摘要
我们在这项工作中的目标是视频文本检索——特别是一种联合嵌入,使高效的文本到视频检索成为可能。这一领域的挑战包括视觉体系结构的设计和训练数据的性质,因为可用的大规模视频文本训练数据集(如HowTo100M)是有噪声的,但是只有通过大量计算才能在规模上实现有竞争力的性能。
我们在本文中解决了这两个挑战。我们提出了一种端到端的可训练模型,旨在利用大规模图像和视频字幕数据集。我们的模型是对最近的ViT and Timesformer架构的改编和扩展,包括对空间和时间的关注。该模型是灵活的,可以在图像和视频文本数据集上单独或联合进行训练。
它通过一个课程学习计划进行训练,该计划首先将图像视为视频的“冻结”快照,然后在视频数据集上进行训练时,逐渐学习关注增加的时间上下文。我们还提供了一个新的视频文本预训练数据集WebVid-2M,它由200多万个从互联网上截取的弱标题视频组成。
尽管对较小数量级的数据集进行了培训,但我们表明,这种方法在标准下游视频检索基准(包括MSR-VTT、MSVD、DiDeMo和LSMDC)上产生了最先进的结果。
介绍
联合视觉文本模型已经变得越来越流行,因为它们支持广泛的下游任务,包括文本到视觉检索[34,35,40,62]、视觉字幕[27,61,68]和视觉问答[4,31]。它们的迅速发展得益于通常在三个方面的改进:新的神经网络结构(例如,文本和视觉输入的变压器[59]);新的大规模数据集;以及新的损耗函数,例如,能够处理标签噪声[39]。然而,它们的开发主要在两个独立的轨道上进行:一个用于图像,具有自己的体系结构、训练数据集和基准[28,34,55];另一个是视频,同样拥有自己的训练数据集和基准。两者之间唯一的共同联系是,视频网络通常通过图像数据集上的预训练图像网络进行初始化[6,8]。]。考虑到图像和视频在多个任务中传递的信息重叠,这种工作分离是次优的。例如,虽然对一些人的动作进行分类需要视频帧的时间顺序,但许多动作可以仅根据它们在帧上的分布进行分类,甚至可以从单个帧[54]进行分类。
在本文中,我们朝着统一这两条轨道迈出了一步,提出了一种双编码器架构,该架构利用了transformer视觉编码器的灵活性,从带字幕的图像、带字幕的视频剪辑或两者中进行训练(图1)。我们通过将图像视为“时间冻结”的视频的特例来实现这一点。使用基于转换器的架构,我们可以使用可变长度序列进行训练,将图像视为单帧视频,这与标准3D CNN[8,21,66]不同,在标准3D CNN[8,21,66]中,将图像与视频联合训练,必须承担实际生成静态视频的成本。此外,与视频文本双重编码的许多最新方法[19,35,40]不同,我们没有使用一组“专家网络”,这些网络是在外部图像数据集上预先训练然后固定的,而是端到端训练模型。
这种端到端的培训是通过抓取一个新的大规模视频文本字幕数据集(超过200万个视频alt文本对,WebVid-2M)的web来实现的。我们还利用了大规模的图像字幕数据集,如概念性字幕
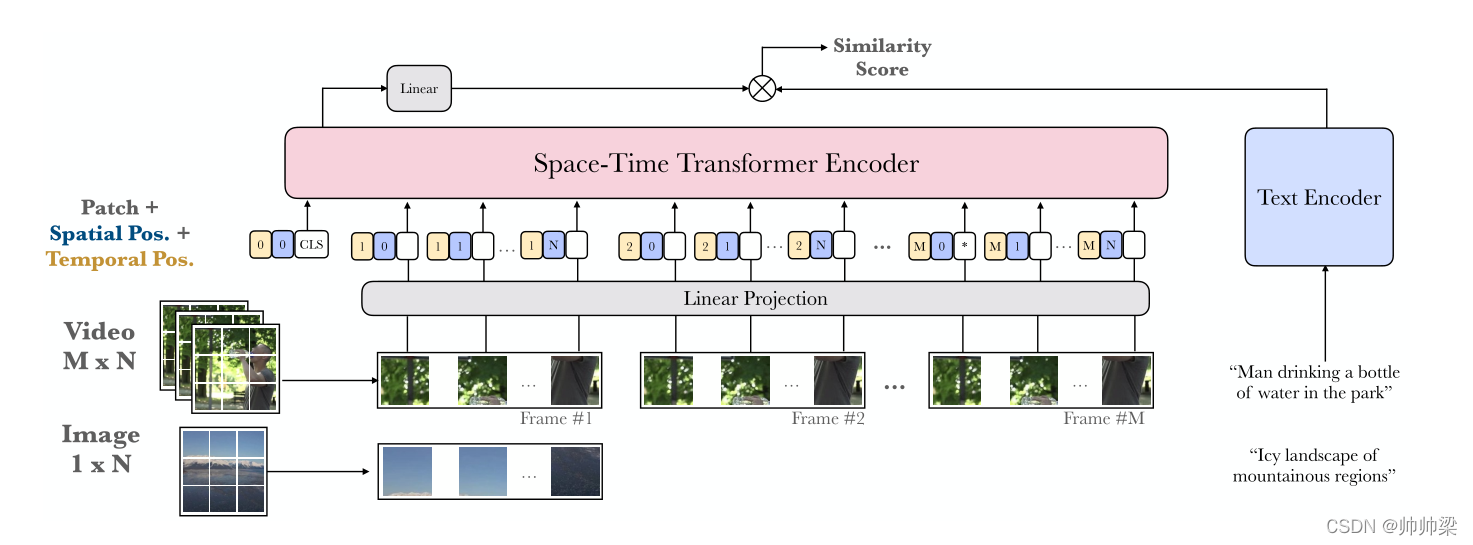
图像和视频联合训练:我们的双重编码模型由图像和视频的视觉编码器和字幕的文本编码器组成。与2D或3D CNN不同,我们的时空转换器编码器允许我们通过将图像视为单帧视频,灵活地对图像和带有字幕的视频进行联合训练。
我们做出了以下贡献:
(i)我们提出了一种新的端到端视频检索模型,该模型不依赖于“专家”特征,而是受[6]启发,采用了一种变换器架构,将改进的分时空注意力直接应用于像素;
(ii)由于我们的体系结构可以优雅地处理不同长度的输入,因此它是多功能的,并且可以灵活地在视频和图像数据集上进行训练(通过将图像视为单帧视频)。我们在这种灵活性的基础上,设计了一个课程学习计划,从图像开始,然后通过时间嵌入插值在视频数据集上进行训练,逐渐学习关注不断增加的时间上下文。我们表明,这提高了效率,允许我们用更少的GPU时间训练模型;
iii)我们引入了一个名为WebVid-2M的新数据集,由2个数据集组成。从网络上抓取500万对视频文本;
最后(iv)我们通过仅在MSR-VTT[67]、MSVD[9]、DiDeMo[3]和LSMDC[49]上使用视频模式实现了最先进的性能
方法
在本节中,我们将描述基于 transformer-based的时空模型架构(Section3.1)和训练策略(Section3.2)。
模型架构
输入:视觉编码器以图像或视频剪辑作为输入,文本编码器接受一个符号化的单词序列作为输入。
我们的模型具有独立的双编码器路径(如MIL-NCE[39]和MMV[1]网络),只需要视频和文本嵌入之间的点积。这确保了检索推理的成本很低,因为它是可索引的,也就是说,它允许应用快速近似最近邻搜索,并且在推理时可扩展到非常大规模的检索。给一个t查询和vvideos在一个在目标图库中,我们的检索复杂度O(t+v)。相比之下,将文本和视频作为输入输入到单个编码器的ClipBERT[30]具有检索复杂性O (tv),因为每个文本-视频组合都要输入到模型中。其他基于专家的检索方法,如MoEE[40]、CE[35]和MMT[19]也包含双编码器路径,但它们仍然需要查询条件加权来计算每个专家的相似度评分,而我们的模型不需要。
培训策略
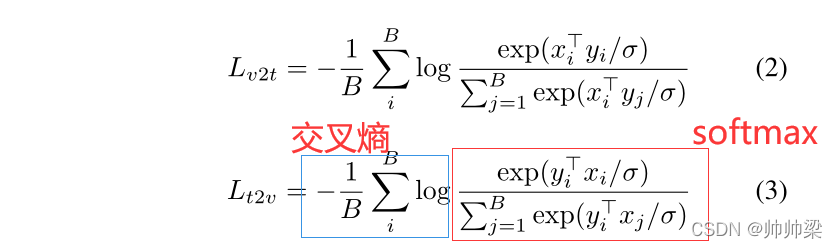
损失:
Joint image-video training.:
在这项工作中,我们联合训练图像-文本和视频-文本对,利用两者的优势进行大规模的预训练。我们的联合训练策略是在图像和视频数据集之间交替进行批量训练。由于注意机制随着输入帧数的平方( M 2 M^2 M2)而缩放,备用批处理训练允许图像批处理(M= 1)的大小要大得多。
Weight initialisation and pretraining.:
在[6]之后,我们使用ImageNet-21k上训练的ViT[17]权值初始化时空转换器模型中的空间注意权值,并初始化时间注意权值为零。剩余连接意味着在这些初始化设置下,模型首先等效于每个输入帧的ViT,从而允许模型随着训练的进展逐渐学习关注时间。由于transformer架构已经通过大规模的预训练取得了很大的成功,我们利用两个大规模的文本-图像/视频数据集进行联合训练,从而大大提高了性能。
Temporal curriculum learning.:
空时转换器架构允许可变长度的输入序列,因此允许可变数量的输入视频帧。但是,如果模型仅在长度为M的视频上进行训练,则时间位置嵌入 E t E^t Et仅能学习到 E : m t E^t_{:m} E:mt。将该模型应用于长度为M之外的序列,输入视频将导致 E m : M t E^t_{m:M} Em:Mt不会被学习。
在这项工作中,我们研究了两种扩展时间嵌入的策略,以使课程学习的框架越来越长。研究了两种时间展开方法:插值法和零填充法
我们研究了两种插值方法:最近邻法和双线性法。这些不同初始化的效果可以在C部分中找到。附录的第3部分。
Frame sampling.。给定一个包含L帧的视频,我们将它细分为相等的M片段,其中M是视频编码器所需的帧数。在训练过程中,我们从每个片段中统一采样单一帧(类似于TSN[63]和GST[36])。在测试的时候,我们采样每一个片段的帧,以得到一个视频嵌入vi。这些值是使用strideS确定的,结果是一个视频嵌入数组v= [v0, vS, v2S, vM]。这些视频嵌入的平均值作为视频的最终嵌入。
结论
最后,我们介绍了一种用于文本视频检索端到端训练的双编码器模型,该模型旨在利用大规模图像和视频字幕数据集。我们的模型在许多下游基准上实现了最先进的性能,但我们注意到,我们的模型的性能尚未饱和,通过对完整的Howto1000M数据集、较大的弱配对图像数据集(如Google3BN[23])以及它们的多数据集组合进行训练,可以进一步提高性能。