文章目录
-
前言
-
一、解析淘宝URL组成
-
二、查看网页源码并用re库提取信息
-
1.查看源码2.re库提取信息
-
三:函数填写
-
四:主函数填写
-
五:完整代码
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤

QQ群:701698587
前言
本文简单使用python的requests库及re正则表达式对淘宝的商品信息(商品名称,商品价格,生产地区,以及销售额)进行了爬取,并最后用xlsxwriter库将信息放入Excel表格。最后的效果图如下:
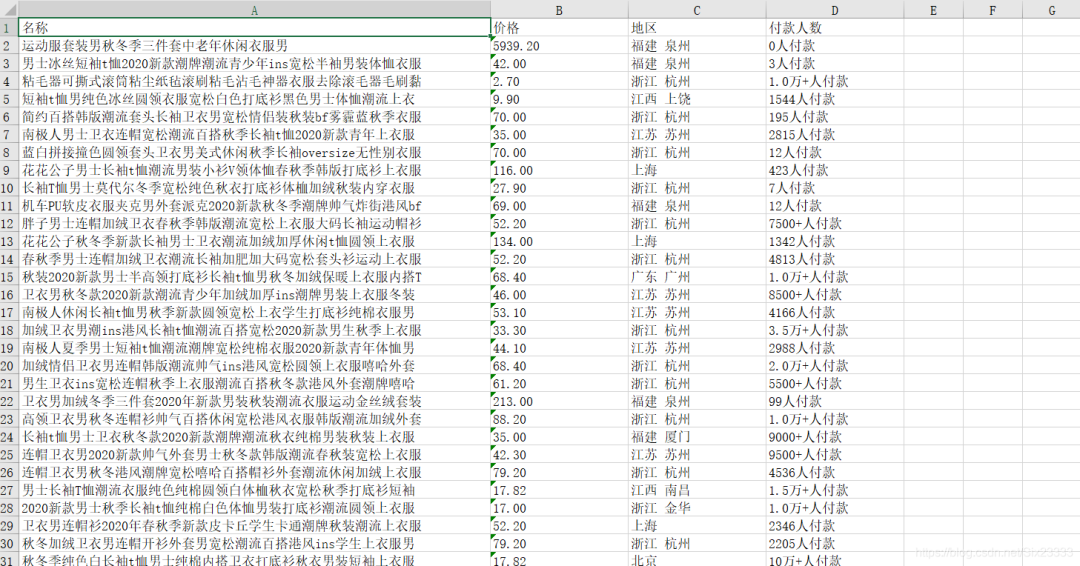
提示:以下是本篇文章正文内容
一、解析淘宝URL组成
1.我们的第一个需求就是要输入商品名字返回对应的信息
所以我们这里随便选一个商品来观察它的URL,这里我们选择的是书包,打开网页,可知他的URL为:
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306
可能单单从这个url里我们看不出什么,但是我们可以从图中看出一些端倪

我们发现q后面的参数就是我们要获取的物品的名字2.我们第二个需求就是根据输入的数字来爬取商品的页码
所以我们来观察一下后面几页URL的组成
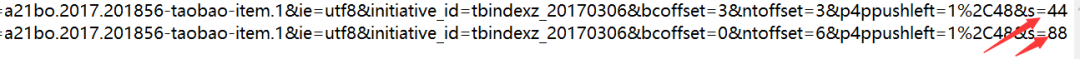
由此我们可以得出分页的依据是最后s的值=(44(页数-1))
二、查看网页源码并用re库提取信息
1.查看源码

这里的几个信息都是我们所需要的
2.re库提取信息
a = re.findall(r'"raw_title":"(.*?)"', html)
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)三:函数填写
这里我写了三个函数,第一个函数来获取html网页,代码如下:
def GetHtml(url):
r = requests.get(url,headers =headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r第二个用于获取网页的URL代码如下:
def Geturls(q, x):
url = "https://s.taobao.com/search?q=" + q + "&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm" \
"=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 "
urls = []
urls.append(url)
if x == 1:
return urls
for i in range(1, x ):
url = "https://s.taobao.com/search?q="+ q + "&commend=all&ssid=s5-e&search_type=item" \
"&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306" \
"&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" + str(
i * 44)
urls.append(url)
return urls第三个用于获取我们需要的商品信息并写入Excel表格代码如下:
def GetxxintoExcel(html):
global count#定义一个全局变量count用于后面excel表的填写
a = re.findall(r'"raw_title":"(.*?)"', html)#(.*?)匹配任意字符
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)
x = []
for i in range(len(a)):
try:
x.append((a[i],b[i],c[i],d[i]))#把获取的信息放入新的列表中
except IndexError:
break
i = 0
for i in range(len(x)):
worksheet.write(count + i + 1, 0, x[i][0])#worksheet.write方法用于写入数据,第一个数字是行位置,第二个数字是列,第三个是写入的数据信息。
worksheet.write(count + i + 1, 1, x[i][1])
worksheet.write(count + i + 1, 2, x[i][2])
worksheet.write(count + i + 1, 3, x[i][3])
count = count +len(x) #下次写入的行数是这次的长度+1
return print("已完成")
四:主函数填写
if __name__ == "__main__":
count = 0
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
,"cookie":""#cookie 是每个人独有的,因为反爬机制的缘故,爬取太快可能到后面要重新刷新一下自己的Cookie。
}
q = input("输入货物")
x = int(input("你想爬取几页"))
urls = Geturls(q,x)
workbook = xlsxwriter.Workbook(q+".xlsx")
worksheet = workbook.add_worksheet()
worksheet.set_column('A:A', 70)
worksheet.set_column('B:B', 20)
worksheet.set_column('C:C', 20)
worksheet.set_column('D:D', 20)
worksheet.write('A1', '名称')
worksheet.write('B1', '价格')
worksheet.write('C1', '地区')
worksheet.write('D1', '付款人数')
for url in urls:
html = GetHtml(url)
s = GetxxintoExcel(html.text)
time.sleep(5)
workbook.close()#在程序结束之前不要打开excel,excel表在当前目录下
五:完整代码
import re
import requests
import xlsxwriter
import time
def GetxxintoExcel(html):
global count
a = re.findall(r'"raw_title":"(.*?)"', html)
b = re.findall(r'"view_price":"(.*?)"', html)
c = re.findall(r'"item_loc":"(.*?)"', html)
d = re.findall(r'"view_sales":"(.*?)"', html)
x = []
for i in range(len(a)):
try:
x.append((a[i],b[i],c[i],d[i]))
except IndexError:
break
i = 0
for i in range(len(x)):
worksheet.write(count + i + 1, 0, x[i][0])
worksheet.write(count + i + 1, 1, x[i][1])
worksheet.write(count + i + 1, 2, x[i][2])
worksheet.write(count + i + 1, 3, x[i][3])
count = count +len(x)
return print("已完成")
def Geturls(q, x):
url = "https://s.taobao.com/search?q=" + q + "&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm" \
"=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 "
urls = []
urls.append(url)
if x == 1:
return urls
for i in range(1, x ):
url = "https://s.taobao.com/search?q="+ q + "&commend=all&ssid=s5-e&search_type=item" \
"&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306" \
"&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" + str(
i * 44)
urls.append(url)
return urls
def GetHtml(url):
r = requests.get(url,headers =headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
if __name__ == "__main__":
count = 0
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
,"cookie":""
}
q = input("输入货物")
x = int(input("你想爬取几页"))
urls = Geturls(q,x)
workbook = xlsxwriter.Workbook(q+".xlsx")
worksheet = workbook.add_worksheet()
worksheet.set_column('A:A', 70)
worksheet.set_column('B:B', 20)
worksheet.set_column('C:C', 20)
worksheet.set_column('D:D', 20)
worksheet.write('A1', '名称')
worksheet.write('B1', '价格')
worksheet.write('C1', '地区')
worksheet.write('D1', '付款人数')
xx = []
for url in urls:
html = GetHtml(url)
s = GetxxintoExcel(html.text)
time.sleep(5)
workbook.close()
最后觉得写的可以的
