import requests import re def getHTMLText(url): try: #淘宝用了反爬虫机制,必须提取cookie让他认为是用户在操作 headers = { "user-agent": "Mozilla/5.0", "cookie": "miid=1612134452349690119; cna=THqIFiCoTDcCAasjUtS73iNL; t=bbc9a140acd8d518326e1a1d7c9d659d; cookie2=12dbf17b95b0b5e287db790e3c6202f1; v=0; _tb_token_=5183ef37b54d5; _samesite_flag_=true; sgcookie=ExY97bTo2Ovq1IjpIjgji; uc3=id2=UNDUK%2FS2voKDvw%3D%3D&lg2=URm48syIIVrSKA%3D%3D&nk2=AHY2D185rXA%3D&vt3=F8dBxGZuEXJXsog%2BdQI%3D; csg=e8b87b29; lgc=cltt%5Cu5C0F%5Cu9648; dnk=cltt%5Cu5C0F%5Cu9648; skt=bee4d9ccfaf7138b; existShop=MTU4OTg5MzczMw%3D%3D; uc4=id4=0%40UgckEyzZMpFaBzLNri18B0sDs8OZ&nk4=0%40AhhLsGvGLncPumlBqdyreeIqcw%3D%3D; tracknick=cltt%5Cu5C0F%5Cu9648; _cc_=VFC%2FuZ9ajQ%3D%3D; tfstk=cekOBvaPOeYg3-iaaxd3Gve3pwxlaUSToGaAHnubV71Vuh6c3s2jEYFTtCZVWJKd.; mt=ci=64_1; thw=cn; enc=Z2tsLVHv7rciprJdoPFfnnZyK95pCm8ewfzNojqFEtdzPKqxI0juRoRMkxETY%2BWbVCs%2BL%2Boj2XUdNPU0o9010w%3D%3D; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; hng=CN%7Czh-CN%7CCNY%7C156; _m_h5_tk=cdba13bd71a70bac8da9f7717cc536ba_1590040171929; _m_h5_tk_enc=ad9a7ae2e64d058179abbd852424c9a7; uc1=cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&pas=0&cookie14=UoTV7NZUno0ZKw%3D%3D&cookie21=Vq8l%2BKCLjhS4UhJVbhgU&existShop=false; JSESSIONID=A7629614520E309C033FC2F553C818F1; l=eBSghlFHQZ0UoZ_9BOfZnurza77OsIRYnuPzaNbMiOCP_y1p5_wcWZASS9T9CnGVh6qBR3PBVv7HBeYBqnY4n5U62j-la1Dmn; isg=BL6-xLp5bKy6I7j39z6KK6j6D9QA_4J5JGvLwWjHJYH8C17l0I1YiZPph9fHCXqR" } r=requests.get(url,timeout=30,headers=headers) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "" def parsePage(ilt,html): try: plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)#[\d\.]* 找价格:12.03 12.00 1000 具体可参考https://www.cnblogs.com/tingtin/p/12928217.html s = re.findall(r'[\d\.]*','123.3 2.3 1000') tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)#raw_title:""的最小匹配 for i in range(len(plt)): price=eval(plt[i].split(':')[1])#取:后紧跟的数字如"view_price":"69.00" eval去掉"",再取69.00 title=eval(tlt[i].split(':')[1]) ilt.append([price,title]) except: return "" def printGoodsList(ilt): tply="{:4}\t{:8}\t{:16}" print(tply.format("序号","价格","商品价格")) count=0 for g in ilt: count=count+1 print(tply.format(count,g[0],g[1])) def main(): goods="背包"#可以换为其他的 depth=3 strat_url='https://s.taobao.com/search?q='+goods infoList=[] for i in range(depth): try: url=strat_url+"&s="+str(44*i) html=getHTMLText(url) parsePage(infoList,html) except: continue printGoodsList(infoList) main()
cookie
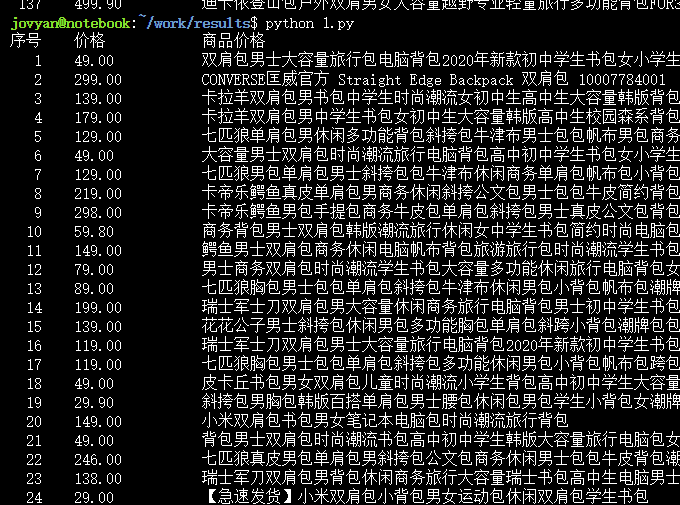
爬取的结果