(一)确定需要爬取的信息
在爬取前首先确定需要获取的信息,打开taobao,在搜索框中输入,需要获取的商品的信息,比如ipad,点击搜索

就可以看到许多的ipad,选择其中的一款商品,比如第一个
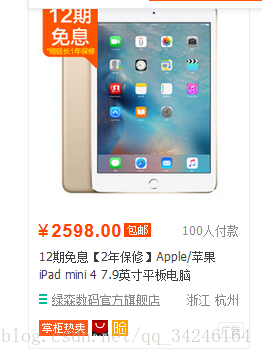
可以看到,其包含了以下的信息:
(1)price: 售价
(2)deal-cnt: 付款人数
(3)name: 产品名称
(4)shop_name: 店铺名称
扫描二维码关注公众号,回复:
1846826 查看本文章

(5)location: 店铺所在地
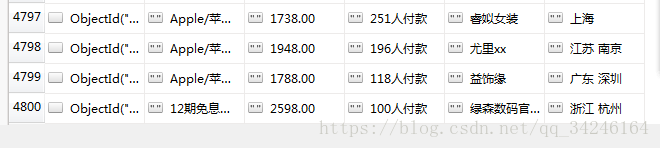
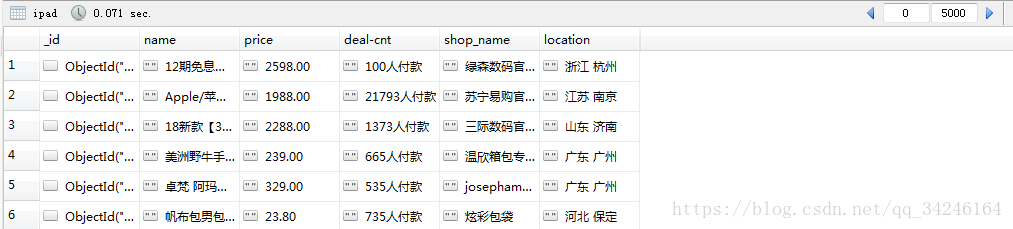
因此,我们可以爬取上面的这些信息,最后将结果存储在 数据库 mongo 中,最终的存储效果为:
接下来开始介绍整个的爬取流程
(二)爬取流程
1.网页特点分析
在商品页面右键查看源代码,会发现找不到需要的信息,便可以猜测其是通过ajax或者其他的方式来加载的。因此,采用selenium 和 pyquery 来爬取商品信息。
2.代码分析
2.1 导入相关的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pyquery import PyQuery as pq
import pymongo
from urllib.parse import quote2.2 进行必要的初始化
browser = webdriver.Firefox() #初始化浏览器
wait = WebDriverWait(browser, 30) #指定延时时间
client = pymongo.MongoClient(host= 'localhost', port=27017)
db = client['taobao'] #指定使用的数据库
collection = db['ipad'] #指定使用的集合
2.3获取网页
首先分析网页的特点,右键 — 查看元素,首先找到页面下方的切换网页的地方

其对应的源代码如下:

def page_get(page):
print('正在爬取第',page,'页')
try:
url = "https://s.taobao.com/search?q=" + quote('ipad')
browser.get(url) #连接淘宝网
in_put = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager .form>input'))) #输入框
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager .form>.btn'))) #提交按钮
in_put.clear() #清空输入信息, 每次都要
in_put.send_keys(page) #输入信息
submit.click() #点击提交按钮
print('连接成功')
item_info() #调用信息提取页面
except TimeoutException:
page_get(page)2.4获取商品信息
首先分析网页,发现商品的信息都存储在 id ="mainsrp-itemlist"
<div id="mainsrp-itemlist"><div class="m-itemlist" data-spm="14">
其下面的 class = "items" 的每一个子节点 class = "item" 均代表一个商品,点开每个标签,即可看到详细信息
获取商品信息的代码如下:
def item_info():
html = browser.page_source #获取html
doc = pq(html)
print("获取成功")
items = doc('#mainsrp-itemlist .item').items() #形成可迭代列表
print('这一页商品的的个数是',len(doc('#mainsrp-itemlist .item')),'件')
#遍历获取商品的信息
for item in items:
items_info = {
'name': item.find('.row-2').text(),
'price': item.find('.price>strong').text(),
'deal-cnt' : item.find('.deal-cnt').text(),
'shop_name': item.find('.row-3 a').text(),
'location' : item.find('.row-3 .location').text(),
} #一件商品的信息提取完毕
result_save(items_info) #存储2.5 存储
将最终的结果存储到 非关系型数据库 Mongo 中
def result_save(data):
if collection.insert(data):
print('保存成功')
else:
print("保存失败")2.6主函数
def main():
print("working")
for page in range(1,101):
page_get(page)2.7运行整个程序
if __name__ == '__main__':
main()2.8最终结果
最终爬取了4800条数据