版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_25343557/article/details/82668359
上文学习了Selenium,本文使用它爬取淘宝搜索到的商品信息,并且将数据存储在MongoDB中。
爬取步骤
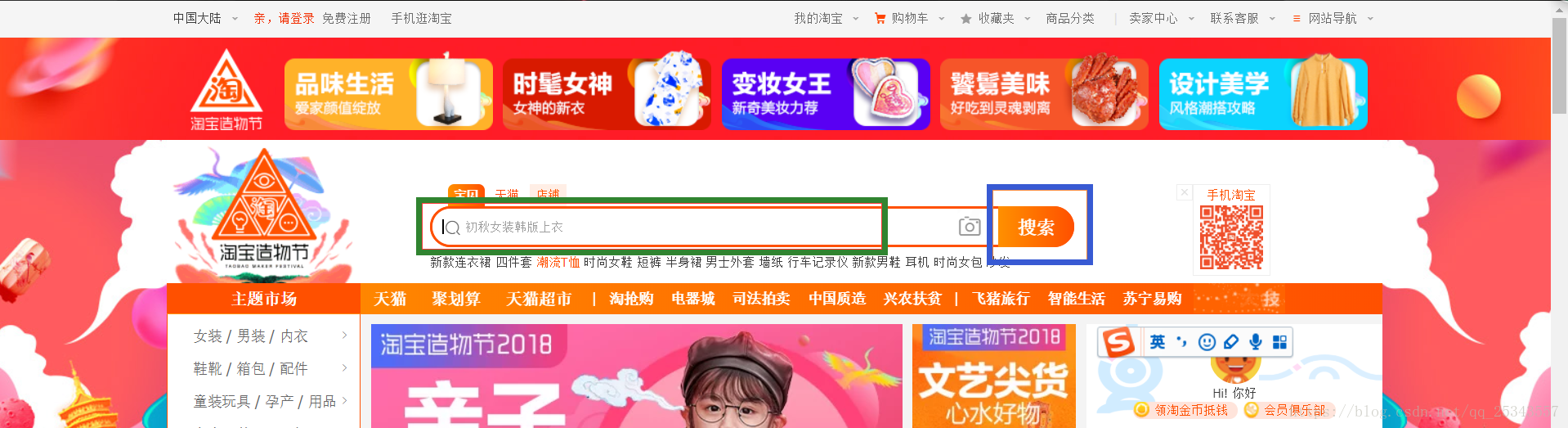
1、进入淘宝首页,获取输入框和搜索按钮
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
def search(keyword):
try:
browser.get('https://www.taobao.com')
input_k = wait.until(EC.presence_of_element_located((By.ID,'q')))#找到输入框
search_btn = wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="J_TSearchForm"]/div[1]/button')))#找到搜索按钮
input_k.clear()#清空输入框内容
input_k.send_keys(keyword)#输入搜索的商品名
search_btn.click()#模拟点击搜索按钮
except TimeoutException:
search(keyword)2、进入搜索结果页面,获取爬取的总页数
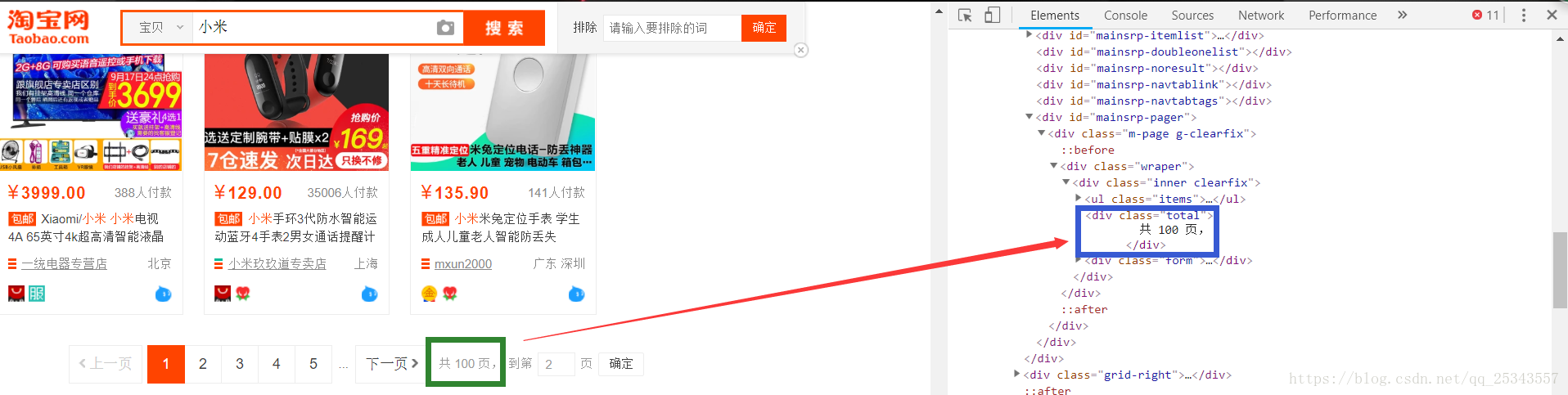
def get_page_number():
try:
return int(wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))).text[1:-2])#因为文本为“共**页,”,所以需要进行切片
except TimeoutException:
get_page_number()3、实现页面逐页跳转
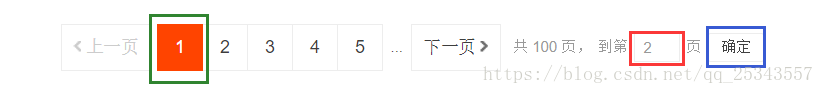
- 通过向输入框中输入待跳转页面,点击确定按钮进行页面的跳转,发生异常重新跳转;
def next_page(pagenumber):
try:
input_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))#获取页码输入框
confirm_btn = wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]')))#获取确定按钮
input_page.clear()#输入页码前需要清空
input_page.send_keys(pagenumber)#输入跳转页码
confirm_btn.click()
get_products(pagenumber)#执行获取商品信息操作
except TimeoutException:
next_page(pagenumber)#发生异常重新跳转4、等待商品信息加载,解析商品信息
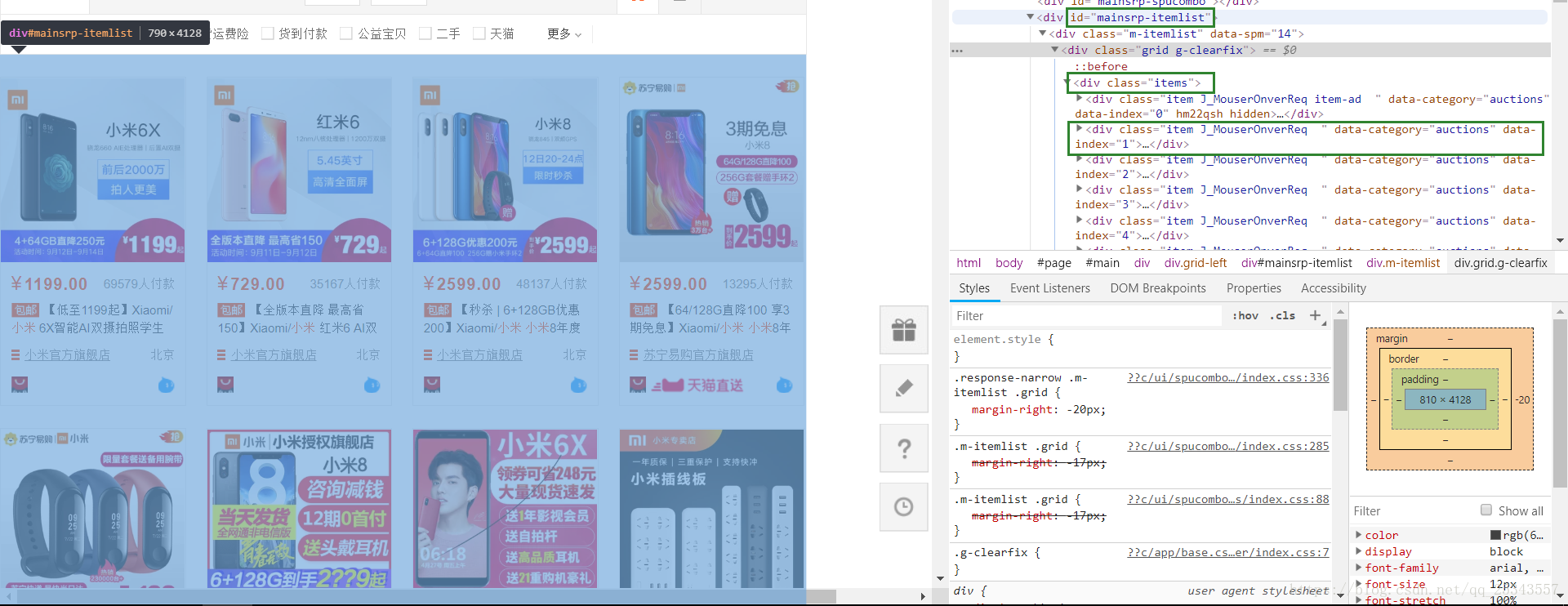
- 首先通过比较高亮页码数是否等于跳转页码判断是否跳转成功,成功则继续,否则重新跳转。
- 等待所有的item都加载出来,如果加载失败则重新进入此页码,否则解析商品信息并存储。
def get_products(pagenumber):
try:
wait.until(EC.text_to_be_present_in_element(
(By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(pagenumber)))#判断高亮页码是否为跳转页码
wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '#mainsrp-itemlist .m-itemlist .items .item'))) # 等待所有商品加载完成
html = pq(browser.page_source)#使用pyquery解析页面
items = html('#mainsrp-itemlist .m-itemlist .items .item').items()
for item in items:
product = {
'title':item.find('.title').text(),
'img':item.find('.pic .img').attr('data-src'),
'price':item.find('.price').text()[2:],
'deal':item.find('.deal-cnt').text()[:-3],
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
save_data(product)#存储到MongoDB
except TimeoutException:
next_page(pagenumber)#跳转失败或者加载失败重新跳转该页面5、将商品信息存入MongoDB
MONGODB_URL = 'localhost'
MONGODB_DB = 'taobao'
MONGODB_COL = 'xiaomi'
client = MongoClient(host=MONGODB_URL)
db = client[MONGODB_DB]
col = db[MONGODB_COL]
def save_data(product):
try:
if col.insert_one(product):
print('存储成功!')
except Exception:
print('存储失败!')6、main方法的编写
if __name__=='__main__':
search('小米')#查询小米的商品
total_pages = get_page_number()#获取总页码数
#获取页码页码就是第一页,直接获取商品信息即可
print("==========================正在获取第1页信息==========================")
get_products(1)
for page in range(2,total_pages+1):#第1页已经获取了,从第2页开始
print("==========================正在获取第%s页信息=========================="%page)
next_page(page)
browser.close()7、无头浏览器
以上代码爬取时总是会有浏览器出现,我们正式爬取时不喜欢出现浏览器,所以我们设置无头浏览器。
option = webdriver.ChromeOptions()
option.add_argument('headless')#设置headless参数,表示无头浏览器
browser = webdriver.Chrome(chrome_options=option)完整代码:链接:https://pan.baidu.com/s/1M29ZjSTxr0CB3jdJgdaDhg 密码:2556