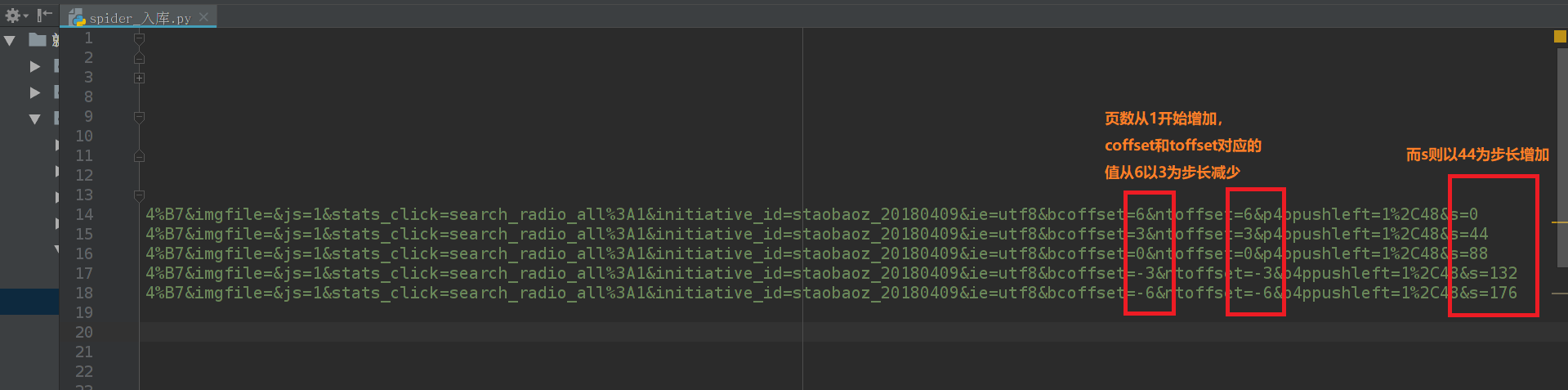
<撸代码前的准备>结论如下:

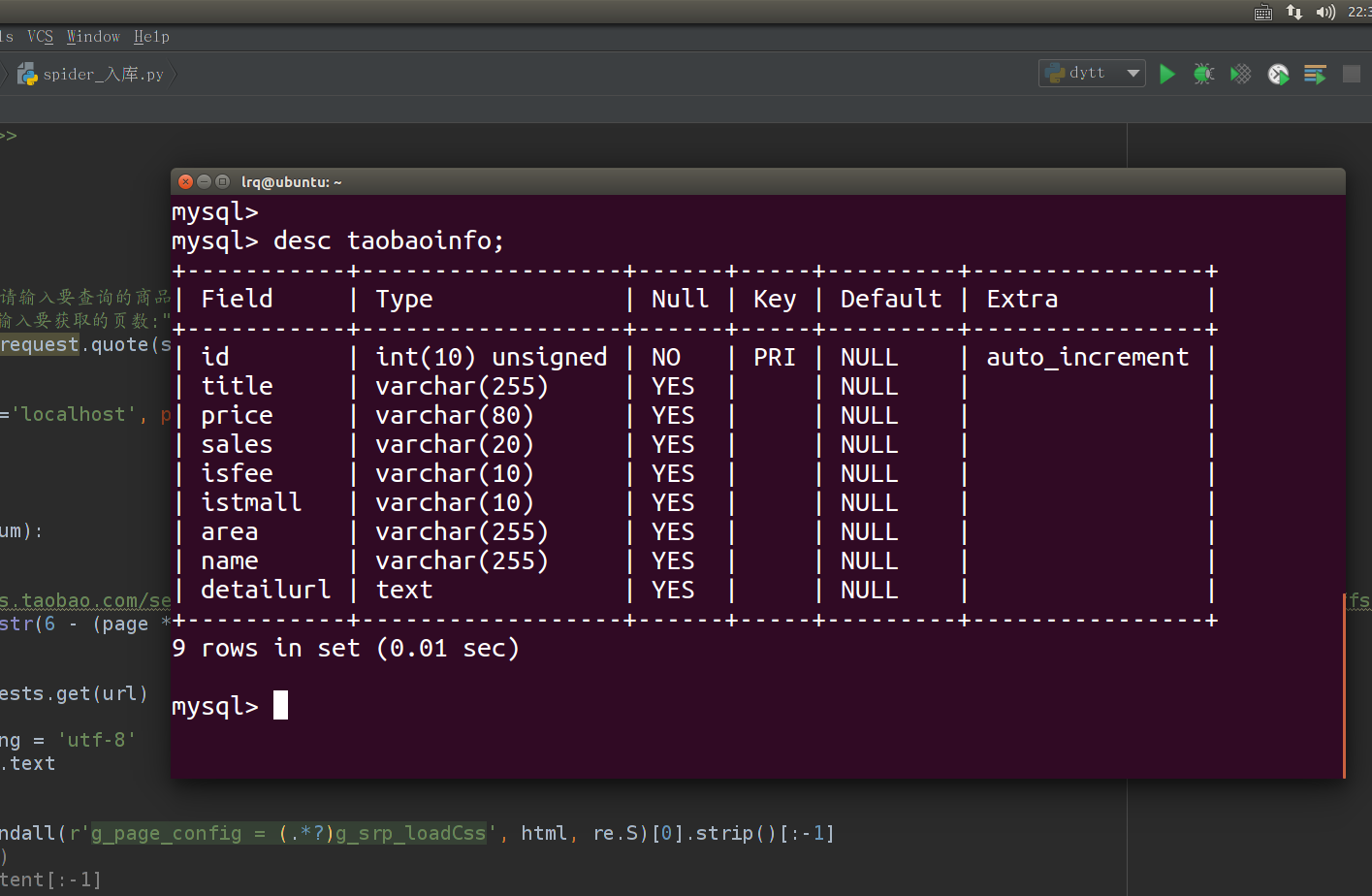
<数据库字段设计>:
<开始撸代码>废话不多说,直接上代码:
# _*_ coding:utf-8 _*_
# Author:liu
import requests
import re
import json
import urllib
from pymysql import *
'''
获取淘宝商品信息
'''
def main():
show_info = input("请输入要查询的商品名称:")
num = int(input("请输入要获取的页数:"))
show_info = urllib.request.quote(show_info)
# 创建Connection连接
conn = connect(host='localhost', port=3306, database='taobao', user='root', password='000000', charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
# 循环页数
for page in range(num):
# 拼装地址
url = "https://s.taobao.com/search?q={}&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180409&ie=utf8&bcoffset={}&ntoffset={}&p4ppushleft=1%2C48&s={}".format(
show_info, str(6 - (page * 3)), str(6 - (page * 3)), str(page * 44))
# 发送http请求
response = requests.get(url)
# 得到网页源码
response.encoding = 'utf-8'
html = response.text
# print(html)
# 正则匹配出数据
content = re.findall(r'g_page_config = (.*?)g_srp_loadCss', html, re.S)[0].strip()[:-1]
# print(content)
# content = content[:-1]
# 格式化json
content = json.loads(content)
# 获取商品信息列表
data_list = content['mods']['itemlist']['data']['auctions']
# 提取数据
# 标题 标价 购买人数 是否包邮 是否天猫 地区 店名 url
for item in data_list:
try:
# 提取数据保存到字典中
temp = {
'title': item['title'],
'view_price': item['view_price'],
'view_sales': item['view_sales'],
'view_fee': '否' if float(item['view_fee']) else '是',
'isTmall': '是' if item['shopcard']['isTmall'] else '否',
'area': item['item_loc'],
'name': item['nick'],
'detail_url': item['detail_url'],
}
title = temp['title']
title = re.sub(r'</?.*?>', "", title, re.S)
detail_url = str(temp['detail_url'])
view_sales = re.findall(r'(\d+)', temp['view_sales'])[0]
# 创建sql语句
sql = "insert into taobaoinfo(title,price,sales,isfee,istmall,area,name,detailurl) values ('{}','{}','{}','{}','{}','{}','{}','{}')".format(
str(title), temp['view_price'], str(view_sales),
temp['view_fee'], temp['isTmall'],
temp['area'],
temp['name'],
detail_url)
# 添加数据
cs.execute(sql)
except Exception as e:
print(e)
print('------第%s页下载完成----------' % str(page + 1))
# 提交操作
conn.commit()
# 关闭连接
cs.close()
conn.close()
if __name__ == '__main__':
main()
<GitHub项目地址:https://github.com/lrq154439/crawl_web_-.git>
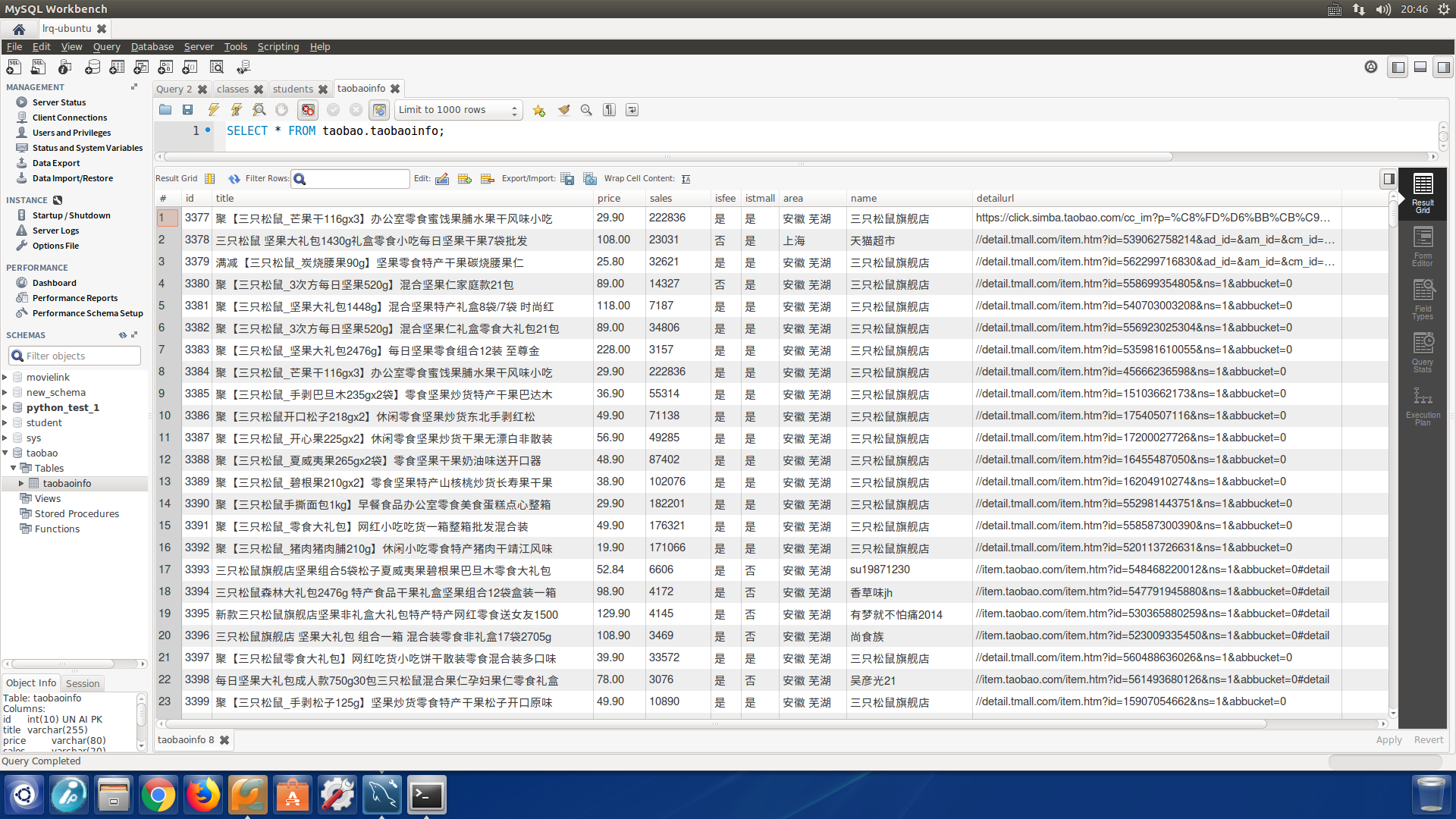
<效果展示>