Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
简述:
从文本描述中合成高质量的图像是计算机视觉中的一个具有挑战性的问题,具有许多实际应用。现有的文本-图像方法生成的样本可以大致反映给定描述的含义,但无法包含必要的细节和生动的对象部分。在这篇论文中,我们提出堆叠式生成性对抗网路(StackGAN),以文字为条件,产生256×256的真实感影像。通过草图细化过程(sketch-refinement process),我们将难题分解为更易于人理解的子问题。
下图中,展示了Stage-I GAN和Stage-II GAN 的效果图,可以看出Stage-I GAN仅包含了一下low-level特征,生成64x64 images。Stage-II GAN以Stage-I GAN的结果和文本描述作为输入,生成具有照片般逼真细节的高分辨率图像,并在细化过程中添加整合细节,生成256x256 images。
为了提高合成图像的多样性,以及为了稳定C-GAN的训练,我们引入了一种新的条件增强技术(Conditioning Augmentation technique),使潜在条件集(latent conditioning manifold)更加平滑。

本文有以下3个贡献:
(1)提出了一种新颖的Stacked-GAN网络,用于从文本描述合成逼真的图像。它将生成高分辨率图像的难题分解为更易于管理的子问题,并极大地改善了技术状态。StackGAN第一次从文本描述中生成256×256分辨率的图像,具有逼真的细节。
(2)提出了一种新的条件增强技术,稳定了C-GAN的训练,提高了生成样本的多样性。
(3)通过大量的定性和定量实验,验证了整体模型设计的有效性以及各组分的作用,为未来C-GAN模型的设计提供了有益的信息。
问题or相关工作:
条件作用增强(CA):
文本嵌入的潜在空间通常是高维的,在数据量有限的情况下,常引起潜数据流形的不连续性,因此G不能很好的适应,为了解决这个问题,我们引入了条件增强技术来产生额外的条件变量c,以标准高斯分布和正态高斯分布之间的KL散度这一正则化项添加到G的目标中:
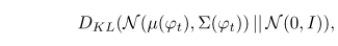
模型:
为了生成具有真实感细节的高分辨率图像,我们提出了一种简单而有效的叠加广义对抗网络。分为以下两个部分:
1.Stage-I GAN: 根据给定的文本描述,绘制对象的原始形状和原始颜色,并从随机噪声向量中绘制背景布局,生成低分辨率图像。
Stage I GAN通过交替最大化LD0和最小化LG0来训练鉴别器D0和生成器G0:
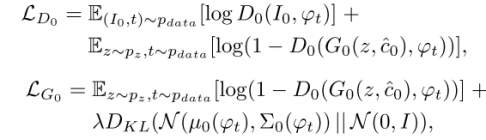
其中,与固定条件文本变量c相比,我们从独立的高斯分布N((ϕt),Σ(ϕt))中随机采样潜在变量ˆc ,其中均值µ(ϕt) 和对角协方差矩阵Σ(ϕt)是文本嵌入ϕt的函数表示。真实图像I0和文本描述t来自真实的数据分布pdata。z是随机采样自给定分布的噪声矢量pz(本文为高斯分布)。λ是一个正则化参数,平衡这两个术语在Eq(文中经试验求得λ=1)。
**2.Stage-II GAN:**修正了第一阶段低分辨率图像的缺陷,通过再次读取文本描述来完成对象的细节,生成了高分辨率的真实感图像。
在低分辨率结果s0 = G0(z,c0)和高斯潜变量ˆc的条件下,通过交替最大化方程中的LD和最小化等式中的LG来训练Stage-II GAN中的鉴别器D和生成器G。
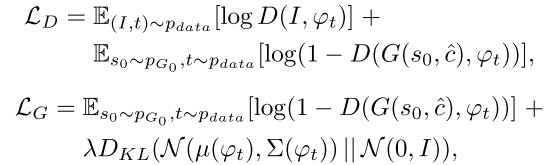
与原始的GAN公式不同的是,本阶段没有使用随机噪声z,假设随机度已经被s0保留。其中ˆc与stage 1中的ˆc权值共享,从而有相同的文本嵌入,但与stage 1中的全连接层不同,从而产生不同的均值和标准差,通过这种方式,第二阶段GAN学会了在文本嵌入中捕捉有用的信息,而第一阶段GAN忽略了这些信息。
3.module:
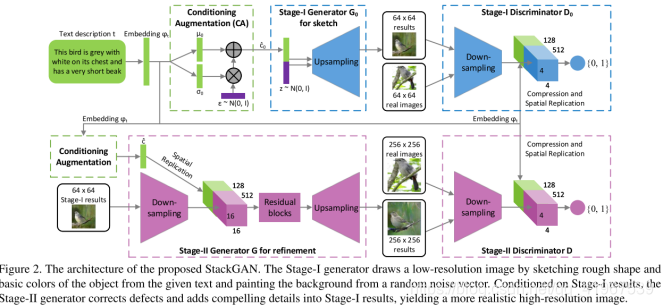
3.1 stage I,首先是一个CA(调节增强技术)模块,stackGAN 没有直接将 embedding 作为 condition ,而是用 embedding 接了一个 FC 层从得到的独立的高斯分布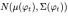 中随机采样得到高斯条件变量(
中随机采样得到高斯条件变量( 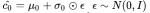 )。其中
)。其中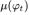 和
和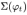 是关于
是关于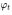 的函数。之所以这样做的原因是,embedding 通常比较高维,而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个 latent variable 在 latent space 里就比较稀疏,这对训练不利。(其实可以简单理解为对词嵌入进行降维)。
的函数。之所以这样做的原因是,embedding 通常比较高维,而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个 latent variable 在 latent space 里就比较稀疏,这对训练不利。(其实可以简单理解为对词嵌入进行降维)。
输入到生成器中的是经过Conditioning Augmentation之后的高斯条件变量ˆc和噪声向量z经过级联得到的一组向量,然后,经过上采样之后生成一张64×64的图像。
判别器D0:首先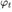 经过一个全连接层被压缩到Nd维,然后经过空间复制将其扩成一个
经过一个全连接层被压缩到Nd维,然后经过空间复制将其扩成一个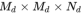 的张量。同时,图像会经过一系列的下采样到
的张量。同时,图像会经过一系列的下采样到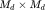 。然后,图像过滤映射会连接图像和文本张量的通道。随后张量会经过一个1×1的卷积层去连接跨文本和图像学到的特征。最后,会通过只有一个节点的全连接层去产生图像真假的概率。
。然后,图像过滤映射会连接图像和文本张量的通道。随后张量会经过一个1×1的卷积层去连接跨文本和图像学到的特征。最后,会通过只有一个节点的全连接层去产生图像真假的概率。
3.2 stage II,生成器G:Stage-II生成器设计为带有剩余块的编码器-解码器网络。 Stage-I GAN生成的64×64的图片,加上对词嵌入进行CA操作得到的高斯条件变量ˆc,与前一个阶段相似,ˆc然后被扩成一个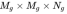 的张量(绿色部分)。同时,由前一个GAN生成的64×64的图像会经过下采样变成
的张量(绿色部分)。同时,由前一个GAN生成的64×64的图像会经过下采样变成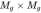 (16*16)(紫色部分)。图像特征和文本特征连接起来后经过residual blocks(学习图像和文本的多模型表示),上采样生成图片。
(16*16)(紫色部分)。图像特征和文本特征连接起来后经过residual blocks(学习图像和文本的多模型表示),上采样生成图片。
判别器D:和阶段一差不多,只是由于这个部分图像的尺寸更大,所以有额外的一系列下采样块。为了显式地增强GAN以更好地学习图像和条件文本之间的对齐,我们采用了Reed等人提出的匹配感知判别器,而不是普通的判别器。在训练过程中,鉴别器将真实图像及其对应的文本描述作为正样本对,而负样本对由两组组成。第一种是具有不匹配文本嵌入的真实图像,而第二种是具有相应文本嵌入的合成图像。
成果:
生成模型(如GAN)的性能很难评价。我们选择了一个最近提出的数值评估方法,先启评分(inception score)进行定量评估:
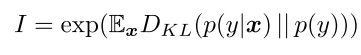
其中x表示生成的一个样本,y是Inception模型预测的标签。这个度量的意思是,好的模型应该生成各种各样但有意义的图像,因此,边际分布p(y)与条件分布p(y|x)的KL散度应该很大。
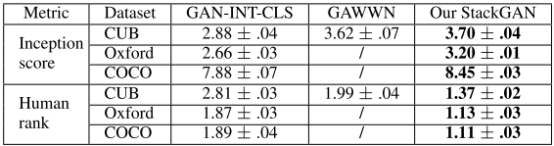
下图是StackGAN、GAWWN[24]和GAN-INT-CLS根据CUB测试集的文本描述提供示例结果及具体度量结果:

下图是Stage两个阶段生成图像对比:

对于每个生成的图像,从训练集中检索其最近的邻居,可以得出这样的结论:生成的图像与训练样本有一些相似的特征,但本质上是不同的。下图是实验结果:

条件强化法(CA)有助于稳定C-GAN的训练,提高培养样品的多样性:

为了更好的展示StackGAN的作用,实验中在句中嵌入插值信息,下图中上层展示了一些如颜色等简单的信息,下图展示了如眼睛颜色,羽毛颜色等复杂的语义信息。

