P(不嫁|不帅、性格不好、矮、不上进)的概率,最终选择嫁与不嫁的答案。
这里我们根据贝特斯公式:
————————————————
版权声明:本文为CSDN博主「baidu-liuming」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fisherming/article/details/79509025
五、面试内容
1、贝叶斯分类器与贝叶斯学习不同:
前者:通过最大后验概率进行单点估计;
后者:进行分布估计。
2、后验概率最大化准则意义?
<==>期望风险最小化(只需要对每一项逐个最小化)
3、朴素贝叶斯需要注意的地方?
(1)给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。 (2)计算要点:
4、经典提问:Navie Bayes和Logistic回归区别是什么?前者是生成式模型,后者是判别式模型,二者的区别就是生成式模型与判别式模型的区别。
1)首先,Navie Bayes通过已知样本求得先验概率P(Y), 及条件概率P(X|Y), 对于给定的实例,计算联合概率,进而求出后验概率。也就是说,它尝试去找到底这个数据是怎么生成的(产生的),然后再进行分类。哪个类别最有可能产生这个信号,就属于那个类别。
优点:样本容量增加时,收敛更快;隐变量存在时也可适用。
缺点:时间长;需要样本多;浪费计算资源 2)相比之下,Logistic回归不关心样本中类别的比例及类别下出现特征的概率,它直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。梯度法。
优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。
缺点:收敛慢;不适用于有隐变量的情况。