前言:淘宝网是中国 阿里巴巴集团旗下网络购物网站,由马云创立于2003年5月10日,是面向中国大陆、香港、澳门、台湾的消费者与马来西亚之C2C购物网站。淘宝有一些反爬的手段,让人有点伤脑筋。我经过资料收集整理和分析,下面开始讲解如何开始淘宝爬虫。
对于这种反爬措施比较严重的网站,要想能正常获取信息,个人认为最好要模拟登录,获得cookies。不然很容易,因为滑块验证之类的东西给困住。
一、淘宝登录
1.进入淘宝登录界面
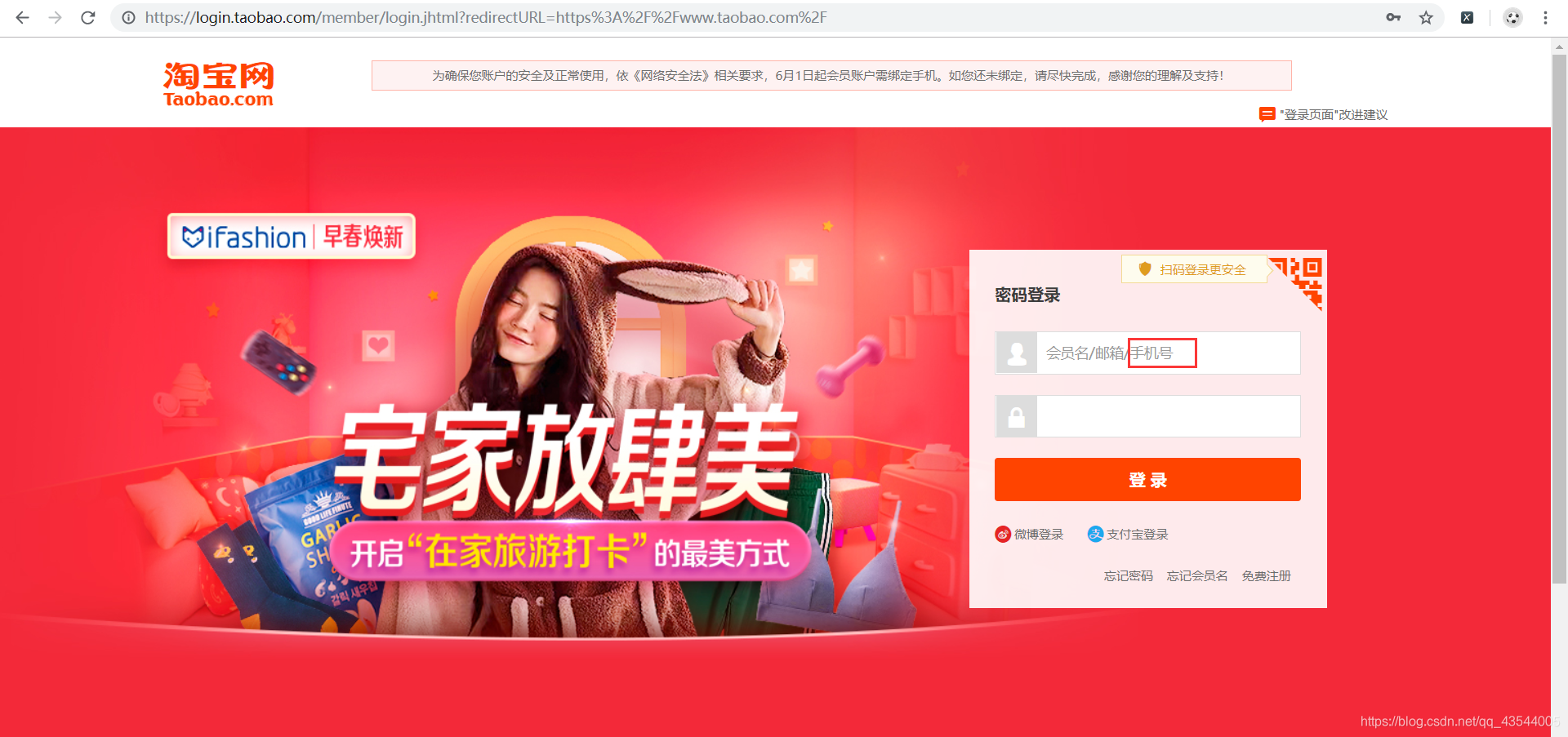
我们可以采用 用手机号作为账号的方式登陆
在代码层面分析登录淘宝的四个流程:
1.输入用户名后,浏览器会向淘宝(taobao.com)发起一个post的请求,判断是否出现滑块验证。
检验是否出现滑块验证的请求网址:`
‘https://login.taobao.com/member/request_nick_check.do?_input_charset=utf-8’`
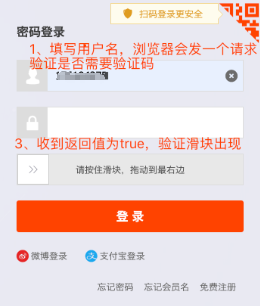
2.用户输入密码后,浏览器向淘宝(taobao.com)又发起一个post请求,验证用户名密码是否正确,如果正确则返回一个token。
验证密码和账号是否正确的请求网址:https://login.taobao.com/member/login.jhtml
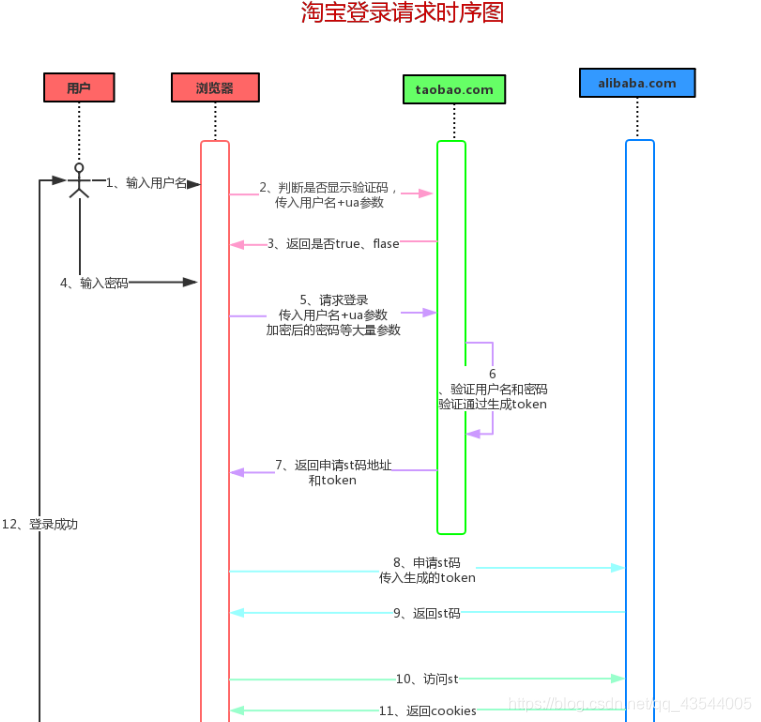
3.浏览器拿着token去阿里巴巴(alibaba.com)交换st码。
4.浏览器获取st码之后,拿着st码获取cookies,登录成功。
获取cookies的请求网址:https://login.taobao.com/member/vst.htm?st={}
到这里也许你可能会有疑问:为什么淘宝登录需要这么麻烦呢?直接在 taobao.com 登录不就可以吗?为什么要先在taobao验证用户名密码,通过之后还要去 alibaba.com 换取st码登录?
任何公司都是由小到大,最开始成立互联网公司框架也在慢慢演变,我想最开始的淘宝登录肯定没这么复杂。但是从03年淘宝网成立至今2020年,随着阿里巴巴的慢慢壮大,子公司也越来越多,很多东西要划分开来,但是这些子公司之间又有关联性,比如用户登录了淘宝之后,也许要登录天猫(淘宝和天猫的顶级域名不同,所以不能共享cookies),但同样都是属于阿里巴巴集团的公司,这样重复的登录对用户而言会有点麻烦,降低了用户使用体验。为了解决这个问题,单点登录就出现了。
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。 ——百度百科
此图来于网络资料收集
知道了流程和请求链接及参数之后,便就可以用代码来模拟请求了。
代码实现
1.判断输入账号后是否需要验证码
def _user_check(self):
data = {
'username': self.username,
'ua': self.ua
}
try:
response = self.session.post(self.user_check_url, data=data, timeout=self.timeout)
response.raise_for_status()
except:
print("账号需要验证码")
2.验证用户名密码,若验证成功并返回st码申请地址
def _verify_password(self):
verify_password_headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Origin': 'https://login.taobao.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://login.taobao.com/member/login.jhtml?from=taobaoindex&f=top&style=&sub=true&redirect_url=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm',
}
# 登录toabao.com 从浏览器复制form data的提交数据
verify_password_data = {
'TPL_username': self.username,
'ncoToken': '507aa5182c96f27aaad2e6571a3425846ae5745f',
'slideCodeShow': 'false',
'useMobile': 'false',
'lang': 'zh_CN',
'loginsite': 0,
'newlogin': 0,
'TPL_redirect_url': 'https://www.taobao.com/',
'from': 'tb',
'fc': 'default',
'style': 'default',
'keyLogin': 'false',
'qrLogin': 'true',
'newMini': 'false',
'newMini2': 'false',
'loginType': '3',
'gvfdcname': '10',
'gvfdcre': '68747470733A2F2F6C6F67696E2E74616F62616F2E636F6D2F6D656D6265722F6C6F676F75742E6A68746D6C3F73706D3D613231626F2E323031372E3735343839343433372E372E3561663931316439456B5773397A26663D746F70266F75743D7472756526726564697265637455524C3D68747470732533412532462532467777772E74616F62616F2E636F6D253246',
'TPL_password_2': self.TPL_password2,
'loginASR': '1',
'loginASRSuc': '1',
'oslanguage': 'zh-CN',
'sr': '1536*864',
'osVer': '',
'naviVer': 'chrome|75.03770142',
'osACN': 'Mozilla',
'osAV': '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'osPF': 'Win32',
'appkey': '00000000',
'mobileLoginLink': 'https://login.taobao.com/member/login.jhtml?redirectURL=https://www.taobao.com/&useMobile=true',
'showAssistantLink': '',
'um_token': 'TF0ABBC1D4E5BBF32528851CD189E64A00635DB82C599E278C3A8475900',
'ua': self.ua
}
try:
response = self.session.post(self.verify_password_url, headers=verify_password_headers, data=verify_password_data,
timeout=self.timeout)
response.raise_for_status()
# 从返回的页面中提取申请st码地址
except Exception as e:
print('验证用户名和密码请求失败,原因:')
raise e
# 提取申请st码url
apply_st_url_match = re.search(r'<script src="(.*?)"></script>', response.text)
# 存在则返回
if apply_st_url_match:
print('验证用户名密码成功,st码申请地址:{}'.format(apply_st_url_match.group(1)))
return apply_st_url_match.group(1)
else:
raise RuntimeError('用户名密码验证失败!response:{}'.format(response.text))
其中"verify_password_data"的数据来源为:
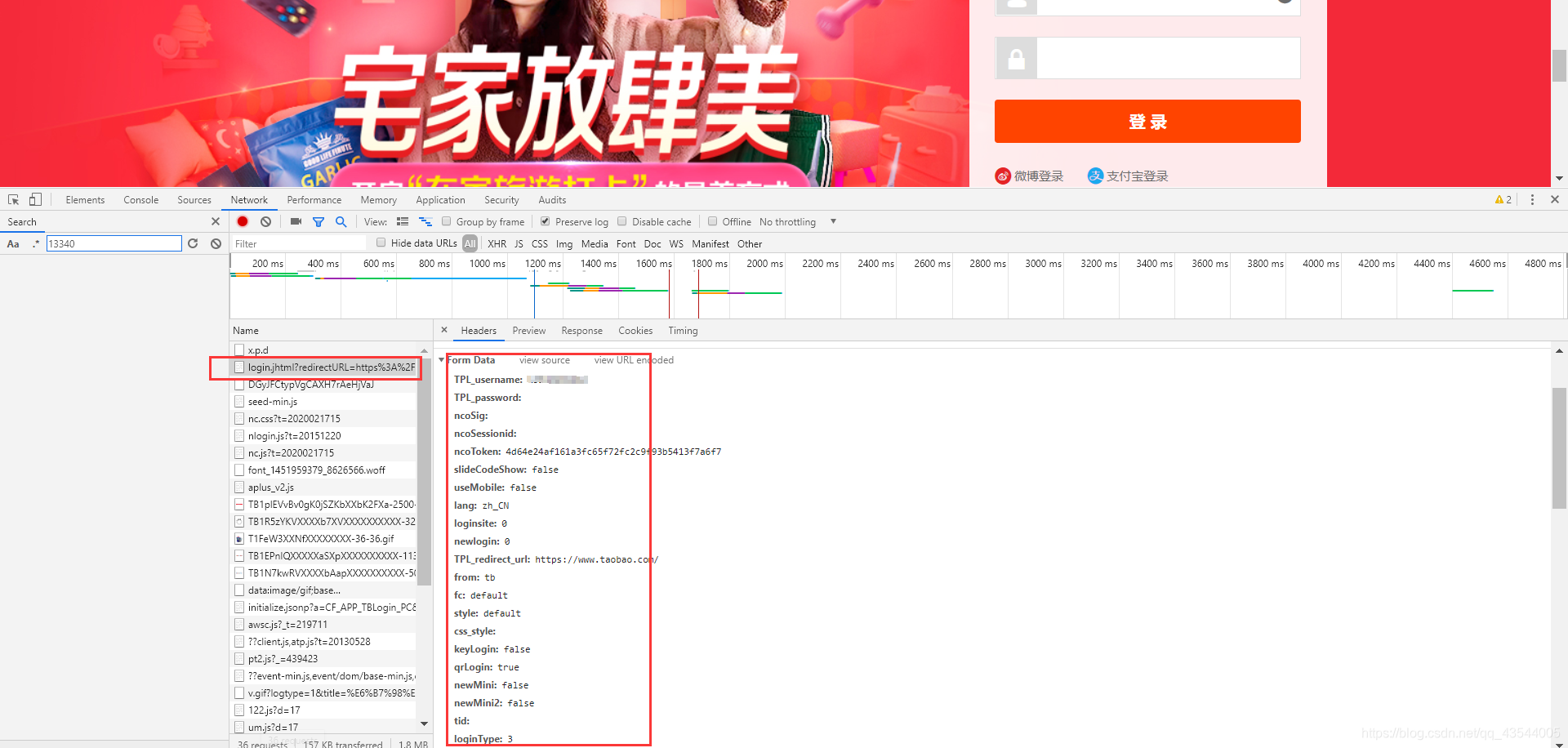
3.申请st码 若成功返回st码
def _apply_st(self):
apply_st_url = self._verify_password()
try:
response = self.session.get(apply_st_url)
response.raise_for_status()
except:
print('申请st码请求失败,原因:')
st_match = re.search(r'"data":{"st":"(.*?)"}', response.text)
if st_match:
print('获取st码成功,st码:{}'.format(st_match.group(1)))
return st_match.group(1)
else:
print('获取st码失败!response:{}'.format(response.text))
4.使用st码登录
def login(self):
"""
使用st码登录
:return:
"""
# 加载cookies文件
if self._load_cookies():
return True
# 判断是否需要滑块验证
self._user_check()
st = self._apply_st()
headers = {
'Host': 'login.taobao.com',
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
try:
response = self.session.get(self.vst_url.format(st), headers=headers)
response.raise_for_status()
except Exception as e:
print('st码登录请求,原因:')
raise e
# 登录成功,提取跳转淘宝用户主页url
my_taobao_match = re.search(r'top.location.href = "(.*?)"', response.text)
if my_taobao_match:
print('登录淘宝成功,跳转链接:{}'.format(my_taobao_match.group(1)))
self._serialization_cookies()
return True
else:
raise RuntimeError('登录失败response:{}'.format(response.text))
5.获取淘宝昵称
def get_taobao_nick_name(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
try:
response = self.session.get(self.my_taobao_url, headers=headers)
response.raise_for_status()
except Exception as e:
print('获取淘宝主页请求失败!原因:')
raise e
# 提取淘宝昵称
nick_name_match = re.search(r'<input id="mtb-nickname" type="hidden" value="(.*?)"/>', response.text)
if nick_name_match:
print('登录淘宝成功,你的用户名是:{}'.format(nick_name_match.group(1)))
return nick_name_match.group(1)
else:
print('获取淘宝昵称失败!response:{}'.format(response.text))
6.将cookies序列化。
每次程序运行完后,登录的cookies就没了,也就是说下次又要重新登录太过于重复,而浏览器却可以保存cookies信息,将cookies序列化可以解决眼前的问题。
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。——百度百科
简单说序列化就是将对象持久性保存起来,因为原来对象是在内存中,程序运行完了就要释放内存,所有的对象、变量等都会被清除,而序列化则可以把他们保存到文件。即使程序关闭了,下次启动的时候可以读取文件到内存转回对象继续使用,而这个过程叫反序列化。
也就是说,我们第一次登录成功后,将cookies保存在本地文件。第二次或后面需要的时候读取它,就不需要重新登录了。如果cookies过期,就将本地保存的cookies删除,再重新登录写入新的cookies,留在以后登录。
def _load_cookies(self):
# 1、判断cookies序列化文件是否存在
if not os.path.exists(COOKIES_FILE_PATH):
print('cookies文件不存在')
return False
# 2、加载cookies
self.session.cookies = self._deserialization_cookies()
# 3、判断cookies是否过期
try:
self.get_taobao_nick_name()
except Exception as e:
os.remove(COOKIES_FILE_PATH)
print('cookies过期,删除cookies文件!')
return False
print('加载淘宝登录cookies成功!!!')
return True

二、爬取淘宝商品信息
我们在网页中打开淘宝网,然后登录,打开chrome的调试窗口,点击network,然后勾选上Preserve log,在搜索框中输入你想要搜索的商品名称。
如果不勾上Preserve log会没有资源包信息。
-
首先分析网页
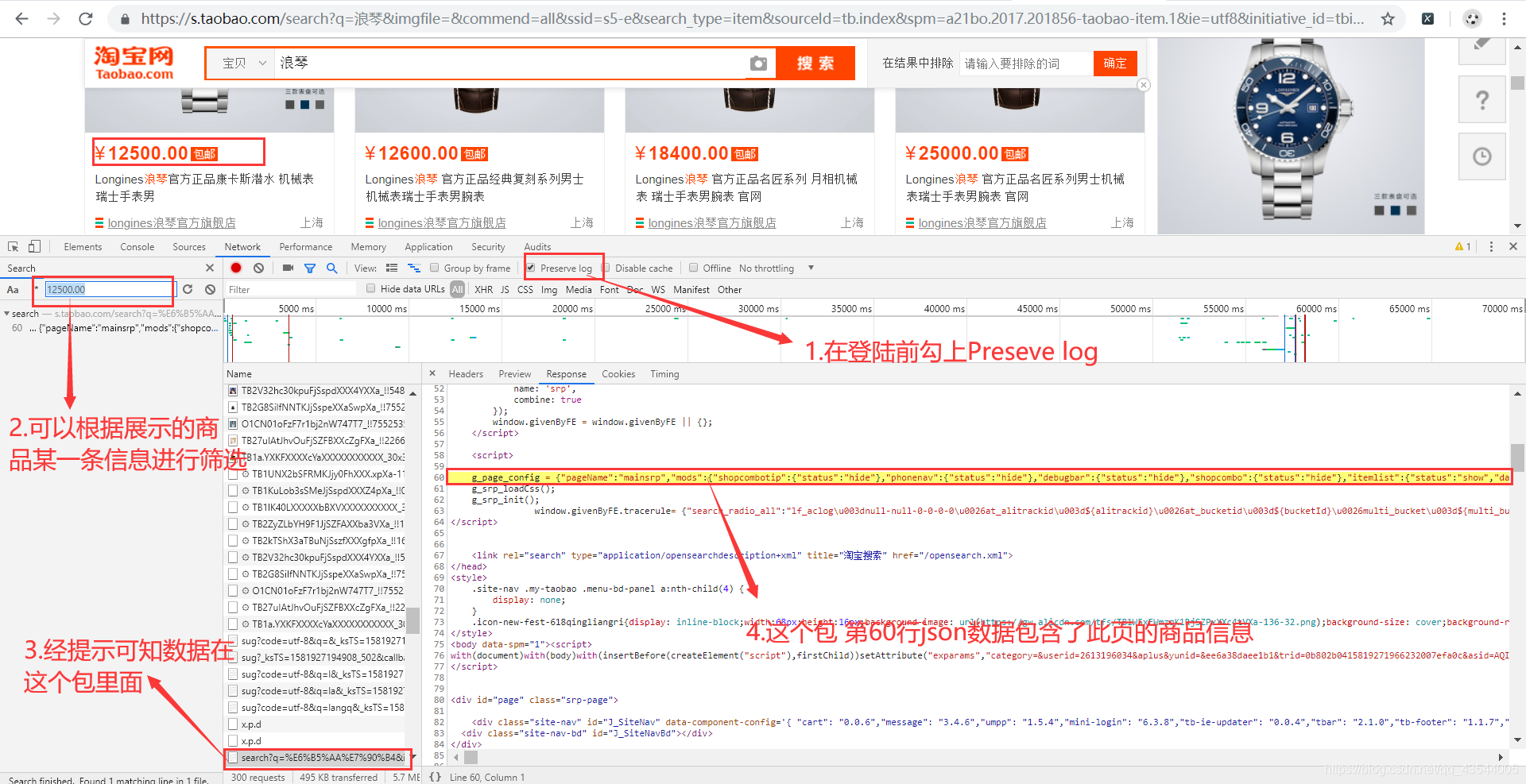
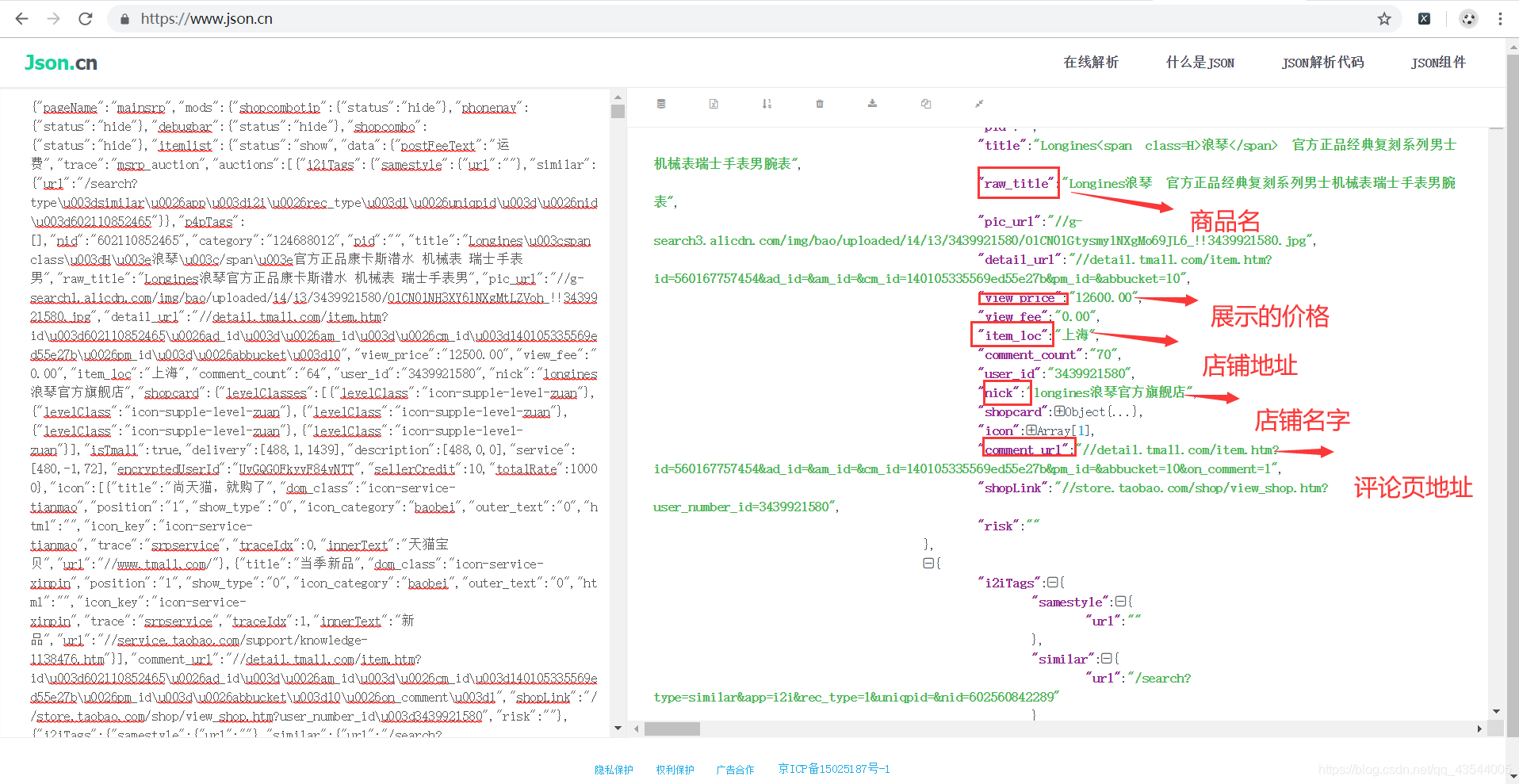
将这一行的数据复制下来,经过简单的修改,在json.cn我们可以清楚的看见,数据的层级关系,利于json解析,提取数据。
-
解析Json数据,并提取标题、价格、商家地址、销量、评价地址
def _get_goods_info(self, goods_str):
goods_json = json.loads(goods_str)
goods_items = goods_json['mods']['itemlist']['data']['auctions']
goods_list = []
for goods_item in goods_items:
goods = {'title': goods_item['raw_title'],
'price': goods_item['view_price'],
'location': goods_item['item_loc'],
'nick': goods_item['nick'],
'comment_url': goods_item['comment_url']}
goods_list.append(goods)
return goods_list
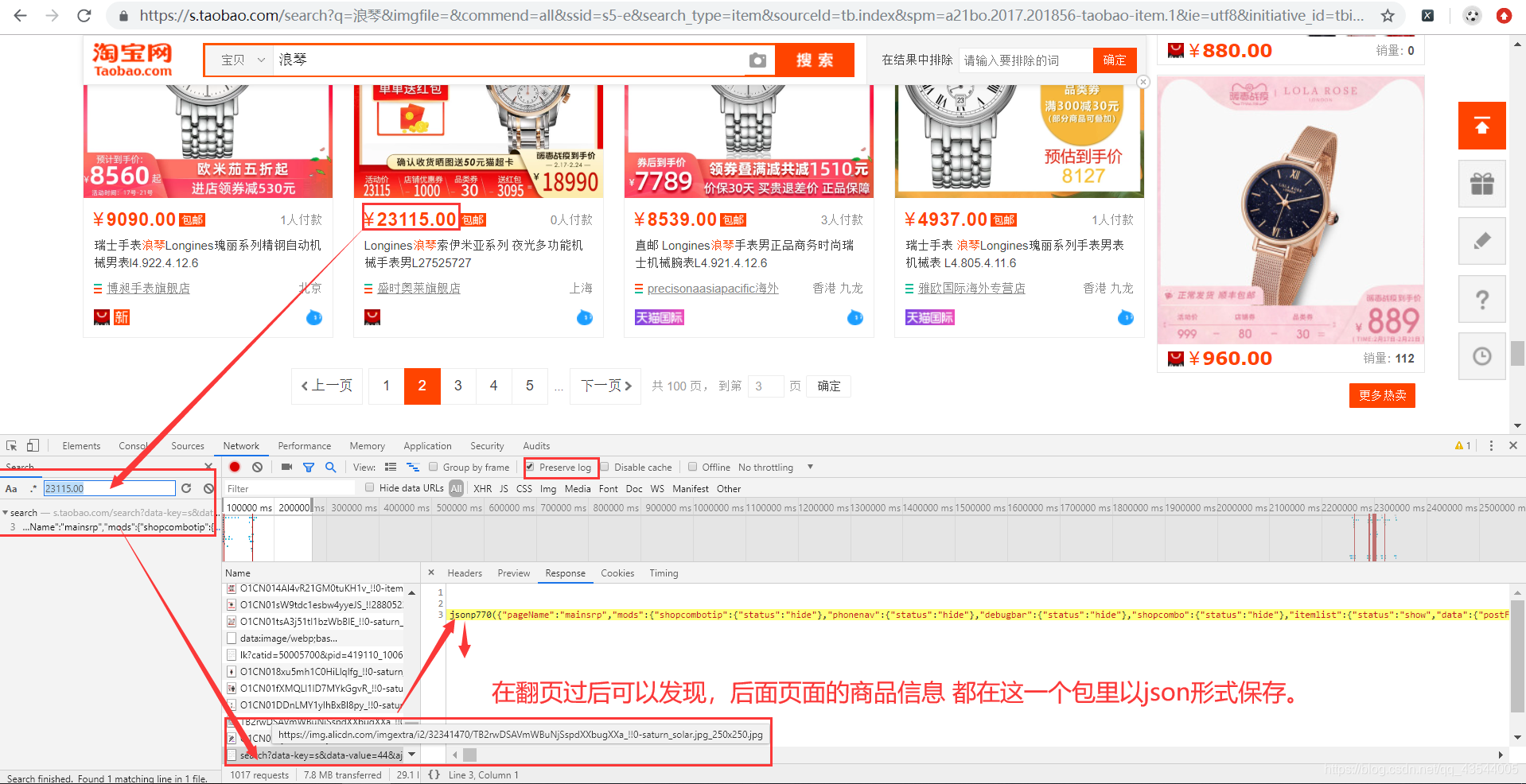
拿到第一页 第二页 第三页的 存有商品信息包 的 URL

可以发现 第一页无ajax=true,第二三页有,同时里面部分数据发生变化,但有规律
- 经过简单推理可以的构造后面的的url
def spider_goods(self, page):
s = page * 44
# 搜索链接,q参数表示搜索关键字,s=page*44 数据开始索引
search_url = f'https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q={self.q}&suggest=history_1&_input_charset=utf-8&wq=biyunt&suggest_query=biyunt&source=suggest&bcoffset=4&p4ppushleft=%2C48&s={s}&data-key=s&data-value={s + 44}'
# 代理ip
proxies = {'http': '123.207.218.215:1080'}
# 请求头
headers = {
'referer': 'https://www.taobao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = req_session.get(search_url, headers=headers, proxies=proxies,
verify=False, timeout=self.timeout)
# print(response.text)
goods_match = re.search(r'g_page_config = (.*?)}};', response.text)
# # 没有匹配到数据
if not goods_match:
print('提取页面中的数据失败!')
print(response.text)
# raise RuntimeError
goods_str = goods_match.group(1) + '}}'
goods_list = self._get_goods_info(goods_str)
self._save_excel(goods_list)
print(goods_str)
- json数据生成excel文件
def _save_excel(self, goods_list):
"""
将json数据生成excel文件
:param goods_list: 商品数据
:param startrow: 数据写入开始行
:return:
"""
# pandas没有对excel没有追加模式,只能先读后写
if os.path.exists(GOODS_EXCEL_PATH):
df = pd.read_excel(GOODS_EXCEL_PATH)
df = df.append(goods_list)
else:
df = pd.DataFrame(goods_list)
writer = pd.ExcelWriter(GOODS_EXCEL_PATH)
# columns参数用于指定生成的excel中列的顺序
df.to_excel(excel_writer=writer, columns=['title', 'price', 'location', 'nick', 'comment_url'], index=False,
encoding='utf-8', sheet_name='Sheet')
writer.save()
writer.close()
贴上一张结果图

三、抓取评论
- 随便进入一个商品详细信息界面

- 找到存有评价信息的包
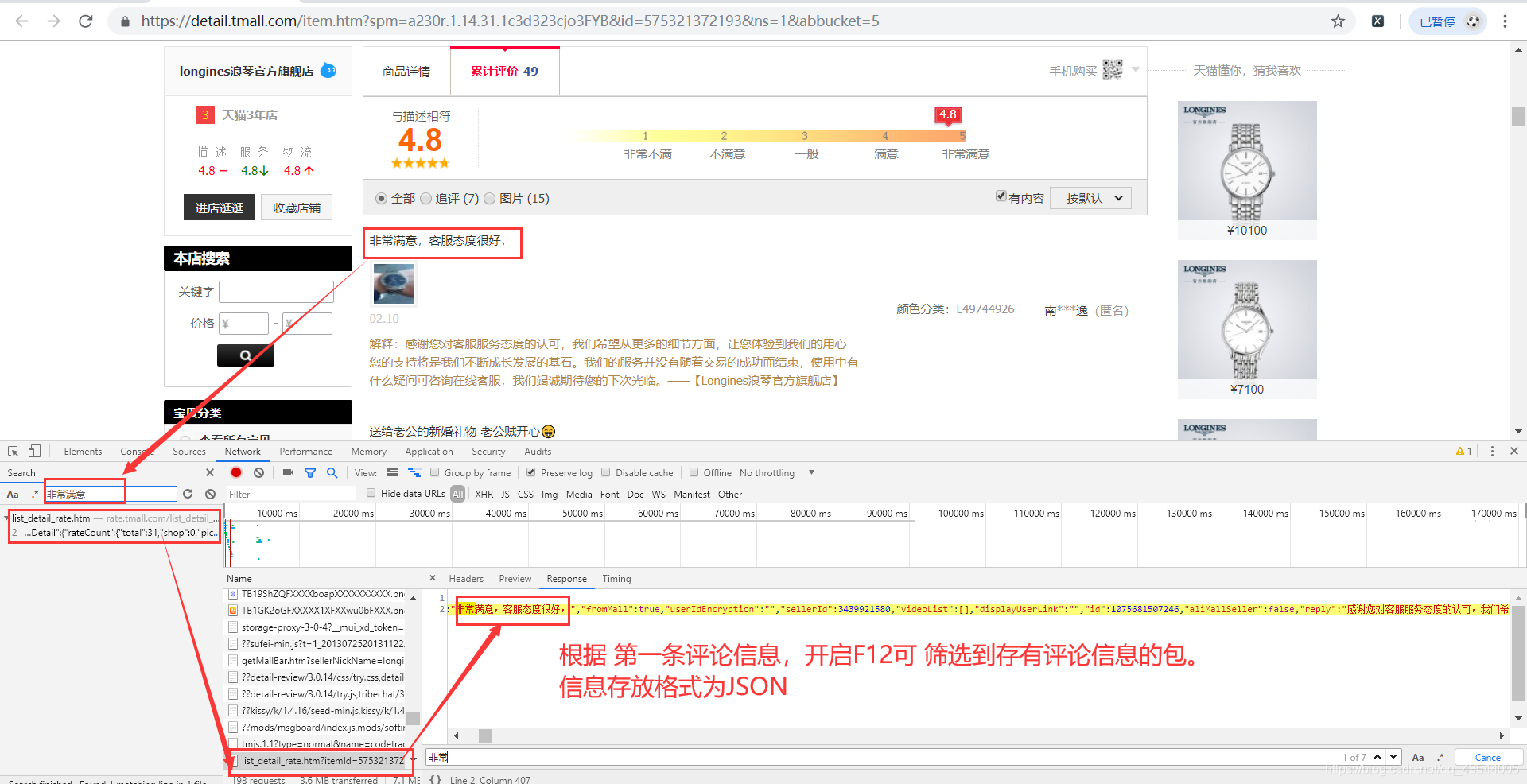
- 模拟请求
经观察请求网址为红色标记部分

请求网址"?"后面的内容params:

就是红框里面的内容。
经分析:要想获取评价信息,必须要带的params信息是
"itemId" #商品id
"sellerId"
"currentPage" #页码
"callback"
完整代码如下:
# # coding=gbk
##浪琴
import requests
import json,random
from Taobao_Log import TaoBaoLogin
requests.packages.urllib3.disable_warnings()
req_session = requests.Session()
tbl = TaoBaoLogin(req_session)
tbl.login()
proxies = [
{'https': 'https://'+'151.253.165.70:8080'}
# {'http':'http://'+'47.112.200.175:8000'}
]
proxies = random.choice(proxies)
url = "https://rate.tmall.com/list_detail_rate.htm"
header={
"cookie":"cna=EYnEFeatJWUCAbfhIw4Sd0GO; x=__ll%3D-1%26_ato%3D0; hng=CN%7Czh-CN%7CCNY%7C156; uc1=cookie14=UoTaHYecARKhrA%3D%3D; uc3=vt3=F8dBy32hRyZzP%2FF7mzQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&nk2=1DsN4FjjwTp04g%3D%3D&id2=UondHPobpDVKHQ%3D%3D; t=ad1fbf51ece233cf3cf73d97af1b6a71; tracknick=%5Cu4F0F%5Cu6625%5Cu7EA22013; lid=%E4%BC%8F%E6%98%A5%E7%BA%A22013; uc4=nk4=0%401up5I07xsWKbOPxFt%2BwuLaZ8XIpO&id4=0%40UOE3EhLY%2FlTwLmADBuTfmfBbGpHG; lgc=%5Cu4F0F%5Cu6625%5Cu7EA22013; enc=ieSqdE6T%2Fa5hYS%2FmKINH0mnUFINK5Fm1ZKC0431E%2BTA9eVjdMzX9GriCY%2FI2HzyyntvFQt66JXyZslcaz0kXgg%3D%3D; _tb_token_=536fb5e55481b; cookie2=157aab0a58189205dd5030a17d89ad52; _m_h5_tk=150df19a222f0e9b600697737515f233_1565931936244; _m_h5_tk_enc=909fba72db21ef8ca51c389f65d5446c; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; l=cBa4gFrRqYHNUtVvBOfiquI8a17O4IJ51sPzw4_G2ICP9B5DeMDOWZezto8kCnGVL6mpR3RhSKO4BYTKIPaTlZXRFJXn9MpO.; isg=BI6ORhr9X6-NrOuY33d_XmZFy2SQp1Ju1qe4XLjXJRHsGyp1IJ9IG0kdUwfSA0oh",
"referer":"https://detail.tmall.com/item.htm",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
}
params={ #必带信息
"itemId":"602110852465", #商品id
"sellerId":"3439921580",
"currentPage":"2", #页码
"callback":"jsonp548",
}
req=req_session.get(url=url,params=params,headers=header,proxies=proxies).content.decode('utf-8')[12:-1] #解码,并且去除str中影响json转换的字符(\n\rjsonp(...));
req="{"+req
print(req)
result=json.loads(req)
print(result)
for i in range(20):
comment=result['rateDetail']['rateList'][i]['rateContent']
print(comment)
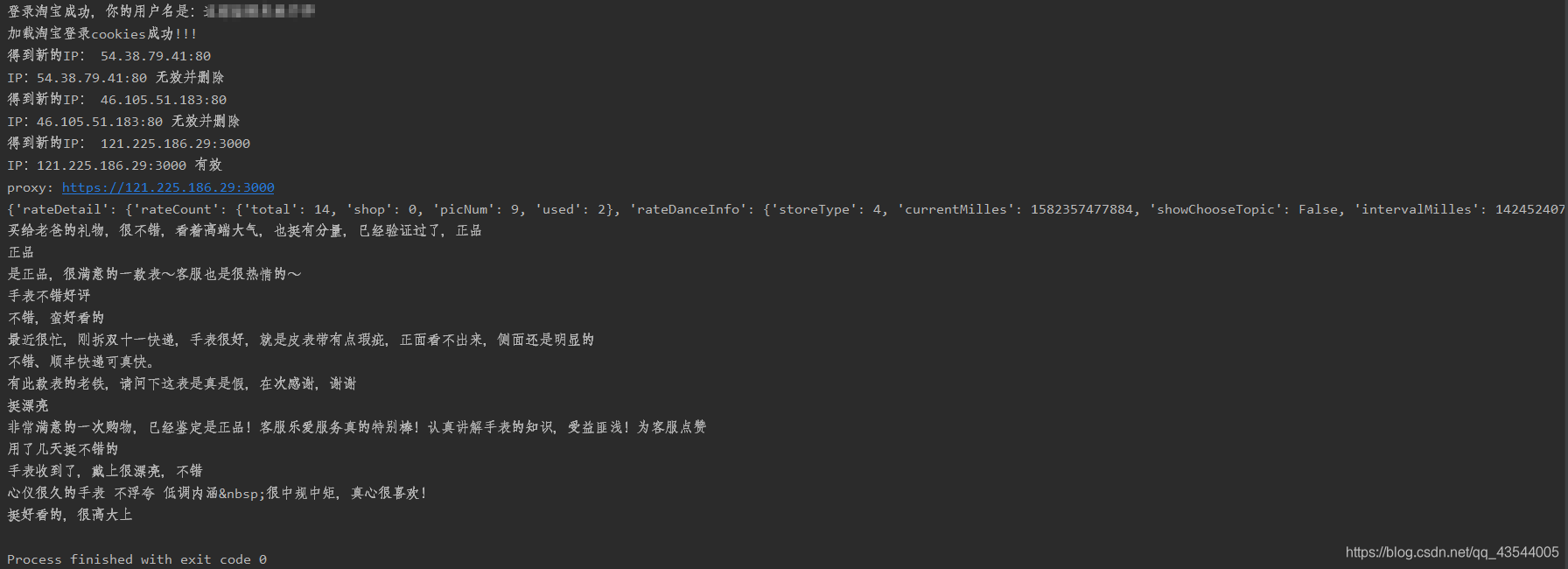
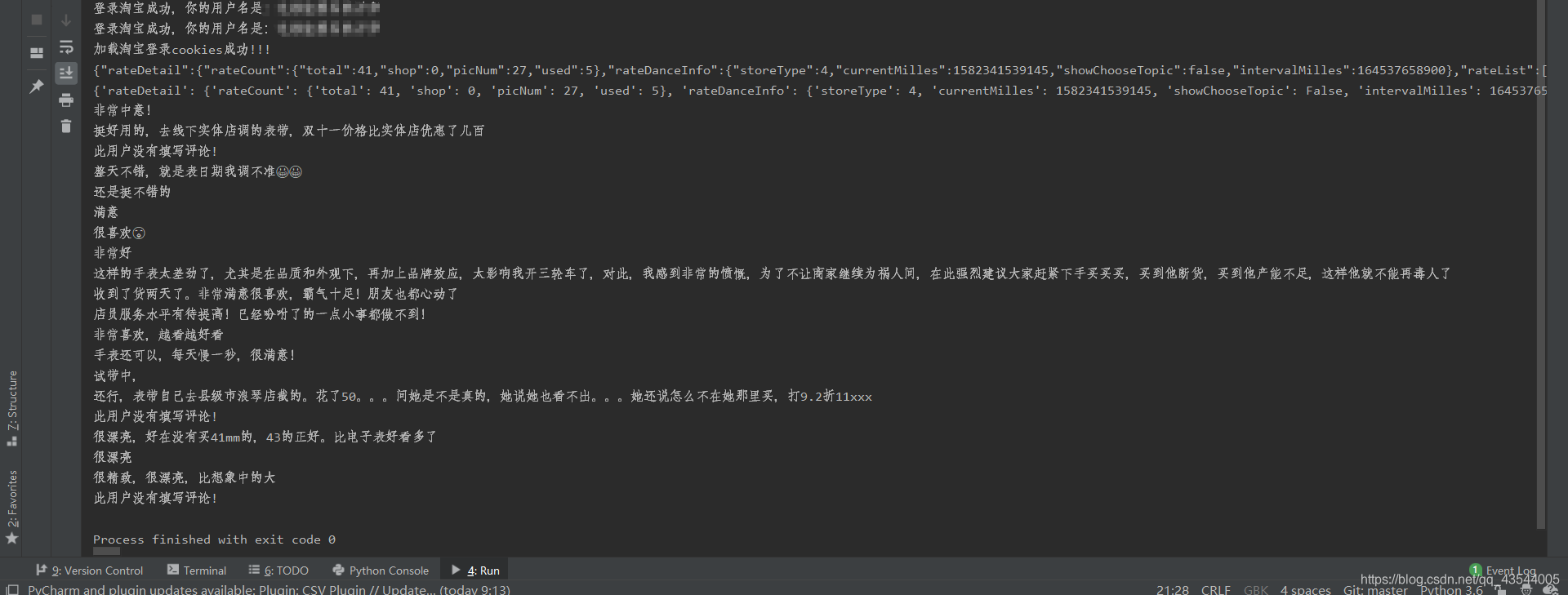
结果图:
四、加强版
对于这次爬虫,我们已经可以拿到自己想要的商品列表页和评论。但对于一个列表页的所有商品的评论该如何爬取呢?
在写代码调试的过程中,我们可以发现,同样的代码,在重复1~2次爬取时,就会产生错误,
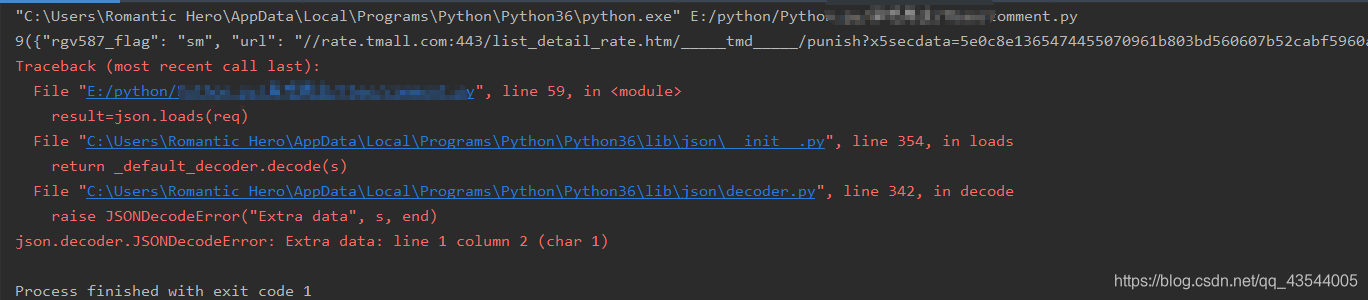
根据报错结果我们可以发现,是result=json.loads(req)错误。
究其原因是因为淘宝的反爬十分严格,当检测到同一淘宝账号,IP地址 发送请求频率过高,很容易被淘宝反爬机制检测,要求重新登录或者得不到对应网页的响应,得到错误的返回结果。于是json解析就出现了错误。
解决思路“
-
采用IP代理池,获取多个可用的IP并不断更换。
-
创建多个账号,获取多个cookies并不断更换。
关于IP代理池 -
找到 IP代理池框架
我们可以在github这个开发者社区找到需要的开源项目,star数目超过9000,是个很好的项目。
-
长话短说,根据项目README.md,配置好必要的库与设置,下载数据库reids和可视化软件Redis Desktop Manger
开启reids数据库
打开可视化软件

-
尝试抓取IP
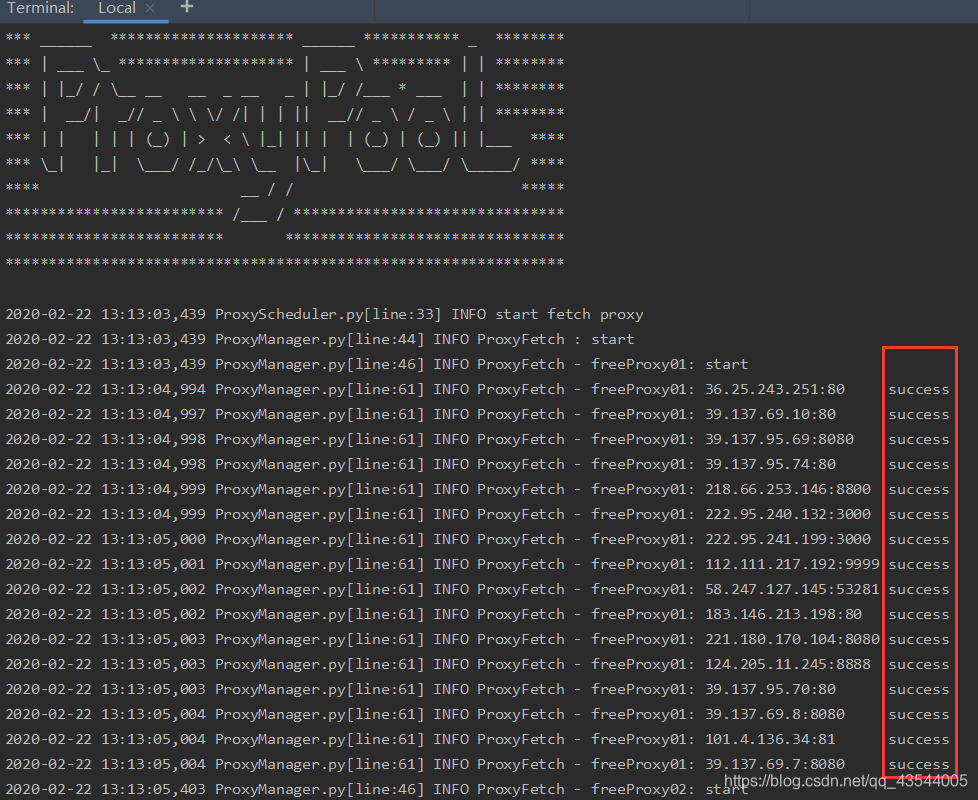
其中 带有success结尾的IP,表示为可用。
在数据库可视化软件中也可查看
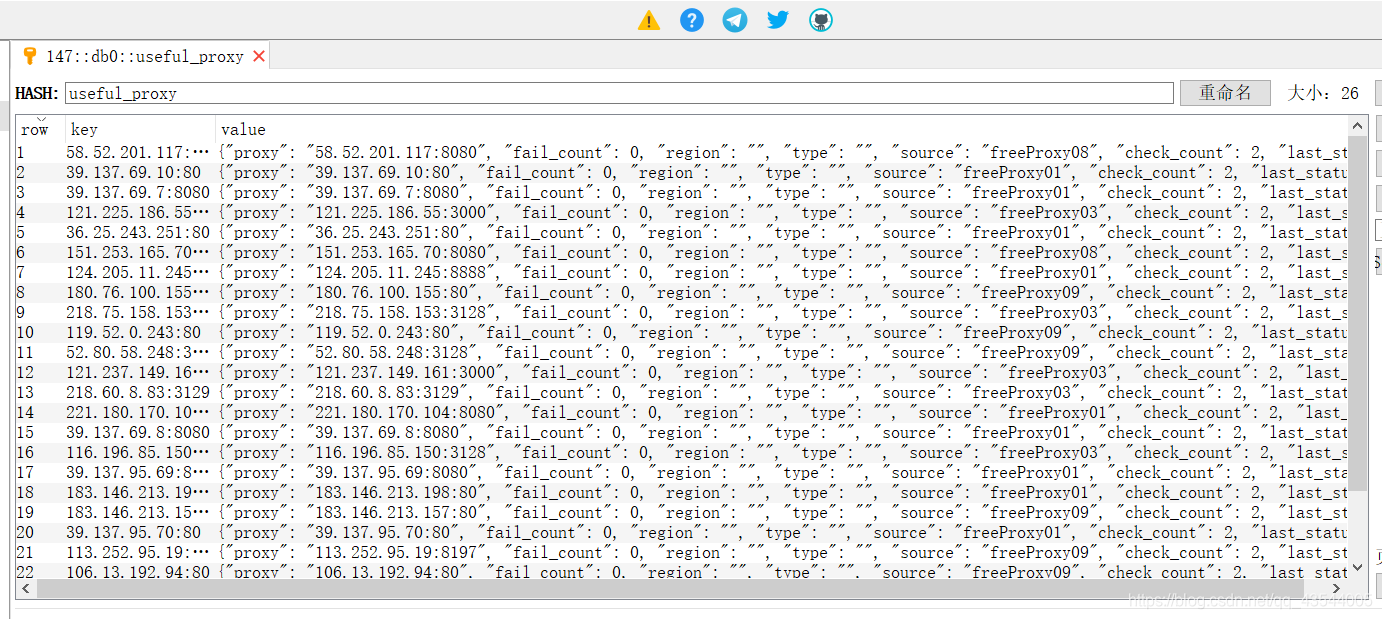
此外我们也可以通过 API查看抓取的代理:
API地址:http://127.0.0.1:5010API介绍:

随机获得一个可用的IP:

得到可用的IP数量:


如果要在爬虫代码中使用的话, 可以将此API封装成函数直接使用:
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('https://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 出错5次, 删除代理池中代理
delete_proxy(proxy)
return None
我们可以在url = 'http://httpbin.org/ip' 测试代理池的IP是否真的可用
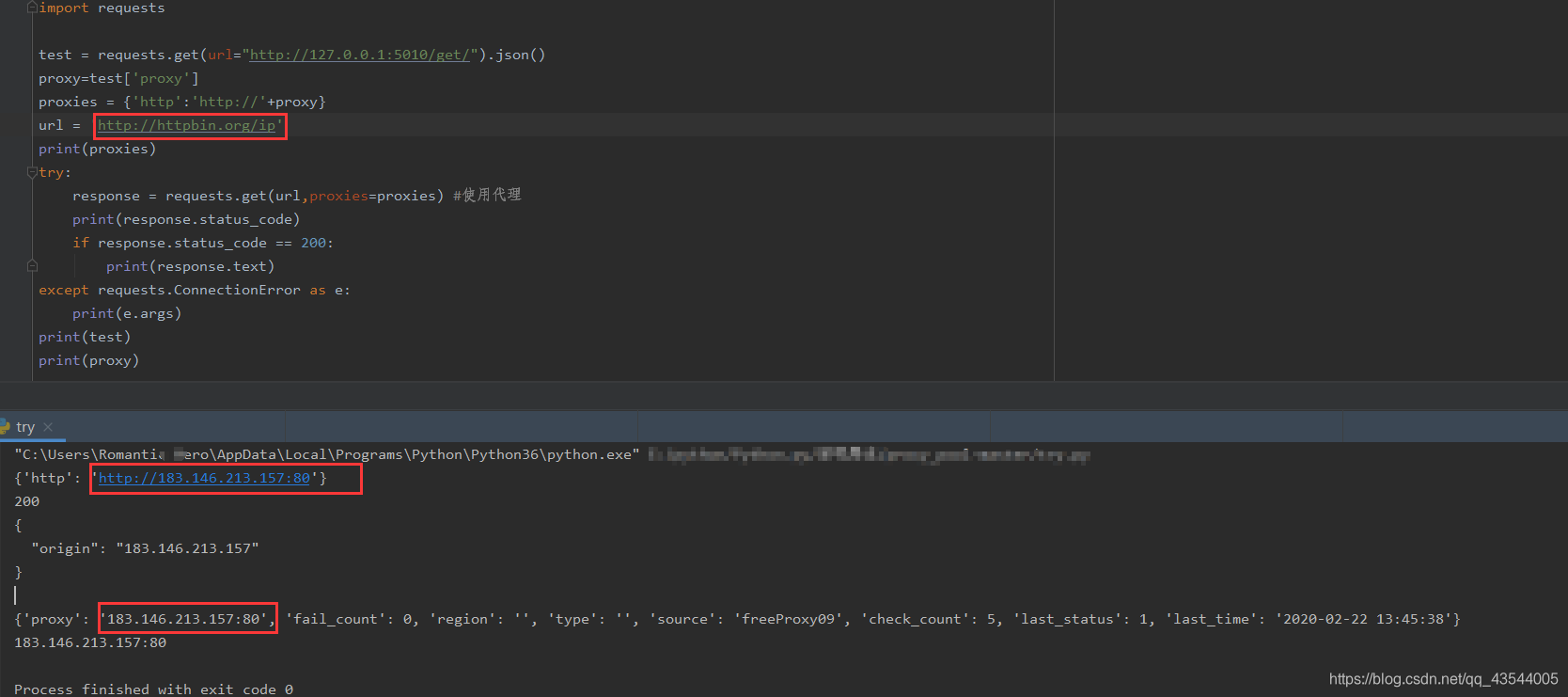
测试成功。
小结,关于IP代理池 得到可用IP 我们初步解决了。
应用IP代理池应对反爬
在运行代码的过程中 发现了一个问题:

解决方法 :
- 关掉科学上网软件软件

- 给程序添加如下代码
http的连接数超过最大限制,默认的情况下连接是Keep-alive的,所以这就导致了服务器保持了太多连接而不能再新建连接。或者是可能安装shadowsock后不小心设置了全局代理的原因。也或者是采集API的时候使用requests.get太多
import os
os.environ['NO_PROXY'] = 'stackoverflow.com'
单个商品的评论取得效果