论文链接:https://arxiv.org/abs/1612.03242
文章大意:
在前文 “使用图片描述方式解决翻译问题”中提到了使用RNN文本描述信息抽象出对应图片特征的方法。其图片特征是抽象的(ResNet降维后的向量,而非图片本身),本文是使用图片的描述还原图片的尝试。网络结构相对简单,
下面给出模型示意图:
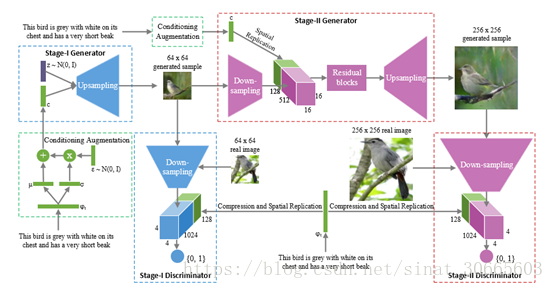
模型的总体结构较简单,为两个DCGAN加一个文本描述编码解码器。
给出一段对于对应图片的文本描述,使用CharRNN训练该描述的编码解码器,将隐状态作为文本输入,这部分描述作为条件GAN的条件输入(相应内容可参看前文“CycleGan 画风迁移初探”),这里的条件输入的定义类似于VAE中的隐状态分布(正态分布),隐状态分布参数由训练得到。与语义信息融合后利用DCGAN结构完成Stage-I的生成。(文本编码信息在discriminator端对每一个“像素”维度进行融合)
Stage-II是类似的。
训练注意点:
以其中第一个DCGAN结构为例(Stage-I),见下图:
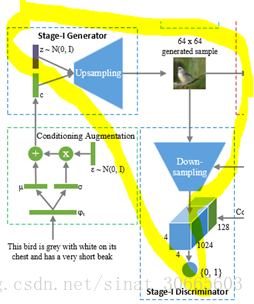
上图中黄色包围的部分为一个DCGAN结构,在单独使用随机数信息(不使用文本信息)的过程中,随着编码解码结构卷积层的增加,生成的效果可能会变差,而减少卷积层数对于较复杂的图像特征提取有很大影响,故可能用到一些trick。下面就提一个使用坐标信息放入待(反)卷积层的方法,见如下论文:
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
论文链接:
https://arxiv.org/abs/1807.03247
基本思路就是将坐标信息放入待卷积的通道维度(类似的trick在文本中有关于 cnn 或 attension 在序列问题中的绝对位置及相对位置(sin cos ----- attension is all you need)信息编码问题)。见下图:

实测,在鸟类图像生成问题中,这种预处理方式有很大助力。
下面在尝试给出上述模型的实现(加CoordConv Layer版本)
数据下载:
描述文本数据集:
https://drive.google.com/file/d/0B3y_msrWZaXLT1BZdVdycDY5TEE/view
鸟类图片数据集:
http://www.vision.caltech.edu/visipedia/CUB-200-2011.html
先给出训练的编码解码器实现:
# mix text data preprocess and text prepare in one file.
from collections import defaultdict, Counter
import os
from functools import reduce
import numpy as np
from copy import deepcopy
import pickle
import tensorflow as tf
def data_preprocess(data_path = r"C:\Users\dell\Downloads\birds\text_c10",
):
def walk_over_dir(rootDir):
req_dict = defaultdict(list)
def Test(rootDir):
for root, dirs, files in os.walk(rootDir):
root_key = root.split("\\")[-1].strip()
for filespath in files:
full_file_path = os.path.join(root,filespath)
req_dict[root_key].append(full_file_path)
return dict(req_dict.items())
return Test(rootDir)
def valid_char(char):
if (ord(char) >= ord('a') and ord(char) <= ord('z')) or ord(char) == ord(' '):
return True
return False
def parse_file(file_name):
if ".pkl" in file_name:
return None
with open(file_name, "r", encoding="utf-8") as f:
return list(map(lambda x: list(filter(valid_char ,list(x.lower().strip()))), f.readlines()))
req_dict = walk_over_dir(data_path)
all_seq_list = []
char_cnt = Counter()
max_seq_len = 0
min_seq_len = 100000
for k, v in req_dict.items():
tmp = list(filter(lambda x: x,map(parse_file, v)))
tmp = reduce(lambda x, y: x + y, tmp)
all_seq_list += tmp
char_cnt.update(reduce(lambda x, y: x + y, tmp))
l = max(map(len ,tmp))
ll = min(map(len, tmp))
if l > max_seq_len:
max_seq_len = l
if ll < min_seq_len:
min_seq_len = ll
# add padding
char2idx = dict((char, idx) for idx, char in enumerate(list(char_cnt.keys()) + ['<PAD>']))
print("char2idx size :{}".format(len(char2idx)))
print("max_seq_len: {}".format(max_seq_len))
print("min_seq_len: {}".format(min_seq_len))
return char2idx, max_seq_len, all_seq_list
char2idx, max_seq_len, all_seq_list = data_preprocess()
with open(r"C:\tempCodingUsage\python\StudyGAN\char_rnn\charrnn_model.pkl", "wb") as f:
pickle.dump({
"char2idx": char2idx,
"max_seq_len": max_seq_len,
"all_seq_list": all_seq_list
}, f)
def data_generator(batch_size = 64):
# init yield structure
pad_idx = char2idx["<PAD>"]
input = np.full(shape=[batch_size, max_seq_len - 1], fill_value=pad_idx).astype(
np.int32
)
y = deepcopy(input)
mask_len_array = np.full(shape=[batch_size], fill_value=max_seq_len - 1)
start_idx = 0
for sentence_list in all_seq_list:
input_sent = sentence_list[:-1]
y_sent = sentence_list[1:]
for token_idx, token in enumerate(input_sent):
input[start_idx][token_idx] = char2idx[token]
for token_idx, token in enumerate(y_sent):
y[start_idx][token_idx] = char2idx[token]
mask_len_array[start_idx] = len(input_sent)
start_idx += 1
if start_idx == batch_size:
yield input, y, mask_len_array
input = np.full(shape=[batch_size, max_seq_len - 1], fill_value=pad_idx).astype(
np.int32
)
y = deepcopy(input)
mask_len_array = np.full(shape=[batch_size], fill_value=max_seq_len - 1)
start_idx = 0
class CharRNN(object):
def __init__(self, char_embedding_dim = 100,
max_seq_len = max_seq_len - 1, char_num = len(char2idx),
gru_num_units = 100 * 2):
# when yield the dataset, max_seq_len corr to the max_setence_len - 1
# char_num should contains all i.e. padding ....
self.input_sequence = tf.placeholder(dtype=tf.int32, shape=[None, max_seq_len])
self.seq_mask = tf.placeholder(dtype=tf.int32 ,shape=[None])
self.y = tf.placeholder(dtype=tf.int32, shape=[None, max_seq_len])
self.gru_num_units = gru_num_units
self.char_num = char_num
self.char_embedding_dim = char_embedding_dim
self.char_embedding = tf.Variable(
initial_value=tf.random_normal(shape=[char_num, char_embedding_dim]),
name="char_embedding"
)
self.model_construct()
# flatten slice
def slice_func(self, input):
slice_mask = tf.sequence_mask(self.seq_mask, maxlen=tf.reduce_max(self.seq_mask))
sliced_tensor = tf.boolean_mask(input, slice_mask)
return sliced_tensor
def model_construct(self):
char_seq_embedded = tf.nn.embedding_lookup(self.char_embedding,
self.input_sequence)
cell = tf.contrib.rnn.GRUCell(self.gru_num_units / 2)
outputs, state = tf.nn.dynamic_rnn(cell=cell, inputs=char_seq_embedded,
sequence_length = self.seq_mask,
dtype=tf.float32)
# outputs [batch, max_seq_len, embedding_dim]
# will slice by mask in the final
# used to capture sentence information
self.state = state
sliced_outputs = self.slice_func(outputs)
sliced_y = self.slice_func(self.y)
pred_outputs = tf.layers.dense(sliced_outputs, units=self.char_num, name="char_pred_layer")
one_hot_y = tf.one_hot(sliced_y, depth=self.char_num)
labels = one_hot_y
logits = pred_outputs
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
opt = tf.train.AdamOptimizer(learning_rate=0.001)
self.train_op = opt.minimize(self.loss)
@staticmethod
def train():
model = CharRNN()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("model init end")
epoch = 0
step = 0
train_gen = data_generator()
while True:
try:
input, y, mask_len_array = train_gen.__next__()
except:
print("one epoch end")
epoch += 1
train_gen = data_generator()
_, loss = sess.run([model.train_op, model.loss],
feed_dict={
model.input_sequence:input,
model.y: y,
model.seq_mask: mask_len_array
})
step += 1
if step % 100 == 0:
print("epoch: {} train_loss: {}".format(epoch ,loss))
saver.save(sess, save_path = r"C:\tempCodingUsage\python\StudyGAN\char_rnn")
print("save model")
@staticmethod
def predict(batch_input_list):
with open(r"C:\tempCodingUsage\python\StudyGAN\char_rnn\charrnn_model.pkl", "rb") as f:
req_dict = pickle.load(f)
char2idx = req_dict["char2idx"]
max_seq_len = req_dict["max_seq_len"]
def retrieve_single_list(single_input_list):
head_list = list(map(lambda x: char2idx[x], single_input_list))
req_list = head_list + [char2idx["<PAD>"]] * max_seq_len - 1 - len(head_list)
req_list = req_list[: max_seq_len - 1]
return req_list
batch_input = np.array(list(map(retrieve_single_list, batch_input_list)))
model = CharRNN()
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, save_path=r"C:\tempCodingUsage\python\StudyGAN\char_rnn")
state = sess.run([model.state], feed_dict={
model.input_sequence: batch_input
})
state = state[0]
return state
@staticmethod
def produce_all_sentence_encoding():
def walk_over_dir(rootDir):
req_dict = defaultdict(list)
def Test(rootDir):
for root, dirs, files in os.walk(rootDir):
root_key = root.split("\\")[-1].strip()
for filespath in files:
full_file_path = os.path.join(root,filespath)
req_dict[root_key].append(full_file_path)
return dict(req_dict.items())
return Test(rootDir)
def valid_char(char):
if (ord(char) >= ord('a') and ord(char) <= ord('z')) or ord(char) == ord(' '):
return True
return False
def parse_file(file_name):
if ".pkl" in file_name:
return None
with open(file_name, "r", encoding="utf-8") as f:
return list(map(lambda x: list(filter(valid_char ,list(x.lower().strip()))), f.readlines()))
with open(r"C:\tempCodingUsage\python\StudyGAN\char_rnn\charrnn_model.pkl", "rb") as f:
req_dict = pickle.load(f)
char2idx = req_dict["char2idx"]
max_seq_len = req_dict["max_seq_len"]
model = CharRNN()
sess = tf.Session()
saver = tf.train.Saver()
saver.restore(sess, r"C:\tempCodingUsage\python\StudyGAN\char_rnn")
def predict(batch_input_list):
def retrieve_single_list(single_input_list):
head_list = list(map(lambda x: char2idx[x], single_input_list))
req_list = head_list + [char2idx["<PAD>"]] * (max_seq_len - len(head_list))
req_list = req_list[: max_seq_len]
return (req_list, len(head_list))
t2_list = list(map(retrieve_single_list, batch_input_list))
input_all = np.array(list(map(lambda x: x[0],t2_list)))
input = input_all[:, :-1]
y = input_all[:, 1:]
mask = np.array(list(map(lambda x: x[1], t2_list))) - 1
state = sess.run([model.state], feed_dict={
model.input_sequence: input,
model.y: y,
model.seq_mask: mask
})
state = state[0]
return state
req_dict = walk_over_dir(r"C:\Users\dell\Downloads\birds\text_c10")
for k, v in req_dict.items():
# v is the list of files
for file in v:
double_list = parse_file(file)
if double_list is None:
continue
predict_batch_state = predict(double_list)
with open(file.replace(".txt", "_state.pkl"), "wb") as f:
pickle.dump(predict_batch_state, f)
print("{} final".format(k))
sess.close()
if __name__ == "__main__":
CharRNN.train()
#CharRNN.produce_all_sentence_encoding()再给出Stage-I的DCGAN部分实现,并看一看CoordConv Layer生成的鸟类结果
数据导出:
import numpy as np
import os
from collections import defaultdict
from PIL import Image
import random
def batch_loader(batch_size = 4,
data_path = r"C:\Users\dell\Downloads\birds\text_c10",
resize = (64, 64),
):
def walk_over_dir(rootDir):
req_dict = defaultdict(list)
def Test(rootDir):
for root, dirs, files in os.walk(rootDir):
root_key = root.split("\\")[-1].strip()
for filespath in files:
full_file_path = os.path.join(root,filespath)
req_dict[root_key].append(full_file_path)
return dict(req_dict.items())
return Test(rootDir)
def parse_file(file_name, all_img_files):
if ".pkl" not in file_name:
return None
req_file_name_l2 = file_name.replace(r"_state.pkl", r"").split("\\")[-2:]
req_file_name = "_".join(r"C:\Users\dell\Downloads\images\images\images\{}\{}".format(*req_file_name_l2).split("_")[:-1])
req_img_name = None
for img_file_name in all_img_files:
if img_file_name.startswith(req_file_name):
req_img_name = img_file_name
break
if req_img_name is None:
return None
with open(req_img_name, "rb") as f:
image = Image.open(f).resize(resize)
img_array = np.array(image) / 255.0
return img_array
def data_generator():
req_array_dict = walk_over_dir(data_path)
req_img_dict = walk_over_dir(r"C:\Users\dell\Downloads\images\images\images")
all_img_files = []
for k, v in req_img_dict.items():
# v is the list of files
all_img_files += v
start_idx = 0
batch_img_list = []
for k, v in random.sample(req_array_dict.items(), len(req_array_dict)):
# v is the list of files
for array_file in random.sample(v, len(v)):
parse_conclusion = parse_file(array_file, all_img_files)
if parse_conclusion is None:
continue
img_array = parse_conclusion
batch_img_list.append(img_array[np.newaxis,...])
start_idx += 1
if start_idx == batch_size:
img = np.concatenate(batch_img_list, axis=0)
yield img
start_idx = 0
batch_img_list = []
data_gen = data_generator()
while True:
try:
yield data_gen.__next__()
except:
print("one epoch end, re init")
yield None
data_gen = data_generator()
Stage-I DCGAN实现:
import tensorflow as tf
import numpy as np
from PIL import Image
import uuid
def standard_normal_random(batch_size = 4, dim = 2 * 2 * 2048):
return np.random.randn(batch_size, dim)
class StackGAN(object):
def __init__(self, z_dim = 2 * 2 * 2048,
batch_size = 4,
add_corr = True,
kernel_size = 3,
):
self.add_corr = add_corr
self.kernel_size = kernel_size
self.z_part_I = tf.placeholder(tf.float32, [None, z_dim])
# true image input
self.true_image_input_64 = tf.placeholder(tf.float32, [None, 64, 64, 3])
self.batch_size = batch_size
self.z_dim = z_dim
self.is_training = tf.placeholder(tf.bool, shape=[], name="is_training")
with tf.variable_scope("stage_I"):
with tf.variable_scope("discriminator"):
# image score weight prediction weight
self.W1 = tf.Variable(
tf.random_normal(shape=[(2048) * 2 * 2, 1],
mean=0.0, stddev=0.001),
name="W1"
)
self.b1 = tf.Variable(
tf.constant([1.0]), name="b1"
)
self.d_vars_I = []
self.g_vars_I = []
self.train_opt_construct()
def assign_vars_to_list(self, debug = True):
for var in tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES):
if "stage_I" in str(var):
if "discriminator" in str(var):
self.d_vars_I.append(var)
else:
self.g_vars_I.append(var)
if debug:
print("show var list :")
print("\nd_vars_I :")
for ele in self.d_vars_I:
print(ele)
print("\ng_vars_I :")
for ele in self.g_vars_I:
print(ele)
def get_corr_tensor(self, height, width):
height_part = tf.expand_dims(tf.tile(tf.expand_dims(tf.tile(tf.expand_dims(tf.range(height, dtype=tf.float32), dim=0), [width, 1]), dim=0), [self.batch_size, 1, 1]), dim=-1)
width_part = tf.expand_dims(tf.tile(tf.expand_dims(tf.tile(tf.expand_dims(tf.range(width, dtype=tf.float32), dim=0), [height, 1]), dim=0), [self.batch_size, 1, 1]), dim=-1)
width_part = tf.transpose(width_part, [0, 2, 1, 3])
req = tf.concat([height_part, width_part], axis=-1)
return req
def add_corr_tensor(self, input):
height = int(input.get_shape()[1])
width = int(input.get_shape()[2])
return tf.concat([input, self.get_corr_tensor(height, width)], axis=-1)
def stackgan_I_generator(self, cz_part):
# resize
with tf.variable_scope("stackI_up"):
cz_resize = tf.reshape(cz_part, [-1, 2, 2, 2048])
if self.add_corr:
cz_resize = self.add_corr_tensor(cz_resize)
up0 = tf.layers.conv2d_transpose(inputs=cz_resize, filters=1024, strides=(2, 2),
kernel_size=self.kernel_size,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up0")
up0 = tf.nn.leaky_relu(tf.layers.batch_normalization(up0
, training=self.is_training,
name="norm0"))
if self.add_corr:
up0 = self.add_corr_tensor(up0)
up1 = tf.layers.conv2d_transpose(inputs=up0, filters=512, strides=(2, 2),
kernel_size=self.kernel_size,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up1")
up1 = tf.nn.leaky_relu(tf.layers.batch_normalization(up1
, training=self.is_training,
name="norm1"))
if self.add_corr:
up1 = self.add_corr_tensor(up1)
up2 = tf.layers.conv2d_transpose(inputs=up1, filters=256, strides=(2, 2),
kernel_size=self.kernel_size,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up2")
up2 = tf.nn.leaky_relu(tf.layers.batch_normalization(up2
, training=self.is_training,
name="norm2"))
if self.add_corr:
up2 = self.add_corr_tensor(up2)
up3 = tf.layers.conv2d_transpose(inputs=up2, filters=128, strides=(2, 2),
kernel_size=self.kernel_size,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up3")
up3 = tf.nn.leaky_relu(tf.layers.batch_normalization(up3
, training=self.is_training,
name="norm3"))
if self.add_corr:
up3 = self.add_corr_tensor(up3)
upsampling_cz = tf.layers.conv2d_transpose(inputs=up3, filters=3, strides=(2, 2),
kernel_size=self.kernel_size,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="upsampling_cz")
upsampling_cz = tf.nn.leaky_relu(tf.layers.batch_normalization(upsampling_cz
, training=self.is_training,
name="norm4"))
upsampling_cz = tf.nn.sigmoid(upsampling_cz)
return upsampling_cz
def stackgan_I_discriminator(self, generator_input):
# generator input [batch, 64, 64, 3]
with tf.variable_scope("stackI_down", reuse=tf.AUTO_REUSE):
# [batch, 32, 32, 128]
if self.add_corr:
generator_input = self.add_corr_tensor(generator_input)
down_1 = tf.layers.conv2d(generator_input, filters=128, strides=(2, 2),
kernel_size=self.kernel_size, padding="SAME", name="stackI_down1",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_1 = tf.nn.leaky_relu(down_1
)
# [batch, 16, 16, 256]
if self.add_corr:
down_1 = self.add_corr_tensor(down_1)
down_2 = tf.layers.conv2d(down_1, filters=256, strides=(2, 2),
kernel_size=self.kernel_size, padding="SAME", name="stackI_down2",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_2 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_2
, training=self.is_training,
name="norm2", reuse=tf.AUTO_REUSE))
# [batch, 8, 8, 512]
if self.add_corr:
down_2 = self.add_corr_tensor(down_2)
down_3 = tf.layers.conv2d(down_2, filters=512, strides=(2, 2),
kernel_size=self.kernel_size, padding="SAME", name="stackI_down3",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_3 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_3
, training=self.is_training,
name="norm3",
reuse=tf.AUTO_REUSE))
# [batch, 4, 4, 1024]
if self.add_corr:
down_3 = self.add_corr_tensor(down_3)
down_4 = tf.layers.conv2d(down_3, filters=1024, strides=(2, 2),
kernel_size=self.kernel_size, padding="SAME", name="stackI_down4"
, reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_4 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_4
, training=self.is_training,
name="norm4",
reuse=tf.AUTO_REUSE))
# [batch, 2, 2, 2048]
if self.add_corr:
down_4 = self.add_corr_tensor(down_4)
down_5 = tf.layers.conv2d(down_4, filters=2048, strides=(2, 2),
kernel_size=self.kernel_size, padding="SAME", name="stackI_down5"
, reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_5 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_5
, training=self.is_training,
name="norm5",
reuse=tf.AUTO_REUSE))
return down_5
def compute_single_bce(self, D_text_with_image, labels, W, b):
# flatten D_text_with_image
D_feature_flatten = tf.reshape(D_text_with_image, [self.batch_size, -1])
logits = tf.nn.xw_plus_b(D_feature_flatten, W, b)
bce_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))
return logits ,bce_loss
def model_construct(self):
with tf.variable_scope("stage_I"):
# first layer generator output [batch, 64, 64, 3]
upsampling_cz_I = self.stackgan_I_generator(self.z_part_I)
self.output_I = upsampling_cz_I
with tf.variable_scope("discriminator"):
# [batch, 4, 4, 1024 + 128]
D_text_with_image_I_false = self.stackgan_I_discriminator(upsampling_cz_I)
D_text_with_image_I_true = self.stackgan_I_discriminator(self.true_image_input_64)
self.D_text_with_image_I_false = D_text_with_image_I_false
self.D_text_with_image_I_true = D_text_with_image_I_true
logits1 ,bce_I_one_false = self.compute_single_bce(D_text_with_image_I_false, tf.ones([self.batch_size, 1]), self.W1, self.b1)
self.false_one_logits = tf.nn.sigmoid(logits1)
logits2 ,bce_I_zero_false = self.compute_single_bce(D_text_with_image_I_false, tf.zeros([self.batch_size, 1]), self.W1, self.b1)
self.false_zero_logits = tf.nn.sigmoid(logits2)
logits3 ,bce_I_one_true = self.compute_single_bce(D_text_with_image_I_true, tf.ones([self.batch_size, 1]), self.W1, self.b1)
self.true_one_logits = tf.nn.sigmoid(logits3)
return bce_I_one_false, bce_I_zero_false, bce_I_one_true
def train_opt_construct(self):
bce_I_one_false, bce_I_zero_false, bce_I_one_true = self.model_construct()
self.assign_vars_to_list()
self.d_optim_I_loss = bce_I_one_true + bce_I_zero_false
self.d_optim_I = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.d_optim_I_loss, var_list=self.d_vars_I)
self.g_optim_I_loss = bce_I_one_false
self.g_optim_I = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.g_optim_I_loss, var_list=self.g_vars_I)
@staticmethod
def update_model(sess ,model, input_data_dict, debug = False,
batch_size = 8, z_dim = 2 * 2 * 2048,
step = 0):
def visualize_output(single_output_array, pic = "1"):
img = Image.fromarray((single_output_array * 255).astype(np.uint8), mode=None)
with open(r"C:\tempCodingUsage\python\StudyGAN\pic_{}\{}.jpg".format(pic ,uuid.uuid1()), "wb") as f:
img.save(f)
z_part_I = standard_normal_random(batch_size, z_dim)
_, g_optim_I_loss = sess.run([model.g_optim_I, model.g_optim_I_loss],
feed_dict = {
model.true_image_input_64: input_data_dict["true_image_input_64"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
})
_, d_optim_I_loss = sess.run([model.d_optim_I, model.d_optim_I_loss
],
feed_dict = {
model.true_image_input_64: input_data_dict["true_image_input_64"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
})
false_one_logits, false_zero_logits, \
true_one_logits, \
D_text_with_image_I_false, \
D_text_with_image_I_true, \
output_I, \
= sess.run([model.false_one_logits, model.false_zero_logits,
model.true_one_logits,
model.D_text_with_image_I_false,
model.D_text_with_image_I_true,
model.output_I,
],
feed_dict = {
model.true_image_input_64: input_data_dict["true_image_input_64"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
})
percentiles = np.array([0.1 ,0.25, 0.5, 0.75, 0.9])
ptiles_vers_false = np.percentile(false_one_logits, percentiles)
if debug:
print("false_one_logits :")
print("false_one_logits ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_false = np.percentile(false_zero_logits, percentiles)
if debug:
print("false_zero_logits :")
print("false_zero_logits ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_true = np.percentile(true_one_logits, percentiles)
if debug:
print("true_one_logits :")
print("true_one_logits ptiles_vers :")
print(ptiles_vers_true)
ptiles_vers_output = np.percentile(output_I, percentiles)
if debug:
print("output_I :")
print("output_I ptiles_vers :")
print(ptiles_vers_output)
print("-" * 100)
if (np.mean(ptiles_vers_true) > 0.9 and np.mean(ptiles_vers_false) > 0.5):
visualize_output(output_I[0], pic="51")
elif step % 100 == 0:
visualize_output(output_I[0], pic="52")
return d_optim_I_loss, g_optim_I_loss, (np.mean(ptiles_vers_true) > 0.9 and np.mean(ptiles_vers_false) > 0.5)
@staticmethod
def train():
import os
from data_process.img_data_loader import batch_loader
batch_size = 4
train_gen = batch_loader(batch_size)
model = StackGAN(batch_size=batch_size)
saver = tf.train.Saver()
sess = tf.Session()
if os.path.exists(r"C:\tempCodingUsage\python\StudyGAN\stack_gan.index"):
saver.restore(sess, r"C:\tempCodingUsage\python\StudyGAN\stack_gan")
print("exist")
else:
sess.run(tf.global_variables_initializer())
print("init new")
print("model init end")
step = 0
epoch = 0
while True:
input_data = train_gen.__next__()
if input_data is None:
epoch += 1
continue
step += 1
img_f = input_data
input_data = {
"true_image_input_64": img_f ,
"is_training": True
}
d_optim_I_loss, g_optim_I_loss, save_conclusion = StackGAN.update_model(sess, model, input_data, batch_size=batch_size,
debug=step % 10 == 0,
step = step)
if step % 10 == 0:
print("epoch: {} step: {}".format(epoch ,step))
print(d_optim_I_loss, g_optim_I_loss)
sess.close()
if __name__ == "__main__":
StackGAN.train()
(前若干步)生成图片示例:





整体实现:
数据导出:
import numpy as np
import os
from collections import defaultdict
import pickle
from PIL import Image
import random
def batch_loader(batch_size = 4,
data_path = r"C:\Users\dell\Downloads\birds\text_c10",
resize = (256, 256),
zero_rnn = True,
):
def walk_over_dir(rootDir):
req_dict = defaultdict(list)
def Test(rootDir):
for root, dirs, files in os.walk(rootDir):
root_key = root.split("\\")[-1].strip()
for filespath in files:
full_file_path = os.path.join(root,filespath)
req_dict[root_key].append(full_file_path)
return dict(req_dict.items())
return Test(rootDir)
def parse_file(file_name, all_img_files):
if ".pkl" not in file_name:
return None
req_file_name_l2 = file_name.replace(r"_state.pkl", r"").split("\\")[-2:]
req_file_name = "_".join(r"C:\Users\dell\Downloads\images\images\images\{}\{}".format(*req_file_name_l2).split("_")[:-1])
req_img_name = None
for img_file_name in all_img_files:
if img_file_name.startswith(req_file_name):
req_img_name = img_file_name
break
if req_img_name is None:
return None
with open(file_name, "rb") as f:
pkl_array = pickle.load(f)
with open(req_img_name, "rb") as f:
image = Image.open(f).resize(resize)
img_array = np.array(image) / 255.0
return img_array, pkl_array
def data_generator():
req_array_dict = walk_over_dir(data_path)
req_img_dict = walk_over_dir(r"C:\Users\dell\Downloads\images\images\images")
all_img_files = []
for k, v in req_img_dict.items():
# v is the list of files
all_img_files += v
start_idx = 0
batch_img_list = []
batch_char_rnn_list = []
for k, v in random.sample(req_array_dict.items(), len(req_array_dict)):
# v is the list of files
for array_file in random.sample(v, len(v)):
parse_conclusion = parse_file(array_file, all_img_files)
if parse_conclusion is None:
continue
img_array, pkl_array = parse_conclusion
batch_img_list.append(img_array[np.newaxis,...])
batch_char_rnn_list.append(random.choice(pkl_array)[np.newaxis,...])
start_idx += 1
if start_idx == batch_size:
img, rnn = np.concatenate(batch_img_list, axis=0), np.concatenate(batch_char_rnn_list,
axis=0)
if zero_rnn:
yield img, np.zeros_like(rnn, dtype=np.float32)
else:
yield img, rnn
start_idx = 0
batch_img_list = []
batch_char_rnn_list = []
data_gen = data_generator()
while True:
try:
yield data_gen.__next__()
except:
print("one epoch end, re init")
yield None
data_gen = data_generator(
实现:
import tensorflow as tf
import numpy as np
def standard_normal_random(batch_size = 4, dim = 100):
return np.random.randn(batch_size, dim)
def get_KL_Loss(mu, logvar):
kld = tf.pow(mu, 2) + (tf.exp(2 * logvar)) + -0.5 + (-1 * logvar)
kl_loss = tf.reduce_mean(kld)
return kl_loss
class StackGAN(object):
def __init__(self, z_dim = 100, c_dim = 100, char_rnn_dim = 100,
batch_size = 4, lambda_val = 0.0):
# image description char_rnn input
self.mu_sigma_preduce_array = tf.placeholder(tf.float32, [None, char_rnn_dim])
self.std_normal_I = tf.placeholder(tf.float32, [None, c_dim])
self.z_part_I = tf.placeholder(tf.float32, [None, z_dim])
self.std_normal_II = tf.placeholder(tf.float32, [None, c_dim])
self.z_part_II = tf.placeholder(tf.float32, [None, z_dim])
# true image input
self.true_image_input_256 = tf.placeholder(tf.float32, [None, 256, 256, 3])
self.true_image_input_64 = self.down_sampling_to_64(self.true_image_input_256)
self.batch_size = batch_size
self.z_dim = z_dim
self.c_dim = c_dim
self.lambda_val = lambda_val
self.is_training = tf.placeholder(tf.bool, shape=[], name="is_training")
with tf.variable_scope("stage_I"):
with tf.variable_scope("discriminator"):
# image score weight prediction weight
self.W1 = tf.Variable(
tf.random_normal(shape=[(1024 + 128) * 4 * 4, 1],
mean=0.0, stddev=0.001),
name="W1"
)
self.b1 = tf.Variable(
tf.constant([1.0]), name="b1"
)
with tf.variable_scope("stage_II"):
with tf.variable_scope("discriminator"):
# image score weight prediction weight
self.W2 = tf.Variable(
tf.random_normal(shape=[(1024 + 128) * 4 * 4, 1],
mean=0.0, stddev=0.001),
name="W2"
)
self.b2 = tf.Variable(
tf.constant([1.0]), name="b2"
)
self.d_vars_I = []
self.g_vars_I = []
self.d_vars_II = []
self.g_vars_II = []
self.train_opt_construct()
def down_sampling_to_64(self, image_input):
return tf.image.resize_bilinear(image_input, tf.constant([64, 64]))
def assign_vars_to_list(self, debug = True):
for var in tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES):
if "stage_I" in str(var):
if "discriminator" in str(var):
self.d_vars_I.append(var)
else:
self.g_vars_I.append(var)
if "stage_II" in str(var):
if "discriminator" in str(var):
self.d_vars_II.append(var)
else:
self.g_vars_II.append(var)
if debug:
print("show var list :")
print("\nd_vars_I :")
for ele in self.d_vars_I:
print(ele)
print("\ng_vars_I :")
for ele in self.g_vars_I:
print(ele)
print("\nd_vars_II :")
for ele in self.d_vars_II:
print(ele)
print("\ng_vars_II :")
for ele in self.g_vars_II:
print(ele)
# produce cz feature for upsample
def cz_layer(self, std_normal, z_part):
# [batch, 1]
mu = tf.layers.dense(inputs=self.mu_sigma_preduce_array,
units=self.c_dim, name="mu_layer")
# sigma must be positive
log_sigma = tf.layers.dense(inputs=self.mu_sigma_preduce_array,
units=self.c_dim, name="sigma_layer", activation=None)
sigma = tf.exp(log_sigma)
log_var = tf.log(tf.pow(sigma, 2))
mu_tiled = mu
sigma_tiled = sigma
c_part = (std_normal + mu_tiled) * sigma_tiled
return c_part, z_part, mu ,log_var
def spatial_replication(self, input, height, width):
# input [batch, 128]
# output [batch, height, width, 128]
before_tiled = tf.expand_dims(tf.expand_dims(input, -1), -1)
input_tiled = tf.tile(before_tiled, [1, 1, height, width])
return tf.transpose(input_tiled, [0, 2, 3, 1])
def get_corr_tensor(self, height, width):
height_part = tf.expand_dims(tf.tile(tf.expand_dims(tf.tile(tf.expand_dims(tf.range(height, dtype=tf.float32), dim=0), [width, 1]), dim=0), [self.batch_size, 1, 1]), dim=-1)
width_part = tf.expand_dims(tf.tile(tf.expand_dims(tf.tile(tf.expand_dims(tf.range(width, dtype=tf.float32), dim=0), [height, 1]), dim=0), [self.batch_size, 1, 1]), dim=-1)
width_part = tf.transpose(width_part, [0, 2, 1, 3])
req = tf.concat([height_part, width_part], axis=-1)
return req
def add_corr_tensor(self, input):
height = int(input.get_shape()[1])
width = int(input.get_shape()[2])
return tf.concat([input, self.get_corr_tensor(height, width)], axis=-1)
def stackgan_I_generator(self, cz_part):
# resize
with tf.variable_scope("stackI_up"):
cz_resize = tf.reshape(tf.layers.dense(inputs=cz_part, units=4 * 4 * 1024, name="cz_dense_layer"),
[-1, 4, 4, 1024])
cz_resize = self.add_corr_tensor(cz_resize)
up1 = tf.layers.conv2d_transpose(inputs=cz_resize, filters=512, strides=(2, 2),
kernel_size=3,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up1")
up1 = tf.nn.leaky_relu(tf.layers.batch_normalization(up1
, training=self.is_training,
name="norm1"))
up1 = self.add_corr_tensor(up1)
up2 = tf.layers.conv2d_transpose(inputs=up1, filters=256, strides=(2, 2),
kernel_size=3,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up2")
up2 = tf.nn.leaky_relu(tf.layers.batch_normalization(up2
, training=self.is_training,
name="norm2"))
up2 = self.add_corr_tensor(up2)
up3 = tf.layers.conv2d_transpose(inputs=up2, filters=128, strides=(2, 2),
kernel_size=3,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="up3")
up3 = tf.nn.leaky_relu(tf.layers.batch_normalization(up3
, training=self.is_training,
name="norm3"))
up3 = self.add_corr_tensor(up3)
upsampling_cz = tf.layers.conv2d_transpose(inputs=up3, filters=3, strides=(2, 2),
kernel_size=3,
padding="SAME",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
), name="upsampling_cz")
upsampling_cz = tf.nn.leaky_relu(tf.layers.batch_normalization(upsampling_cz
, training=self.is_training,
name="norm4"))
upsampling_cz = tf.nn.sigmoid(upsampling_cz)
return upsampling_cz
def stackgan_I_discriminator(self, generator_input, text_input):
# generator input [batch, 64, 64, 3]
# text input
with tf.variable_scope("stackI_down", reuse=tf.AUTO_REUSE):
# [batch, 32, 32, 128]
generator_input = self.add_corr_tensor(generator_input)
down_1 = tf.layers.conv2d(generator_input, filters=128, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackI_down1",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_1 = tf.nn.leaky_relu(down_1
)
# [batch, 16, 16, 256]
down_1 = self.add_corr_tensor(down_1)
down_2 = tf.layers.conv2d(down_1, filters=256, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackI_down2",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_2 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_2
, training=self.is_training,
name="norm2", reuse=tf.AUTO_REUSE))
# [batch, 8, 8, 512]
down_2 = self.add_corr_tensor(down_2)
down_3 = tf.layers.conv2d(down_2, filters=512, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackI_down3",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_3 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_3
, training=self.is_training,
name="norm3",
reuse=tf.AUTO_REUSE))
# [batch, 4, 4, 1024]
down_3 = self.add_corr_tensor(down_3)
down_4 = tf.layers.conv2d(down_3, filters=1024, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackI_down4"
, reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_4 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_4
, training=self.is_training,
name="norm4",
reuse=tf.AUTO_REUSE))
# down4 used to fuse with text feature
# text_input [batch, 4, 4, 128]
# text_with_image[batch, 4, 4, 1024 + 128]
text_with_image = tf.concat([down_4, text_input], axis=-1)
return text_with_image
def stackgan_II_generator(self, generator_input, text_input):
# generator_input [batch, 64, 64, 3]
with tf.variable_scope("stackII_down"):
# [batch, 32, 32, 256]
generator_input = self.add_corr_tensor(generator_input)
down_1 = tf.layers.conv2d(generator_input, filters=128, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down1",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_1 = tf.nn.leaky_relu(down_1
)
# [batch, 16, 16, 512]
down_1 = self.add_corr_tensor(down_1)
down_2 = tf.layers.conv2d(down_1, filters=512, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down2",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_2 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_2
, training=self.is_training,
name="norm2"))
# text_input [batch, 16, 16, 128]
# text_with_image[batch, 16, 16, 512 + 128]
text_with_image = tf.concat([down_2, text_input], axis=-1)
# res block part
filters = int(text_with_image.get_shape()[-1])
residual_block = tf.layers.conv2d(inputs=text_with_image, filters=filters, strides=(1, 1),
kernel_size=3,
padding="SAME", name="res1",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
residual_block = tf.nn.leaky_relu(residual_block
)
residual_block = tf.layers.conv2d(inputs=residual_block, filters=filters, strides=(1, 1),
kernel_size=3,
padding="SAME", name="res2",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
residual_block = residual_block + text_with_image
# [batch, 16, 16, 512 + 128]
residual_block = tf.nn.leaky_relu(residual_block
)
# reduce dim of residual_block
residual_block = self.add_corr_tensor(residual_block)
residual_block_proj = tf.layers.conv2d(residual_block, filters = 25, strides=(1, 1),
kernel_size=1, padding="SAME",
name="residual_block_proj",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
with tf.variable_scope("stackII_up"):
resize = tf.reshape(tf.layers.dense(inputs=tf.reshape(residual_block_proj, [self.batch_size, 16 * 16 * 25]), units=128 * 128, name="cz_dense_layer"),
[-1, 128, 128, 1])
resize = self.add_corr_tensor(resize)
up1 = tf.layers.conv2d_transpose(inputs=resize, filters=3, strides=(1, 1),
kernel_size=3,
padding="SAME", name="up1",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
up1 = tf.nn.leaky_relu(tf.layers.batch_normalization(up1
, training=self.is_training,
name="norm1"))
up1 = self.add_corr_tensor(up1)
up2 = tf.layers.conv2d_transpose(inputs=up1, filters=3, strides=(2, 2),
kernel_size=3,
padding="SAME", name="up2",
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
# [batch, 256, 256, 3]
up2 = tf.nn.leaky_relu(tf.layers.batch_normalization(up2
, training=self.is_training,
name="norm2"))
up2 = tf.nn.sigmoid(up2)
return up2
def stackgan_II_discriminator(self, generator_input, text_input):
# generator input [batch, 256, 256, 3]
# text input
with tf.variable_scope("stackII_down", reuse=tf.AUTO_REUSE):
# [batch, 128, 128, 32]
generator_input = self.add_corr_tensor(generator_input)
down_1 = tf.layers.conv2d(generator_input, filters=32, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down1",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_1 = tf.nn.leaky_relu(down_1
)
# [batch, 64, 64, 64]
down_1 = self.add_corr_tensor(down_1)
down_2 = tf.layers.conv2d(down_1, filters=64, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down2",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_2 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_2
, training=self.is_training,
name="norm2",
reuse=tf.AUTO_REUSE))
# [batch, 32, 32, 128]
down_2 = self.add_corr_tensor(down_2)
down_3 = tf.layers.conv2d(down_2, filters=128, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down3",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_3 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_3
, training=self.is_training,
name="norm3",
reuse=tf.AUTO_REUSE))
# [batch, 16, 16, 256]
down_3 = self.add_corr_tensor(down_3)
down_4 = tf.layers.conv2d(down_3, filters=256, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down4",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_4 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_4
, training=self.is_training,
name="norm4",
reuse=tf.AUTO_REUSE))
# [batch, 8, 8, 512]
down_4 = self.add_corr_tensor(down_4)
down_5 = tf.layers.conv2d(down_4, filters=512, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down5",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_5 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_5
, training=self.is_training,
name="norm5",
reuse=tf.AUTO_REUSE))
# [batch, 4, 4, 1024]
down_5 = self.add_corr_tensor(down_5)
down_6 = tf.layers.conv2d(down_5, filters=1024, strides=(2, 2),
kernel_size=4, padding="SAME", name="stackII_down6",
reuse=tf.AUTO_REUSE,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.01
))
down_6 = tf.nn.leaky_relu(tf.layers.batch_normalization(down_6
, training=self.is_training,
name="norm6",
reuse=tf.AUTO_REUSE))
# down4 used to fuse with text feature
# text_input [batch, 4, 4, 128]
# text_with_image[batch, 4, 4, 1024 + 128]
text_with_image = tf.concat([down_6, text_input], axis=-1)
return text_with_image
def compute_single_bce(self, D_text_with_image, labels, W, b):
# flatten D_text_with_image
D_feature_flatten = tf.reshape(D_text_with_image, [self.batch_size, -1])
logits = tf.nn.xw_plus_b(D_feature_flatten, W, b)
bce_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))
return logits ,bce_loss
def model_construct(self):
with tf.variable_scope("stage_I"):
# c_part may be reused
c_part, z_part, mu ,log_var = self.cz_layer(self.std_normal_I, self.z_part_I)
kl_loss_I = get_KL_Loss(mu, log_var)
spatial_replication_input = tf.layers.dense(c_part, units=128, name="spatial_replication_input")
# [batch, 4, 4, 128]
spatial_replication_input_I = self.spatial_replication(spatial_replication_input, height=4, width=4)
self.c_part = c_part
self.z_part = z_part
cz_part = tf.concat([c_part, z_part], axis=-1, name="cz_part")
# first layer generator output [batch, 64, 64, 3]
upsampling_cz_I = self.stackgan_I_generator(cz_part)
self.output_I = upsampling_cz_I
with tf.variable_scope("discriminator"):
# [batch, 4, 4, 1024 + 128]
D_text_with_image_I_false = self.stackgan_I_discriminator(upsampling_cz_I, spatial_replication_input_I)
D_text_with_image_I_true = self.stackgan_I_discriminator(self.true_image_input_64, spatial_replication_input_I)
self.D_text_with_image_I_false = D_text_with_image_I_false
self.D_text_with_image_I_true = D_text_with_image_I_true
logits1 ,bce_I_one_false = self.compute_single_bce(D_text_with_image_I_false, tf.ones([self.batch_size, 1]), self.W1, self.b1)
self.false_one_logits_I = tf.nn.sigmoid(logits1)
logits2 ,bce_I_zero_false = self.compute_single_bce(D_text_with_image_I_false, tf.zeros([self.batch_size, 1]), self.W1, self.b1)
self.false_zero_logits_I = tf.nn.sigmoid(logits2)
logits3 ,bce_I_one_true = self.compute_single_bce(D_text_with_image_I_true, tf.ones([self.batch_size, 1]), self.W1, self.b1)
self.true_one_logits_I = tf.nn.sigmoid(logits3)
with tf.variable_scope("stage_II"):
c_part, z_part, mu ,log_var = self.cz_layer(self.std_normal_II, self.z_part_II)
kl_loss_II = get_KL_Loss(mu, log_var)
spatial_replication_input = tf.layers.dense(c_part, units=128, name="spatial_replication_input")
# [batch, 16, 16, 128]
spatial_replication_input_II = self.spatial_replication(spatial_replication_input, height=16, width=16)
# [batch, 256, 256, 3]
upsampling_cz_II = self.stackgan_II_generator(generator_input=upsampling_cz_I, text_input=spatial_replication_input_II)
self.output_II = upsampling_cz_II
with tf.variable_scope("discriminator"):
# [batch, 4, 4, 1024 + 128]
D_text_with_image_II_false = self.stackgan_II_discriminator(upsampling_cz_II, spatial_replication_input_I)
D_text_with_image_II_true = self.stackgan_II_discriminator(self.true_image_input_256, spatial_replication_input_I)
logits ,bce_II_one_false = self.compute_single_bce(D_text_with_image_II_false, tf.ones([self.batch_size, 1]), self.W2, self.b2)
self.false_one_logits_II = tf.nn.sigmoid(logits)
logits ,bce_II_zero_false = self.compute_single_bce(D_text_with_image_II_false, tf.zeros([self.batch_size, 1]), self.W2, self.b2)
self.false_zero_logits_II = tf.nn.sigmoid(logits)
logits ,bce_II_one_true = self.compute_single_bce(D_text_with_image_II_true, tf.ones([self.batch_size, 1]), self.W2, self.b2)
self.true_one_logits_II = tf.nn.sigmoid(logits)
return bce_I_one_false, bce_I_zero_false, bce_I_one_true, bce_II_one_false, bce_II_zero_false, bce_II_one_true, \
kl_loss_I, kl_loss_II
def train_opt_construct(self):
bce_I_one_false, bce_I_zero_false, bce_I_one_true, bce_II_one_false, bce_II_zero_false, bce_II_one_true, \
kl_loss_I, kl_loss_II = self.model_construct()
self.assign_vars_to_list()
self.d_optim_I_loss = bce_I_one_true + bce_I_zero_false
self.d_optim_I = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.d_optim_I_loss, var_list=self.d_vars_I)
self.g_optim_I_loss = bce_I_one_false + self.lambda_val * kl_loss_I
self.g_optim_I = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.g_optim_I_loss, var_list=self.g_vars_I)
self.d_optim_II_loss = bce_II_one_true + bce_II_zero_false
self.d_optim_II = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.d_optim_II_loss, var_list=self.d_vars_II)
self.g_optim_II_loss = bce_II_one_false + self.lambda_val * kl_loss_II
self.g_optim_II = tf.train.AdamOptimizer(0.0002, beta1=0.5) \
.minimize(self.g_optim_II_loss, var_list=self.g_vars_II)
@staticmethod
def update_model(sess ,model, input_data_dict, debug = False,
batch_size = 8, z_dim = 100, c_dim = 100,
step = 0):
from PIL import Image
import uuid
def visualize_output(single_output_array, pic = "1"):
img = Image.fromarray((single_output_array * 255).astype(np.uint8), mode=None)
with open(r"C:\tempCodingUsage\python\StudyGAN\pic_{}\{}.jpg".format(pic ,uuid.uuid1()), "wb") as f:
img.save(f)
std_normal_I = standard_normal_random(batch_size, c_dim)
z_part_I = standard_normal_random(batch_size, z_dim)
std_normal_II = standard_normal_random(batch_size, c_dim)
z_part_II = standard_normal_random(batch_size, z_dim)
_, g_optim_I_loss = sess.run([model.g_optim_I, model.g_optim_I_loss],
feed_dict = {
model.mu_sigma_preduce_array: input_data_dict["mu_sigma_preduce_array"],
model.true_image_input_256: input_data_dict["true_image_input_256"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
model.z_part_II: z_part_II,
model.std_normal_I: std_normal_I,
model.std_normal_II: std_normal_II
})
_, d_optim_I_loss = sess.run([model.d_optim_I, model.d_optim_I_loss
],
feed_dict = {
model.mu_sigma_preduce_array: input_data_dict["mu_sigma_preduce_array"],
model.true_image_input_256: input_data_dict["true_image_input_256"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
model.z_part_II: z_part_II,
model.std_normal_I: std_normal_I,
model.std_normal_II: std_normal_II
})
_, g_optim_II_loss = sess.run([model.g_optim_II, model.g_optim_II_loss],
feed_dict = {
model.mu_sigma_preduce_array: input_data_dict["mu_sigma_preduce_array"],
model.true_image_input_256: input_data_dict["true_image_input_256"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
model.z_part_II: z_part_II,
model.std_normal_I: std_normal_I,
model.std_normal_II: std_normal_II
})
_, d_optim_II_loss = sess.run([model.d_optim_II, model.d_optim_II_loss],
feed_dict = {
model.mu_sigma_preduce_array: input_data_dict["mu_sigma_preduce_array"],
model.true_image_input_256: input_data_dict["true_image_input_256"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
model.z_part_II: z_part_II,
model.std_normal_I: std_normal_I,
model.std_normal_II: std_normal_II
})
false_one_logits_I, false_zero_logits_I, \
true_one_logits_I, \
false_one_logits_II, false_zero_logits_II, \
true_one_logits_II, \
D_text_with_image_I_false, \
D_text_with_image_I_true, \
output_I, output_II, \
= sess.run([model.false_one_logits_I, model.false_zero_logits_I,
model.true_one_logits_I,
model.false_one_logits_II, model.false_zero_logits_II,
model.true_one_logits_II,
model.D_text_with_image_I_false,
model.D_text_with_image_I_true,
model.output_I,
model.output_II,
],
feed_dict = {
model.mu_sigma_preduce_array: input_data_dict["mu_sigma_preduce_array"],
model.true_image_input_256: input_data_dict["true_image_input_256"],
model.is_training: input_data_dict["is_training"],
model.z_part_I: z_part_I,
model.z_part_II: z_part_II,
model.std_normal_I: std_normal_I,
model.std_normal_II: std_normal_II
})
percentiles = np.array([0.1 ,0.25, 0.5, 0.75, 0.9])
ptiles_vers_false = np.percentile(false_one_logits_I, percentiles)
if debug:
print("false_one_logits_I ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_false = np.percentile(false_zero_logits_I, percentiles)
if debug:
print("false_zero_logits_I ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_true = np.percentile(true_one_logits_I, percentiles)
if debug:
print("true_one_logits_I ptiles_vers :")
print(ptiles_vers_true)
ptiles_vers_output = np.percentile(output_I, percentiles)
if debug:
print("output_I ptiles_vers :")
print(ptiles_vers_output)
print("-" * 100)
ptiles_vers_false = np.percentile(false_one_logits_II, percentiles)
if debug:
print("false_one_logits_II ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_false = np.percentile(false_zero_logits_II, percentiles)
if debug:
print("false_zero_logits_II ptiles_vers :")
print(ptiles_vers_false)
ptiles_vers_true = np.percentile(true_one_logits_II, percentiles)
if debug:
print("true_one_logits_II ptiles_vers :")
print(ptiles_vers_true)
ptiles_vers_output = np.percentile(output_II, percentiles)
if debug:
print("output_II ptiles_vers :")
print(ptiles_vers_output)
print("-" * 100)
if (np.mean(ptiles_vers_true) > 0.9 and np.mean(ptiles_vers_false) > 0.5):
visualize_output(output_I[0], pic="61")
visualize_output(output_II[0], pic="61")
elif step % 100 == 0:
visualize_output(output_I[0], pic="62")
visualize_output(output_II[0], pic="62")
return d_optim_I_loss, g_optim_I_loss, d_optim_II_loss, g_optim_II_loss, (np.mean(ptiles_vers_true) > 0.9 and np.mean(ptiles_vers_false) > 0.5)
@staticmethod
def train():
import os
from data_process.data_loader import batch_loader
batch_size = 8
train_gen = batch_loader(batch_size, zero_rnn=False)
model = StackGAN(batch_size=batch_size)
saver = tf.train.Saver()
sess = tf.Session()
if os.path.exists(r"C:\tempCodingUsage\python\StudyGAN\stack_gan.index"):
saver.restore(sess, r"C:\tempCodingUsage\python\StudyGAN\stack_gan")
print("exist")
else:
sess.run(tf.global_variables_initializer())
print("init new")
print("model init end")
step = 0
epoch = 0
while True:
input_data = train_gen.__next__()
if input_data is None:
epoch += 1
continue
step += 1
img_f, rnn_f = input_data
input_data = {
"true_image_input_256": img_f ,
"mu_sigma_preduce_array": rnn_f,
"is_training": True
}
d_optim_I_loss, g_optim_I_loss, d_optim_II_loss, g_optim_II_loss, save_conclusion = StackGAN.update_model(sess, model, input_data,
debug=step % 10 == 0,
step = step)
if step % 10 == 0:
print("epoch: {} step: {}".format(epoch ,step))
print(d_optim_I_loss, g_optim_I_loss, d_optim_II_loss, g_optim_II_loss)
sess.close()
if __name__ == "__main__":
StackGAN.train()