首先看一下这篇文章的摘要

尽管利用CNN做图像超分辨在速度和精度上都有了突破,然后关键的问题在于做高倍超分辨的时候恢复精细的纹理很有挑战。当前的工作基本利用MSE做损失函数,但是产生的结果经常缺失高频细节,感知效果不好。本文首次提出利用生成对抗网络做高倍率超分辨,提出利用内容损失(perceptual loss) 和对抗损失(adversarial loss).
网络结构:
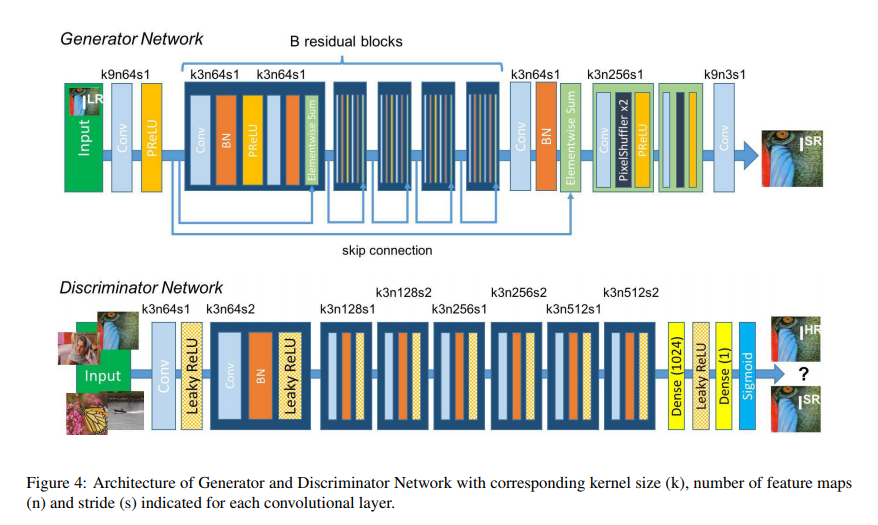
其中:
SRResNet:就是只用生成器,损失函数是MSE loss或者VGG loss
SRGAN:用了生成器和判别器,损失函数用了perceptual loss,adversarial loss
损失函数:
定义了感知损失函数(Perceptual loss function)来训练生成器:它是由内容损失和对抗损失的加权和。
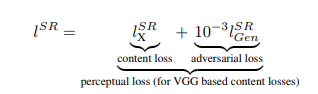
内容损失(content loss):
(1) MSE
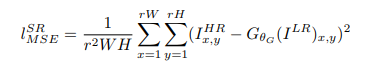
(2) 基于VGG

对抗损失(adversarial loss):
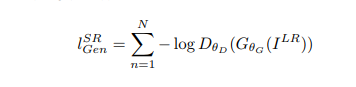
实验结果:
以下是用不同的content loss做的试验结果:
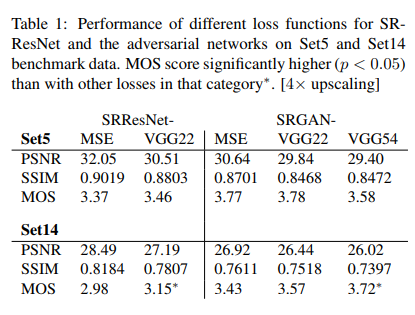
其中,
SRGAN-MSE表示对抗网络中content loss只用MSE
SRGAN-VGG22表示(i=2, j=2)表示定义在low-level特征图上的loss
SRGAN-VGG54表示(i = 5, j = 4)表示定义在high-level特征图上的loss。
SRResNet-MSE表示只用生成器,没有判别器(即不用adversarial loss),生成器的损失函数为MSE,简记为SRResNet
SRResNet-VGG22表示只用生成器,没有判别器(即不用adversarial loss),生成器的损失函数为VGG low-level特征图上的loss。


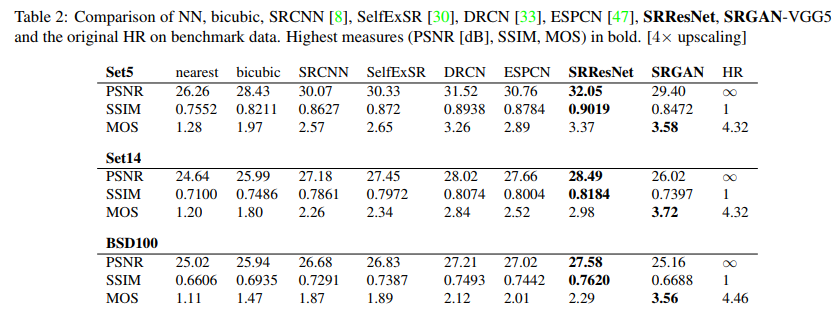
从试验结果可以看出,SRResNet的PSNR最高,而SRGAN的看着更真实。
