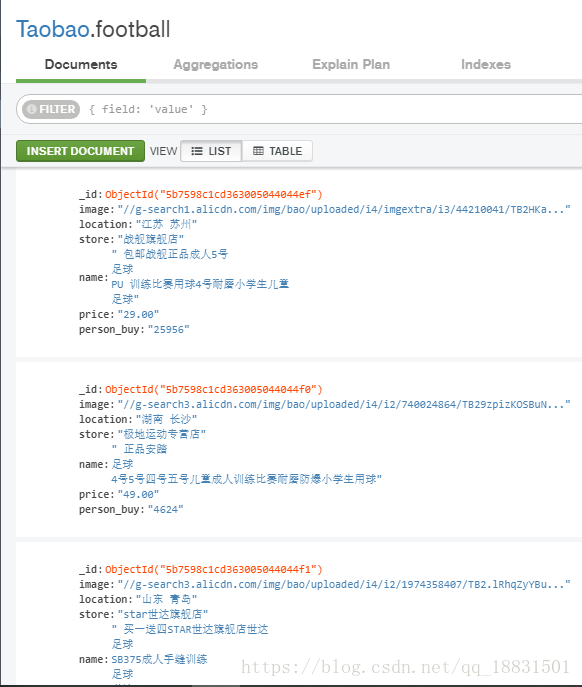
思路就是用selenium操作浏览器,访问淘宝,输入关键词,查找,用pyquery解析目标信息,翻页,存储到mongodb.
函数定义三个:
1 打开浏览器,查找初始化,翻页
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_page(page):
#实例化一个等待,默认等待2秒
wait = WebDriverWait(browser,2)
input = wait.until(EC.presence_of_element_located((By.ID,'q')))
input.send_keys('足球')
#显示等待,并设置等待条件,EC下有多种条件可选择,这里是可点击;By方法决定匹配节点的标准,这里是xpath;
enter = wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="J_SearchForm"]/div/div[1]/button')))
enter.click()
for i in range(page):
#这里'>'是用来选取子节点用的;比较节点的值和页数是否相等,即判断当前页数是否正确
current_page = wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager li.item.active > span'),str(i+1)))
#等待条件,目标信息是否加载出来
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
print(i+1)
for index,item in enumerate(crawl()):
save_to_mongo(item)
print(index,item)
#处理完一页就进行翻页
next_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.form .input.J_Input')))
next_page.clear()
next_page.send_keys(i+2)
confirm = browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]')
confirm.click()2 解析源代码,选取目标信息
from pyquery import PyQuery as pq
def crawl():
#用pyquery处理源代码
source = pq(browser.page_source)
#items()转化为枚举类型
items = source.find('#mainsrp-itemlist .items .item').items()
for item in items:
body={}
body['image']=item.find('.pic .img').attr('data-src')
body['price']=item('.price').text()[2:]
body['person_buy']=item('.deal-cnt').text()[:-3]
body['name']=item.find('.J_ClickStat').text()
body['store']=item('.shopname').text()
body['location']=item('.location').text()
yield body3 存储到mongodb
from pymongo import MongoClient
mongo = MongoClient()
db = mongo['Taobao']
goods = db['goods']
def save_to_mongo(data):
try:
football.insert(data)
except:
print('存储失败')还有不打开浏览器的模式,加入参数chrome_options即可。
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://s.taobao.com')结果展示
mongo中