这是一篇2021年的CVPR Oral的论文,提出了一个名为SOHO的视觉-语言预训练模型,该模型采用了端到端的方式从数百万图像-文本中学习跨模态的视觉-语言表示。
论文链接: CVPR 2021 Open Access Repository
VLPT模型(视觉语言预训练模型)就是一个用于学习与任务无关的图像内容和自然语言的联合表征模型,在视觉-语言数据集上进行预训练,然后对其基础架构稍作调整以迁移到下游任务,比如VQA和image captioning。为什么要训练VLPT模型,而不像以往那样分别使用文本预训练和图像预训练模型得到图像和文本表示(representation)呢?这主要是对于visual-language领域的任务,需要图像与文本表示能够体现二者语义上的对齐,因此在visual-language领域中,近些年(2019)提出了VLPT模型,通过学习大规模易于访问的图像-文本对,得到更好的跨模态表示。
而端到端的模型就是将原先用多步骤、多模块的任务用单模型来解决,这能减少误差积累和工程复杂度,但模型的可解释性更差了。
SOHO模型

SOHO模型整体上来说就是,对于一个输入文本(a),使用一个文本嵌入(b)操作提取其文本嵌入特征,对于一张输入图像(b),本文使用了一个可训练的基于CNN的编码器(e)来提取视觉表征。为了进一步将图像特征转化为一致的语义,作者在文中提出了视觉词典的概念,并将这个基于视觉词典的图像嵌入(f)应用到图像编码器的输出。最后,将多层的Transformer (g)应用于具有三个预训练任务的多模态级联(c)的输出。
文中对于输入问题的处理,使用了谷歌2018年提出的BERT模型提取文本嵌入特征W。
Trainable Visual Encoder

当前主流的提取视觉特征的方法就是使用自下而上的注意力提取对象的视觉特征(BUTD这篇文章提出的方法,另一篇博客有笔记)。但是本文的作者认为这种方法忽略了边界框以外的上下文的信息,比如说以上面这张图为例,BUTD模型会认为这两个人在船上,忽略了边界框以外的对象之间的关系的信息;其次使用该方法,会使模型对于图像的视觉理解仅限于区域的预定义类别,最开始没有某一个类别信息,模型就永远不知道有这一个类别;最后就是图像特征会受到检测器的低质量、存在噪声和过采样的影响。

针对以上的问题,本文的作者想要提取图片中所有的视觉特征,因此就回到了2018年以前的方法,使用CNN来提取所有特征,将整个图像作为输入,然后用视觉特征编码器产生一个图像级的视觉特征。
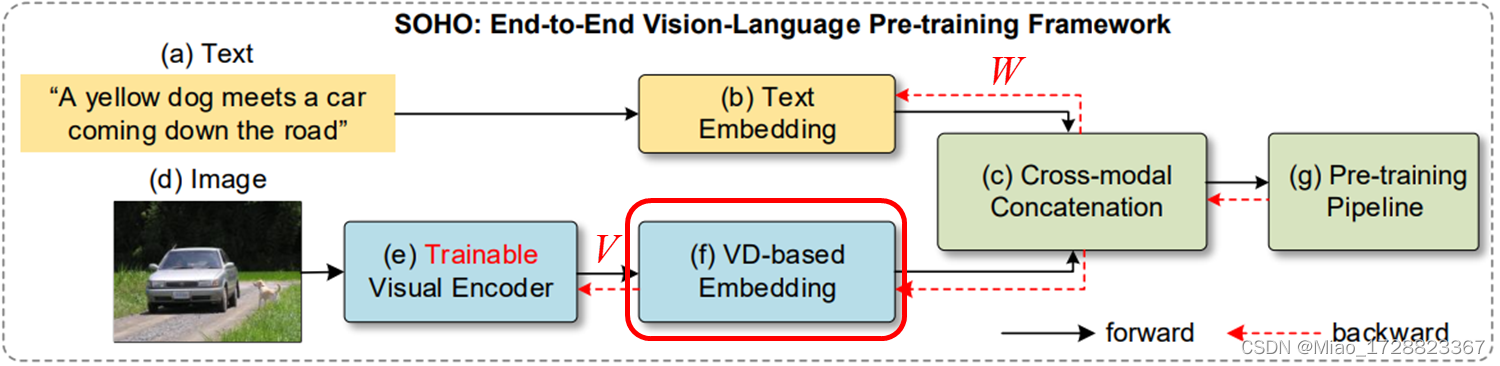
但是视觉编码器提取出的视觉特征V比文本特征W更加多样和密集,直接融合两者会给跨模态理解的学习带来困难。
Visual Dictionary
因此本文提出了一个视觉词典的概念,通过将相似的视觉语义聚合到相同的图像特征中来对视觉特征进行标记。



Pre-training Pipeline
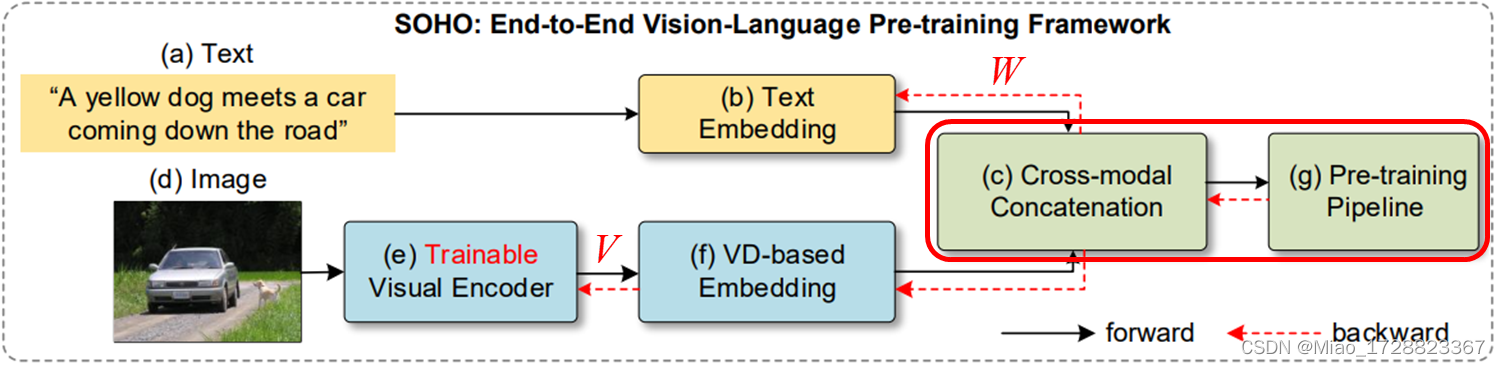
最后就是跨模态Transformer部分了,文章中应用了一个多层的Transformer来学习融合了视觉和语言特征的跨模态表示。
为了学习视觉-语言任务的通用表示,应用自监督的方法在大型数据集上预训练模型,预训练方法除了现有的Masked Language Modeling(MLM)和Image-Text Matching(ITM),作者还基于VD产生的虚拟视觉语义标签提出了Masked Visual Modeling(MVM)。
对于跨模态Transformer,就是将视觉词典嵌入和词嵌入向量级联在一起形成用于跨模态学习的输入序列,然后将这个序列输入一个多层的Transformer,从而得到视觉-语言联合特征。
![]()
对于MLM这个预训练模型方法,它来源于BERT,就是随机mask一些输入单词,然后希望模型预测出被mask的单词。MLM在本文中的作用是促使模型建立语言tokens和视觉内容之间的映射。所以这里预训练的目的是基于其他单词tokens和视觉特征f(V),通过最小化对数似然来预测被遮住的单词。
![]()
本文基于视觉词典提出的MVM预训练模型方法,它与MLM很类似,这里先随机屏蔽图像特征,然后根据周围图像特征和所有的语言标记,通过最小化对数似然来预测被屏蔽的图像特征。
![]()
为了增强跨模态匹配,文中采用了图像-文本匹配任务进行了预训练,在联合特征上应用二元分类器来预测输入的图像和文本是否匹配,对应损失函数如上式所示。
![]()
最后对于SOHO这个预训练模型整体的训练目标就是最小化上面的三个损失函数,作者在文中给它们分配了相同的损失权重。
Experiment
作者在MSCOCO和Visual Genome数据集上预训练SOHO模型,然后将预训练好的SOHO模型应用于四个下游任务。
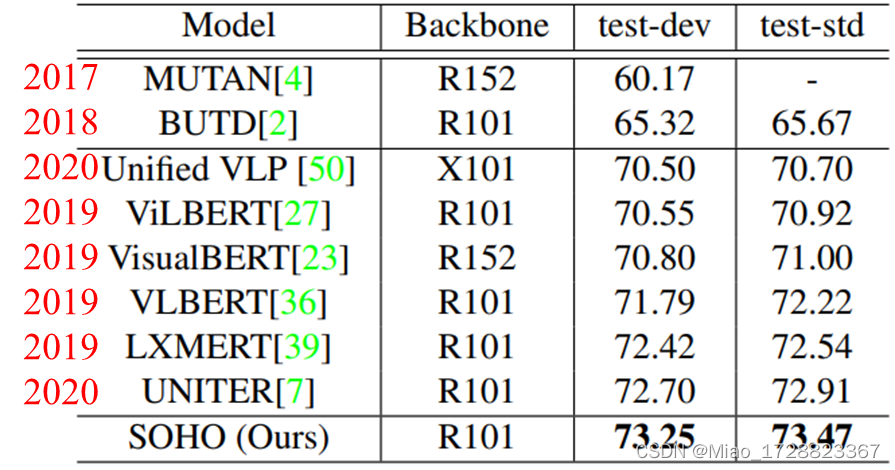
这里只列出了VQA任务的性能对比,用的数据集是VQA2数据集。其中LXMERT模型使用的预训练数据集和视觉编码器主干网络和本文是相同,SOHO模型性能在两个测试集上分别比它高0.83和0.93;UNITER这个模型还使用了额外的数据集进行预训练,本文在使用更少数据的情况下性能也更优。
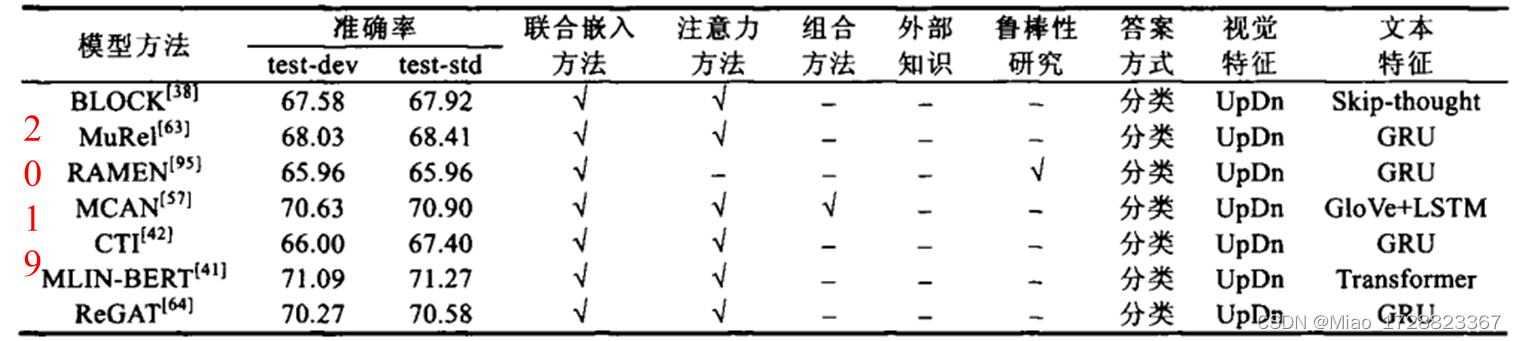
下面这张图是从一篇综述上截的其他类型的模型,这些都是针对VQA任务精心设计的特定于任务的模型,效果也都不如使用SOHO模型。
其他
亲试作者提供的源码可以跑通。在预训练这个视觉-语言预训练模型时,使用了两个数据集,MSCOCO和Visual Genome数据集,这里为了节约时间,我就没有自己进行预训练了,而是直接使用作者预训练好的模型。
然后是将这个预训练好的模型应用在VQA这个下游任务中,对于VQA模型的构建,只用在原始的预训练模型后面增加两个全连接层,然后将VQA任务视为一个多分类任务,模型最后一层输出3192个潜在答案的概率值。训练使用的数据集是VQA2数据集。训练在NVIDIA TITAN Xp上使用一张卡训练了20轮,每训练一轮差不多耗时5个小时。

两个测试例子
VQA Challenge官网测试结果:

整体准确率比作者在文中报告的低了好几个点,初步考虑可能是使用单卡,没有进行分布式训练导致的精度损失。
参考文献
[1] Huang Z, Zeng Z, Huang Y, et al. Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12976-12985.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] 包希港,周春来,肖克晶,覃飙.视觉问答研究综述[J].软件学报,2021,32(08):2522-2544.DOI:10.13328/j.cnki.jos.006215.