前言
上一节用beautifulsoup库爬取了csdn的个人信息,这一节学习使用re库爬取淘宝商品信息。
re库
正则表达式常用符号:
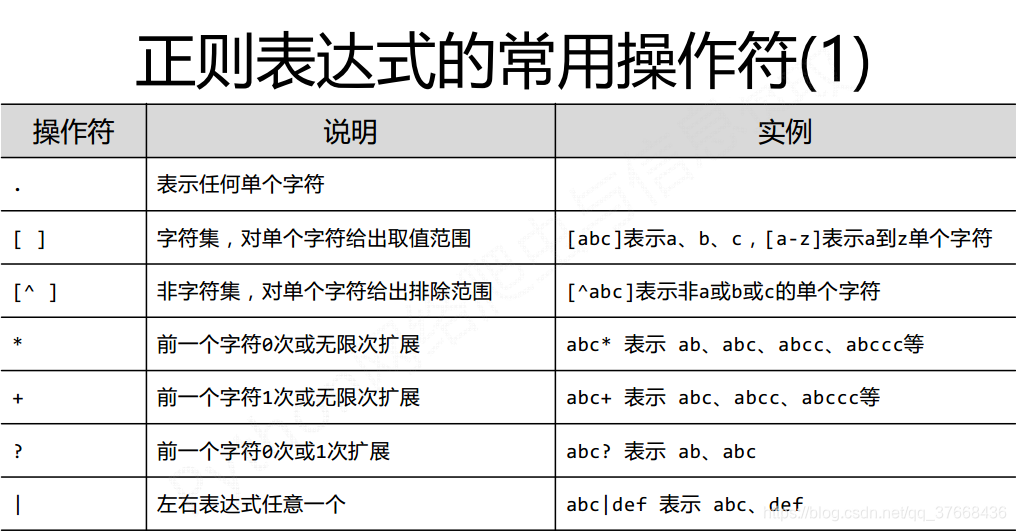
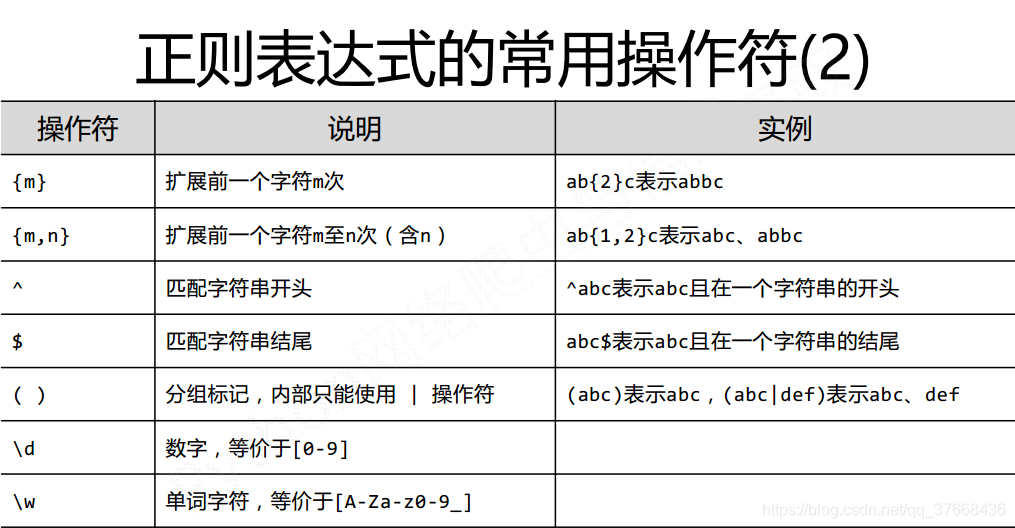
常用函数:

分析网页
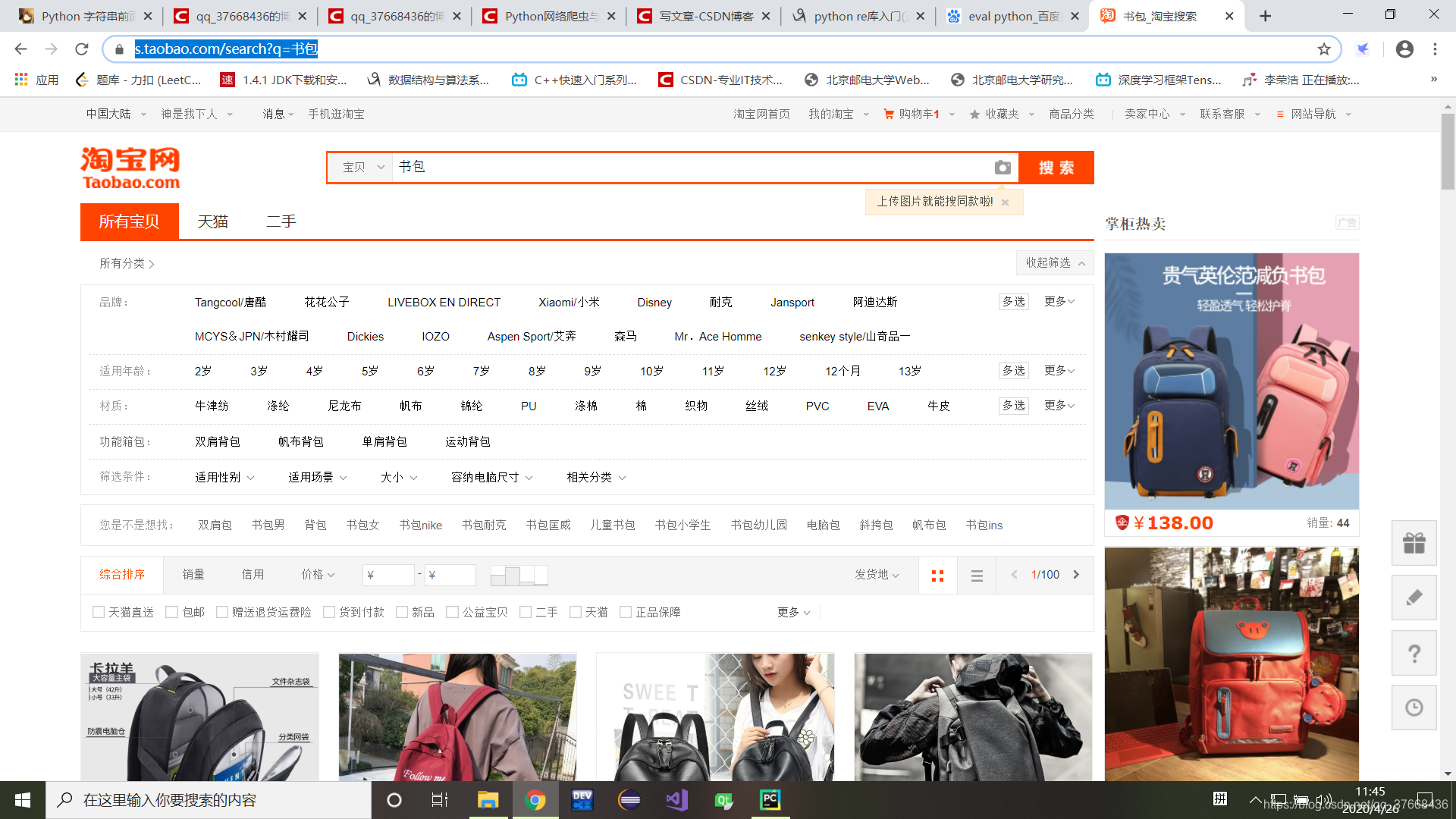
在淘宝搜索物品就是将url结尾加上q = ?的关键字,这里以书包为例查看网页源码:
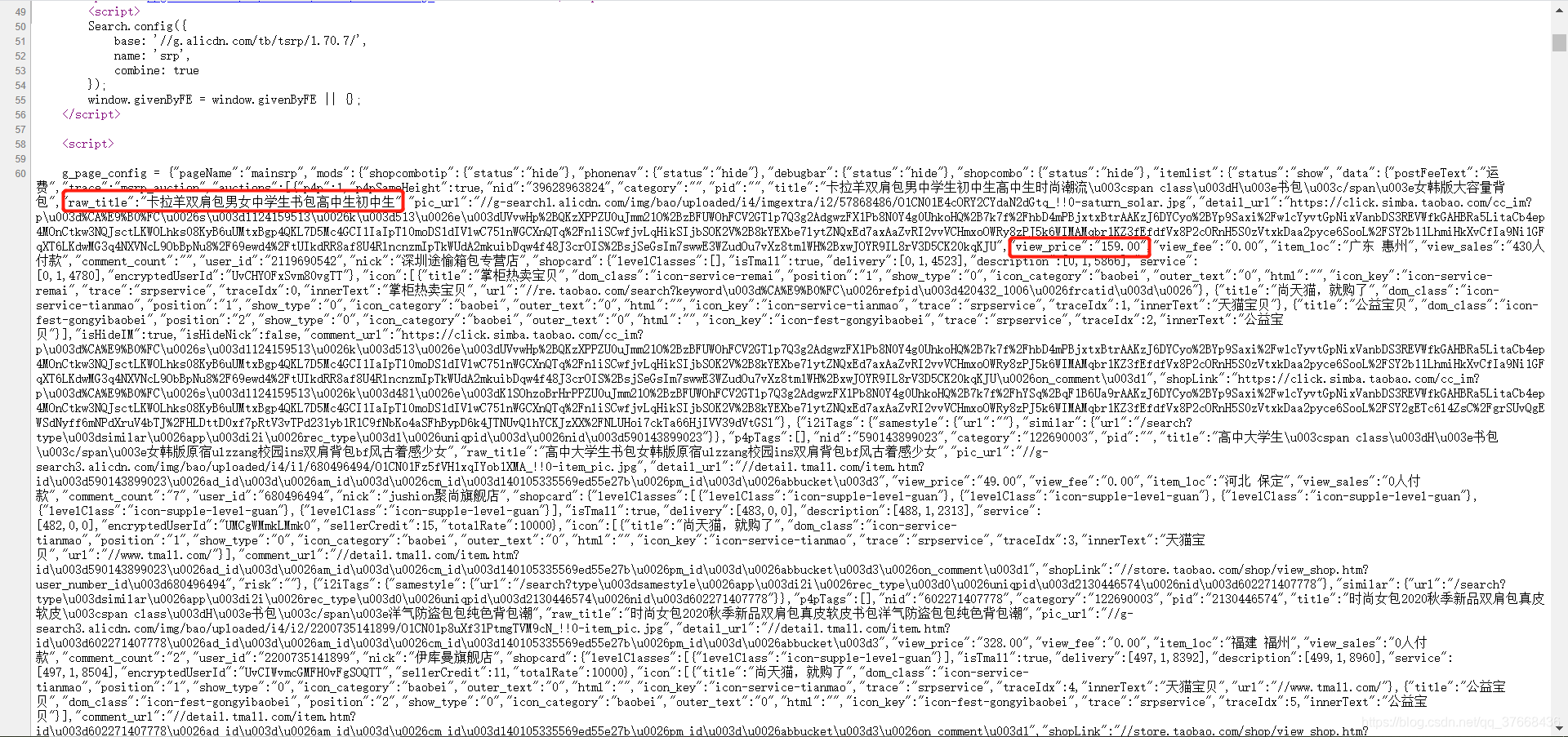
可以看到,标签名字在raw_title中,价格在view_price中,那么就用正则表达式匹配这个字符串即可。
代码
# 淘宝商品比价
import requests
import re
from prettytable import PrettyTable
import prettytable as pt
def getHtmlText(url):
try:
header = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'sec-fetch-user': '?1',
'accept': ',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'referer': 'https://s.taobao.com/search?s=44',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': ,
}
r = requests.get(url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("爬取失败")
return ""
def parsePage(ilist, html):
try:
plt = re.findall(r'"view_price":"\d+.\d*"', html)
tlt = re.findall(r'"raw_title":".*?"', html)
# print(tlt)
print(len(plt))
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilist.append([title, price])
# print(ilist)
except:
print("解析出错")
def printGoodsList(ilist, num):
table = PrettyTable(["序号", "商品名称", "价格"])
count = 0
for g in ilist:
count += 1
if count <= num:
table.add_row([count,g[0],g[1]])
print(table)
def main():
goods = "书包"
depth = 1
start_url = "https://s.taobao.com/search?q=" + goods
infoList = []
num = 20
for i in range(depth):
try:
url = start_url + '$S=' + str(44 * i)
html = getHtmlText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList, num)
main()
分析解析部分:
def parsePage(ilist, html):
try:
plt = re.findall(r'"view_price":"\d+.\d*"', html)
tlt = re.findall(r'"raw_title":".*?"', html)
# print(tlt)
print(len(plt))
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilist.append([title, price])
# print(ilist)
except:
print("解析出错")
r'"view_price":"\d+.\d*"' 字符串前面加上r表示是纯字符串" \ “就是” \ “,没有转义字符串的意思,“view_price”:”\d+.\d*“对应的就是"view_price”:“150.00”。
- 首先\d表示数字,+号表示扩展所以\d+就可以匹配150
- 原始字符串的" . “与匹配的字符串的” . "对应
- \d表示数字, * 表示前一个字符0次或者无限次扩展对应的就是00
eval(plt[i].split(':')[1])这里将匹配出来的字符串做一个分割,以 “ : ”分割,列表的索引1上的的就是我们要的“ 150.00 ”,通过eval内置函数去掉外层双引号,就是150.00了。
分析headers部分
header = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'sec-fetch-user': '?1',
'accept': ',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'referer': 'https://s.taobao.com/search?s=44',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': ,
}
这里我把cookie和accept部分删去了(保护个人数据安全)
这一部分是通过网页生成的,不加headers的话无法爬取淘宝的信息需要图片验证登陆,那我们可以先登陆淘宝,然后用google浏览器的检查工具查看search信息,然后用一个工具生成登陆成功的headers就可以模拟登陆,具体教程在这:生成headers教程