
背景
大多数目标检测方法都是two-stage(proposal),即便是single-stage(anchor),最后往往还需要一个后处理的操作,也就是nms(non-maximum suppersion)非极大值抑制来去除预测框。避免了调参和部署困难(很多复杂的库和普通硬件不支持的算子,人工干预的先验知识)。
先前广泛使用的检测模型将detection通过
- proposal: Faster-R-CNN,mask RCNN,fpn RCNN, Cascade RCNN
- anchors base: YOLO, Focal loss
- Non anchors base: Window centers, center net, FCOS
等将几何预测任务间接转化为回归/分类任务去解决问题,也受限于postprocessing。Transformer作NLP Decoder就用自回归生成,而DETR则是直接输出结果,一是快,二是图片无须依靠顺序回归,每个bounding box结果没有相联系的关系
而于2020 ECCV上DETR这篇的里程碑式的目标检测论文将Transformer is all you need运用到了Object Detection任务上来,直接利用Transformer这种全局建模的能力,将目标检测这种局部信息看作一个集合预测的问题。同时也因此不会输出那些冗余框,端到端的输出结果。
创新点
- 实现十分简单,核心代码不超过50行就包括了模型建立,前向和推理过程。能让目标检测和图片分类一样简单,不需要冗余的各种处理和知识。
- 提出新的目标函数可以通过二分图匹配的方式生成独一无二的预测(无框)。
- 而在Transfomer Decoder中还增添额外输入(learned object queries,类似anchor)与全局图像信息结合在一起,可以做到能够让模型直接**并行一起(in parallel)**输出last 预测框
- 适用于很多复杂任务,例如全景分割,目标追踪,视频的姿态预测和语义分割
相关工作
原论文
2.1 集合预测科普
2.2 Transformer 和 parallel decoding
2.3 目标检测之前的相关工作
DETR主要的两个特点
- Set-based loss
- Recurrent detectors
之前都有工作在其他backbone上实现过,但是效果不够好,仍然较为复杂,还用了人工干预,所以归根结底还是Transformer的成功
模型详解
主体方法
下图是DETR的整个工作流程
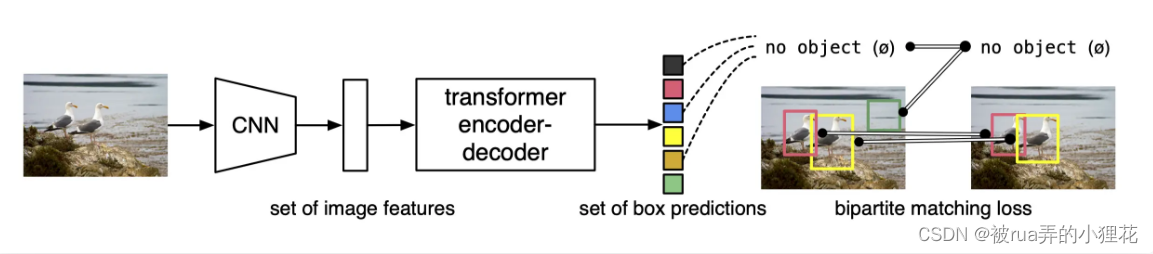
(1)先CNN抽特征,拉直后送入transformer
(2)Encoder学全局特征,大概区分物体块,使其与输出预测框一对一,而不是一对多,帮助后面做检测
(3)Decoder中会有object query限制出几个框(100),这是替代生成anchor的机制
(4)计算与ground truth框的matching loss,来决定哪几个预测框与grond truth一一对应,其余标记为背景。然后再算分类loss和bounding box loss。 二分图匹配替代nms,把不可学变成了可学。
推理的时候前三步一样,但最后一步loss不需要,用一个阈值卡一下输出的置信度(>0.7)
缺陷:在大物体上预测结果好,小物体上预测结果差,DETR训练慢,不过半年后的Deformable DETR用多尺度多特征解决了
启发:改变了训练setting,使得无法与前人方法公平对比,怎样让审稿人放过你
【1】基于集合的目标函数set prediction loss
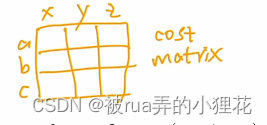
最优二分图匹配使得cost最低的最优排列(匈牙利算法),如scipy库里的linear sum assignment函数
cost martix=set prediction loss=分类loss+出框准确度
其实总的来看,和往人做法差不多,但严格限制得到一对一匹配关系
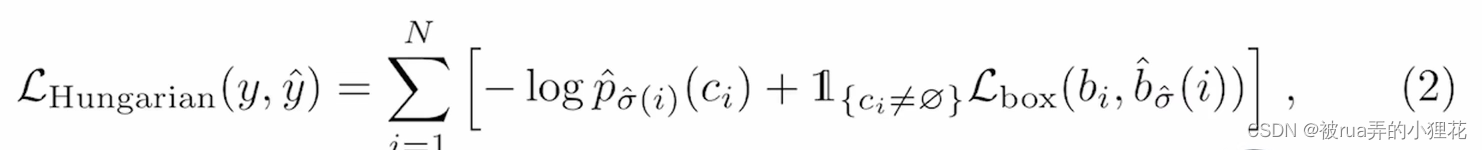
【2】具体模型架构Recurrent detectors
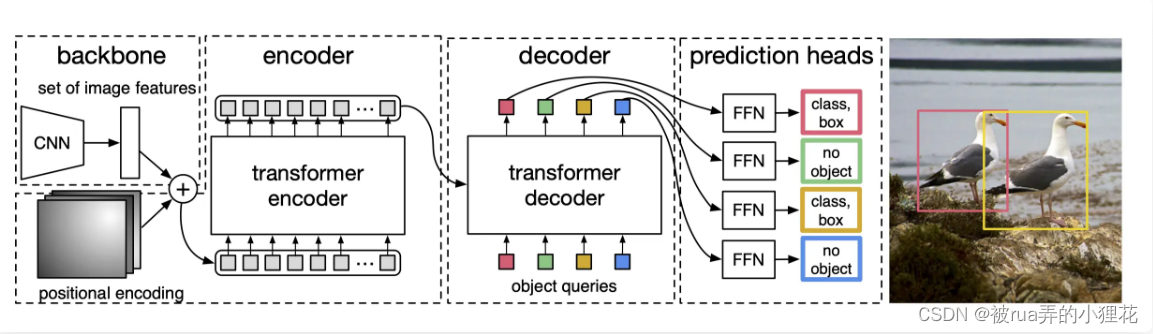
其实和上面流程图差不多,就是backbone的地方concat一个位置编码,再transformer decoder的输入加一个object queries
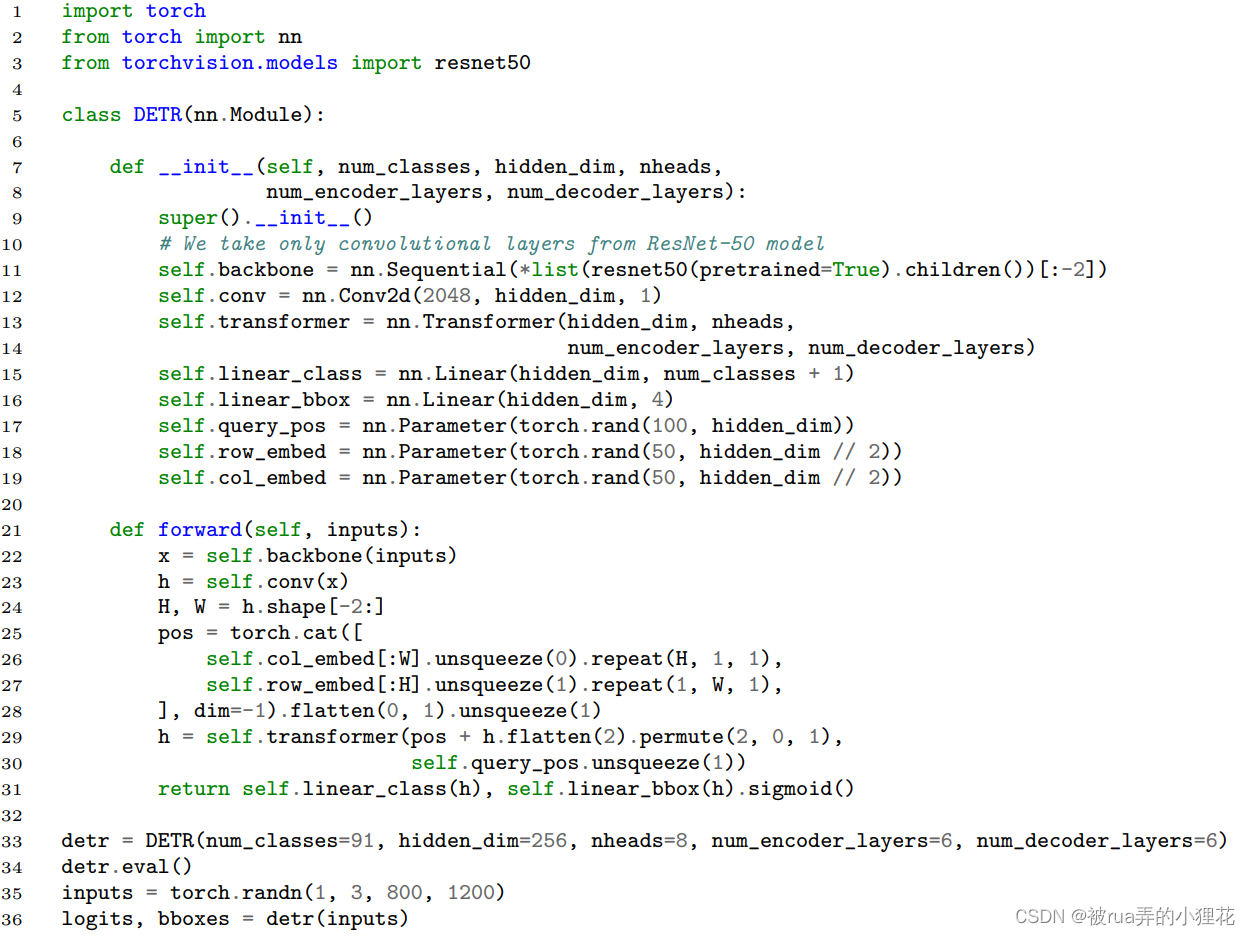
实验
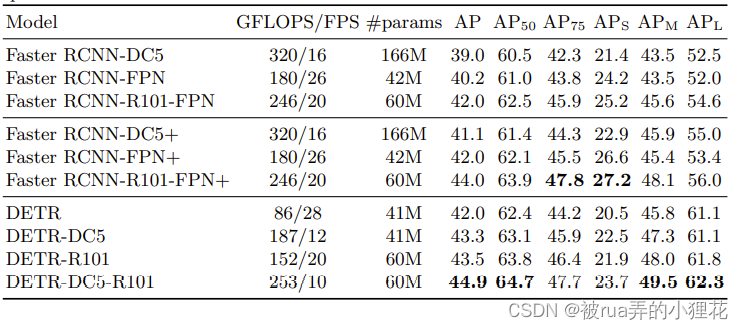
带+号的是使用新的数据增强策略训练过的Model,APs是小物体,DETR明显低了2个到5个点,而在APm和APl就好上不少,甚至高6个点。
其余更多的是可视化分析(encoder将object分得很开,decoder处理边界边缘和遮挡),以及消融实验,来进行公平对比就不一一列举了
PS:一个想法在数据集a不work,不代表在数据集b不work。{合适的切入点很重要}
DERT是一篇object detection领域里程碑的paper,后续有相当的多的工作以它为名字进行改进(后续的Deformable DETR在2021年ICLR影响力也是第二,第一是ViT),以后可以尝试一下这种架构。