A paper a day keeps trouble away
论文地址:https://arxiv.org/abs/1612.03242
论文GitHub: https://github.com/hanzhanggit/StackGAN

在先前的CGAN中,我们将描述文本作为条件分别输入生成器和判别器,用来实现Text-to-Image。但是通常得到的图像都是只包含了描述文本中的基本特征,并不能很好地表现出文本中的细节部分,因此分辨率很低。那么如何根据一段描述性文本生成一张高分辨率的图像呢?这就是本文stackGAN所要做的事,它可以根据给定的描述文本,生成一张
256×256 的高分辨率的图像。
它采用了一种逐步递进的思想,将高分辨率图像的生成分为两个阶段来操作。首先在第一个阶段描绘出图像的基本轮廓和相关的颜色分布;第二阶段根据给定的文本和第一阶段生成的低分辨率图像,纠正低分辨率图像中的缺陷,并添加更多的细节,使的生成的图像更接近真实,分辨率更高。
同时为了提高生成图像的多样性,加强训练过程的稳定性,作者还提出了一种新的条件增强技术。通过多个实验证明,stackGAN在多个数据集上的效果都由于其他的GANs。
贡献
作者指出本文的贡献主要在以下三个方面:
- 提出了stackGAN,实现了根据描述性文本生成高分辨率图像
- 提出了一种新的条件增强技术,增强训练过程的稳定性、增加生成图像的多样性
- 通过多个实验证明了整体模型以及部分构件的有效性,为后面的模型构建提供了有益信息
stackGAN
stackGAN 将Text-to-Image这项工作分为了两个阶段来执行:
- Stage-I GAN:根据给定的文本描绘出主要的形状和基本颜色组合;并从随机噪声向量中绘制背景布局,生成低分辨率图像
- Stage-II GAN:修正第一阶段生成的低分辨率图像中的不足之处,再添加一些细节部分,生成高分辨率图像
下面我们来看一它的架构:
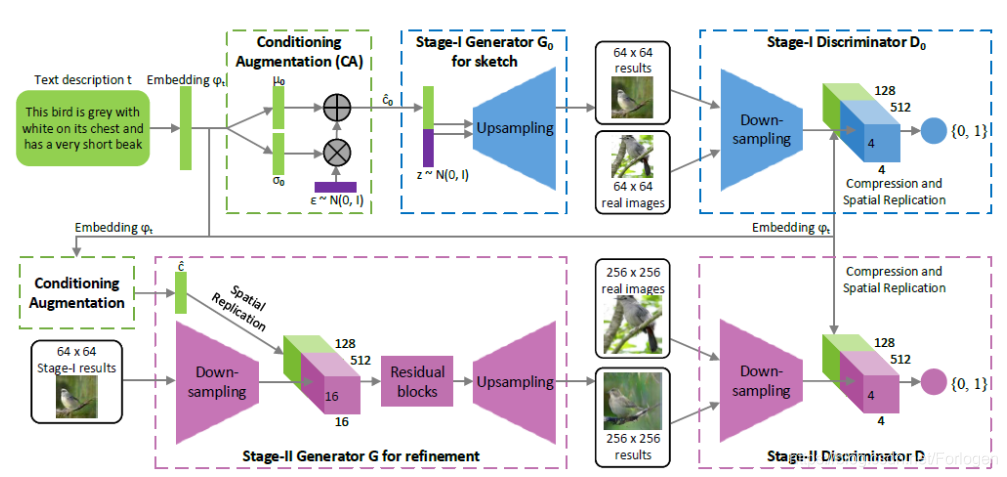
就目前所看的论文,可将其看做是VAE和CGAN的一种结合的技术 ,通过不同的网络架构来实现具体的功能。
条件增强技术
在此之前,先来看一下它所提出的条件增强技术是怎么回事。如上图所示,在第一阶段开始时刻,文本描述
t 首先被一个encoder编码,生成一个文本嵌入
ψt中。在这篇文章之前处理这个问题的方法通常是将其非线性的转换成条件的潜在变量输入到G中,但是这样做有一个很大的问题,通过因为潜在变量所在的空间维度很高,在数据量有限的情况下,它会造成数据的不连续性。
所以为了缓解这个问题,作者提出了一种新的条件增强技术,它会利用
ψt 生成一个新的条件标量
c^ ,代替
ψt输入到G中。其中
c^ 是从
N(μ(ψt),Σ(ψt)) 中随机采样得到。为了进一步的增强多样性以及避免过拟合的出现,这里作者还添加了如下的正则化项:
DKL(N(μ(ψt),Σ(ψt))∣∣N(0,I))
它代表了我们随机采样的高斯分布和标准高斯分布之间的KL散度,这样做有利于建模,根据一段固定的描述生成更多样性的图像。
公式化理解
下面我们通过公式来理解一下它的整个过程。我们知道在 Vanilla GAN中它的目标函数为:
GminDmaxV(G,D)=Ex∼pdata(x)logD(xi)+Ex∼pz(z)log(1−D(G(zi)))
那么CGAN在此基础上做了改进,对于G和D都添加了一个条件
y ,使其可以根据条件生成指定的图像,目标函数为:
GminDmaxV(G,D)=Ex∼pdata(x)logD(xi∣y)+Ex∼pz(z)log(1−D(G(zi∣y)))
那么在stackGAN的第一阶段,
G0 和
D0 的目标函数如下所示,和Vanilla GAN中的思想是一致的,即G生成更逼真的低分辨率图像,D尽可能的判别出真实图像和生成图像
LD0=E(I0,t)∼pdata[logD0(I0,ψt)]+Ez∼pz,t∼pdata[log(1−d0(G0(z,c^0),ψt))]
LG0=Ez∼pz,t∼pdata[log(1−D0(G0(z,c^0),ψt))]+λDKL(N(μ0(ψt),Σ0(ψt))∣∣N(0,I))
其中
I 表示真实图像,
λ 这里是一个正则化系数,平衡
LG0 中的两项。那么自然G的目标是
minLG0 ,D的目标是
maxLD0 。
在stackGAN的第二阶段,根据第一阶段的输出和描述文本,完成低分辨率图像中忽略的细节部分,生成更接近真实的高分辨率图像,这里将第一阶段的输出记为
s0=G0(z,c^0),那么对于第二阶段的G和D来说,同样的思想,它们的目标函数为:
LD=E(I,t)∼pdata[logD(I,ψt)]+Es0∼pG0,t∼pdata[log(1−D(G(s0,c^0),ψt))]
LG=Es0∼pG0,t∼pdata[log(1−D(G(s0,c^0),ψt))]+λDKL(N(μ(ψt),Σ(ψt))∣∣N(0,I))
这里在G的输入中并没有噪声
z ,是因为假设在第一阶段的输出
s0 保存了之前输入的噪声信息。其中
c^0 和
ψt 和第一阶段中使用的相同,但是通过不同的网络架构来产生不同的高斯分布中的均值和标准差。它的目标同样是G要
minLG ,D要
maxLD
具体的G和D中的网络架构如上图所示,详细的配置可见原论文。
实验
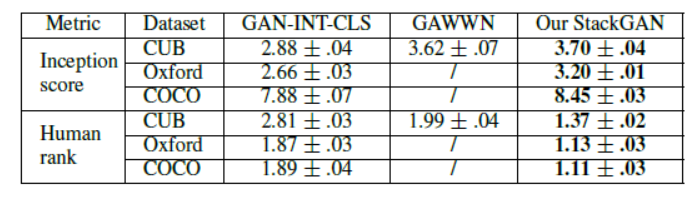
为了进行效果的对比,作者这里选择了之前实现Text-to-Image的两个相关方法GAN-INT-CLS和GAWWN进行比较。另外设计实验证明了stackGAN各部分的有效性,以及验证了在每个阶段输入文本的必要性。
使用了如下两个评估方式:
例如根据文本生成鸟的图像,实验结果如下

从中我们可以看出stackGAN生成的图像更加的真实、清晰,更加符合文本的描述。而且从定量评估来看,stackGAN相比于其他的模型,它的inception score和Human rank得分更高,同样可以证明它的效果要优于其他的方法。
在评估stackGAN各成分的重要行的实验中,我们可以看出,使用了条件增强技术的GAN,生成的图像更加的多样性,更加的符合真实情况。

另外针对不同的阶段使用使用CA,以及是否给G和D文本信息也做了实验,结果如下所示
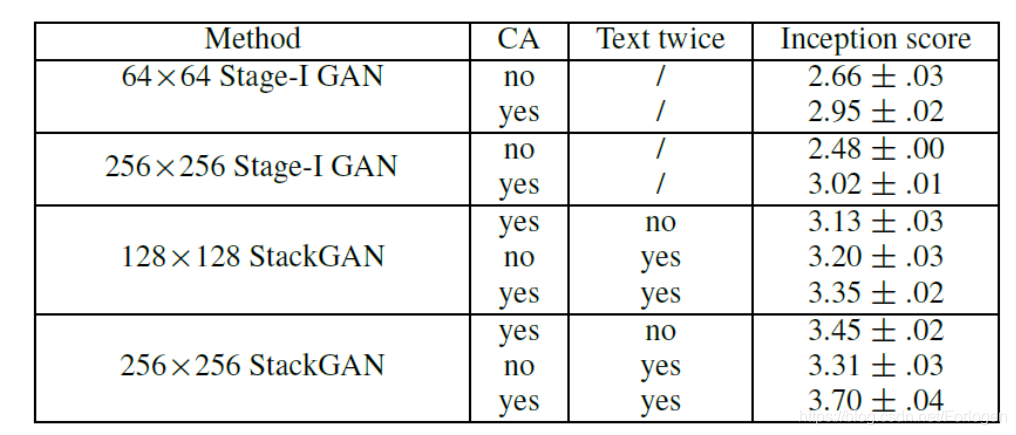
从中我们可以清晰的看出使用CA和对G和D都输入文本会很好的提升模型的效果。但是作者同时提出,如果我们stackGAN仅仅是增大图像的尺寸,而不增加额外的信息,则inception score会保持在一个值附近。
更多的实验结果可见原论文。
P.S.纯属个人理解,如有不对还望斧正,谢谢~~