题目:E2E-MLT - an Unconstrained End-to-End method for Multi-Language Scene Text
arxiv:https://arxiv.org/abs/1801.09919
GitHub:https://github.com/MichalBusta/E2E-MLT
摘要
作者首次提出了针对多种语言的检测和识别的端到端OCR网络。
1. 简介
OCR在很多场景下很有用。同时随着全球化,多语言检测能力很重要。目前的方法存在的问题是:
- 不能处理多种语言
- 文字的定位与识别是分离的,需要多个网络完成
- 不能很好的处理有旋转,或者文字竖排的情况
目前要实现多语言检测的挑战存在于:
- 非英语的数据集数量太少
- 不同语言的特点不同,比如中文和日文中有大量的字,且常常竖排
基于此,作者提出了 E2E-MLT 的网络。
2. 相关工作
略
3. 方法
3.1 多语言数据集
已有数据集如 ICDAR 等的数量都不够,作者在此基础上主要通过在已有图像上覆盖随机生成的文字来合成新的数据集。覆盖新文字的方法有以下几个步骤
- 通过检测颜色以及纹理来确定最可能出现文字的区域(但这也会导致数据集出现一定的偏好?)
- 估计图像的深度,来获取用于渲染文字的平面
- 进行文字的渲染

3.2 整体架构
作者使用了FPN物体检测网络,用 ResNet-34 作为 E2E-MLT 网络的主干。自然场景的图像中文字一般很小,因此 ResNet-34 的第一层采用 3x3 的卷积,strides 设为 2。由于内存消耗太大,因此在原图的 1/4 分辨率上工作。
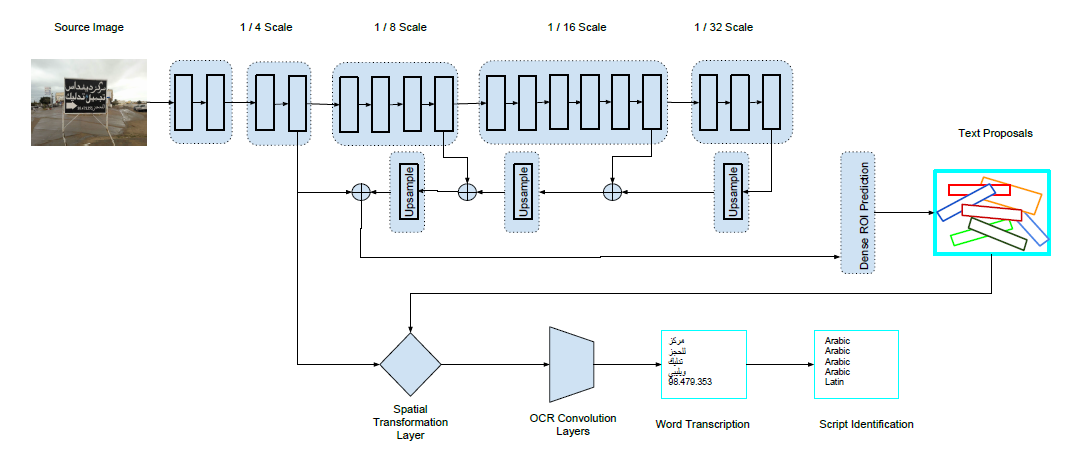
3.3 文字定位
损失函数
其中
主要是针对框的定位,
主要是针对框的角度,由于文本区域与背景存在很大的不平衡,用
消除这种不平衡,
主要是针对文字识别。
3.4 文字识别
送给OCR的是图像,而不是提取到的特征。而且送给OCR的图像是等高度,变宽度的,要经过预处理:去掉rotation,并进行warp,同时高度都被放缩为 40 个像素。
3.5 训练细节
使用 Adam 优化器,
4. 实验结果
由于ground truth错误太多,作者进行了严厉批判。
