- 论文地址:1902.09513v2.pdf (arxiv.org) CVPR2019
- 代码: https://github.com/tensorflow/models/tree/master/research/feelvos.
总览
给定包含多帧数据以及第一帧的目标掩码,分割出这个目标在后续帧的像素级位置
多物体分割,端到端,主要是参考思想,里面的很多处理都可以优化

预测当前帧时一共有四个输入:
-
backbone:deeplabv3+提取特征,接着加一个embedding层提取向量 这里可以根据需求更换特征提取网络
-
全局匹配当前帧的embedding和第一帧中属于该物体的embedding来计算距离特征图
-
局部匹配当前帧和前一帧的embedding,得到另一个距离特征图
-
使用前一帧的预测作为附加线索
实现
embedding向量
(我的理解是,(i, j)像素点所有通道值组成的向量)
相当于通过计算两个像素点的嵌入向量距离来判断二者是否属于同一个物体
- 如果两个像素是同一类的,那么这两个像素对应的embedding向量之间的距离会很接近。
- 如果两个像素不属于同一类,那么这两个像素对应的embedding向量的距离很远。
两个向量之间的距离,对于像素点p和q, e p e_p ep表示像素p的embedding向量,d就是p到q在embedding空间的距离,对于相同类别的像素,d应该很接近0或者为0;对于不同类别的像素,d接近1或者为1
注意:这里计算距离的方式也可以采用更好的方法

全局匹配
在计算距离图时,对于当前帧t,当前分割的对象o,通过计算t中所有像素与第一帧中对象o所在的区域的像素的距离,取最小值,可以获得物体的大体轮廓是否发生变化。
- P t P_t Pt代表第t帧所有像素点
- P t , o P_{t, o} Pt,o表示第t帧中属于物体o的像素点的集合
- p p p是当前帧t中的一个像素
- G t , o ( p ) G_{t, o}(p) Gt,o(p)代表当前帧t,当前对象o,与第一帧 P 1 , o P_{1, o} P1,o集合(第一帧中属于o的像素点)中最近的距离

所以要得到完整的全局匹配距离图,需要把当前帧所有的像素点的嵌入向量,都和第一帧中属于同一类的嵌入向量计算向量距离,这是因为随着时间的推移物体可能发生了很大的移动,然后取得最小的距离值
很费时间,此时的改进或许可以考虑用transformer?因为transformer对建立长距离的关系依赖很有优势,所以可以考虑用它来处理跨多帧的信息
局部匹配
当前帧的嵌入向量与前一帧中属于该物体的嵌入向量相匹配,一个像素的匹配只允许在其周围的局部窗口进行
与全局匹配有一点不同,第一帧中肯定是有目标的(提前给出的),但此时前一帧可能没有目标物(是自己计算的),此时值记为1(白色)。
相邻帧的目标物体的移动距离其实是很小的,对于第t帧的像素p,在t-1中搜索时将像素q约束在窗口中,仅在一个k邻域大小中计算距离(在x和y方向上最多与p相距k个像素的像素集合)

这里限制框的选择方式是不是可以考虑多尺度金字塔?
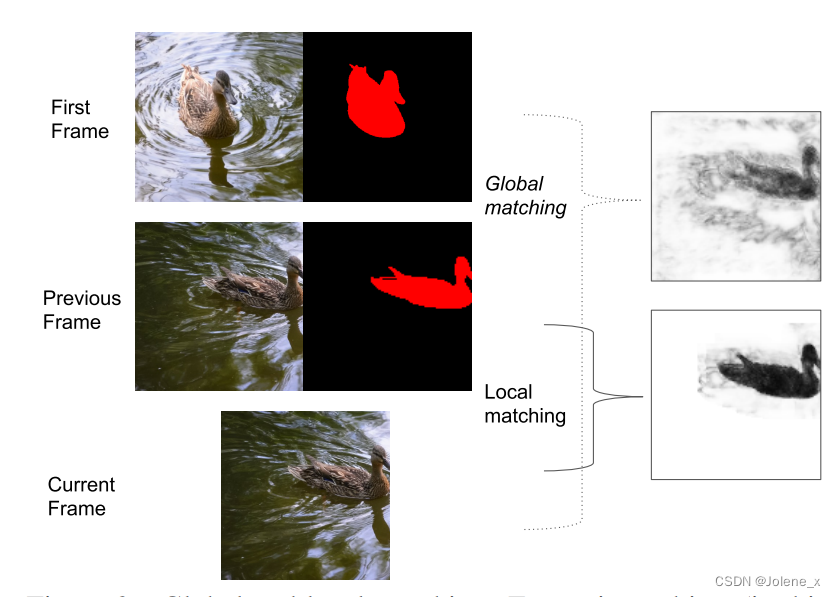
全局与局部
下图中,全局匹配鸭子被捕捉的相对较好,但是仍然有噪声,水中包含许多假阳性的小距离
而局部匹配,所有与前一帧掩码距离过远的像素都被赋予了1的距离,也就是白色,由于前一帧和当前帧之间的运动很小,所以局部匹配产生了一个非常清晰和准确的距离图
动态分割头
对每个实例的四个输入送进分割头,并为每个物体产生特征图,然后将所有的特征图concat

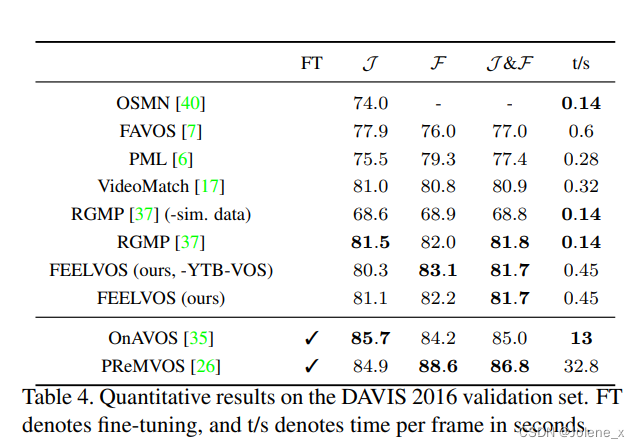
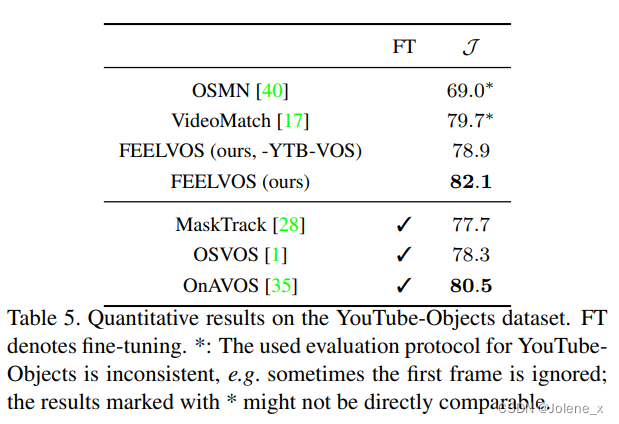
实验结果