一. 淘宝商品信息定向爬虫
注意淘宝的robots.txt不允许任何爬虫爬取,我们只在技术层面探讨这一章节的内容。
二. 爬虫基础:正则表达式
- 完整版正则表达式的详细介绍见本人的这篇博客:
博客链接
三. 淘宝页面查看与分析
- 功能描述:
目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
理解:淘宝的搜索接口
翻页的处理
技术路线:requests-re - 淘宝商品信息起始页
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 - 第二页
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44 - 第三页
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
- 淘宝界面源代码:
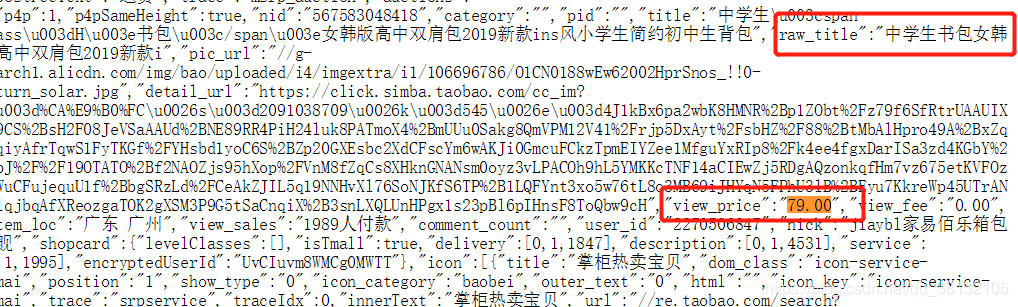
- 我们查看淘宝的源代码:发现,价格字段由’view_price’来标识,商品名称字段由’raw_title’来标识。因此如果我们想要获得这两个信息,只要在获得的文本中检索到其中的view_price和raw_title并把后续的相关内容提取出来即可。
- 从众多的文本中提取我们想要的信息,用正则表达式是非常合适的。另一个重要原因是,淘宝页面的商品信息虽然包含在html页面中,但它是一种脚本语言的体现,并不是完整的html页面的表示,它使用了动态脚本js,所以我们这里bs4库九无能为力了。
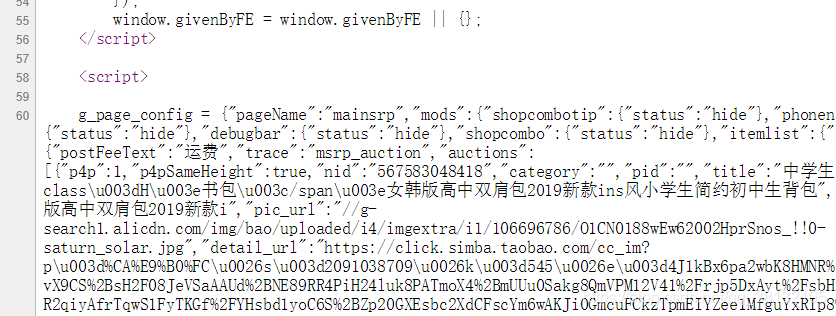
- 按嵩老师给的方法,现在已经不能够爬取内容。

- 现在需要模拟浏览器的header,也可以说是cookie,如下所示:
(1):首先登陆自己的淘宝账户
(2):在淘宝首页搜索书包
(3):在下方界面右键点击检查(以Chrome为例)
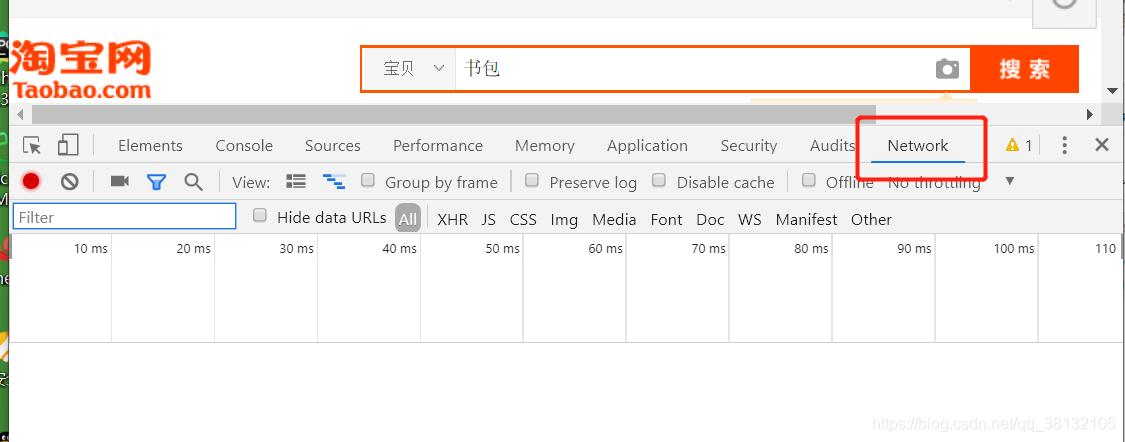
- 点击network,然后不要关闭检查界面,点击浏览器的刷新按钮,这时会出现很多文件
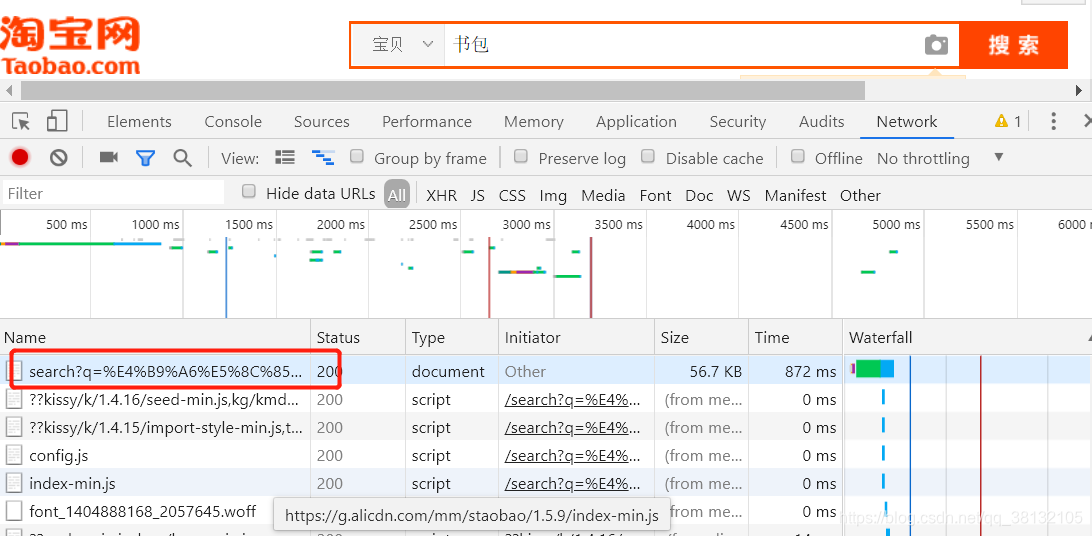
- 在红框文件处右键,选择Copy as cURL(bash)转到网址点击:https://curl.trillworks.com/,不要关闭淘宝界面,因为界面关闭后cookie只能维持一小段时间。关机之后爬取仍需重新粘贴新的headers。
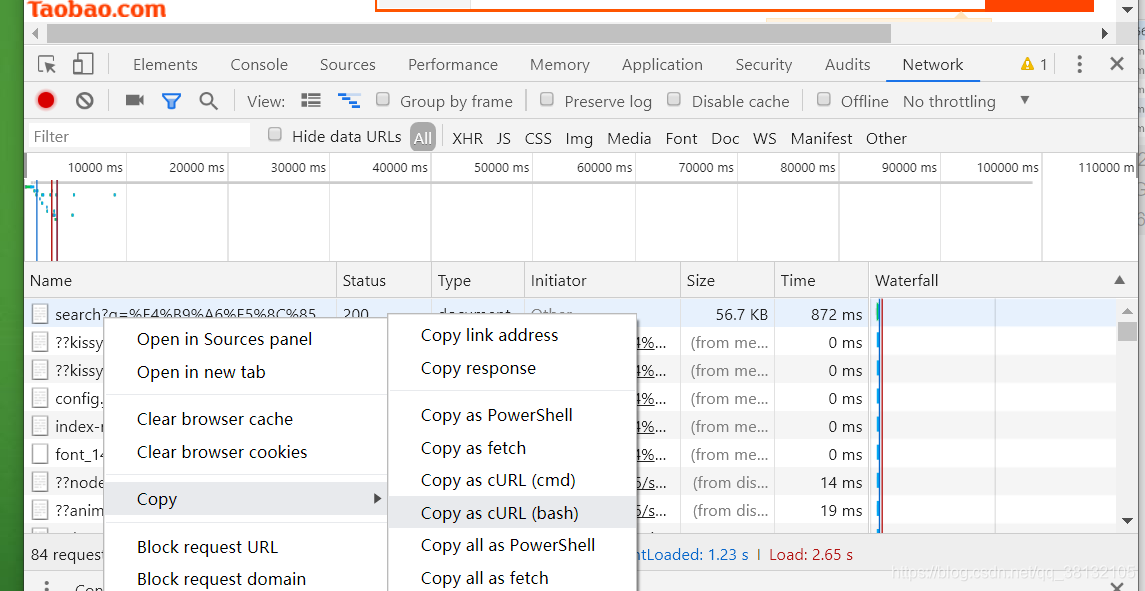
- 将复制内容,粘贴到curl command,可以规范代码格式。再复制Python requests里的
headers = {
}
- 里的内容即可,放到自己的代码中。

四. 爬虫源码
- 爬虫源码,在Python环境中运行即可:
import requests
import re
def getHTMLText(url):
try:
# ***********************************************************
# 下方的header的字符串填上自己的浏览器生成的内容
# ***********************************************************
header = {
'authority': '',
'cache-control': '',
'upgrade-insecure-requests': '',
'user-agent': '',
'accept': '',
'referer': '',
'accept-encoding': '',
'accept-language': '',
'cookie': '',
}
r = requests.get(url, headers = header)
r.raise_for_status()
r.encoding = r.apparent_encoding
# print(r.request.headers)
return r.text
except:
return ""
def parserPage(ilt, html):
"""parserPage()函数用来解析返回的html页面"""
try:
# 老师的教程上这里在原始字符串里用了转义符,可以不用,但在\.这里必须用
# 因为.也是正则表达式里的一个特殊字符,用\.转义表示是真正的小数点
# 用变量plt来接受findall()方法返回的列表
# plt所存储的列表的内容是html中所有满足正则表达式
# r'"view_price":"\d+\.\d*"'的字符串,以列表形式返回
plt = re.findall(r'"view_price":"\d+\.\d*"', html)
# 用变量tlt存储返回的title信息列表
tlt = re.findall(r'"raw_title":".*?"', html)
# 遍历列表plt
for i in range(len(plt)):
# 把plt列表中的第i个字符串拿出来,并用:分割,将价格以字符串形式返回
# eval()将字符串类型的价格转化为整形
price = eval(plt[i].split(':')[1])
# title这里可以加eval(),输出时不带引号,也可以不加,自己实验
title = tlt[i].split(':')[1]
# 将price和title组成的列表追加到ilt列表中
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
"""printGoodsList()函数打印商品信息"""
# tplt定义了一个待格式化的字符串
tplt = "{:4}\t{:8}\t{:16}"
# tplt调用format()方法,按次序将字符串填入相对应的{}中
print(tplt.format("序号", "价格", "商品名称"))
# 定义一个计数器,用于输出序号
count = 0
for g in ilt:
# 遍历列表ilt
count += 1
# 格式化输出序号count,价格g[0],商品名称g[1]
print(tplt.format(count, g[0], g[1]))
def main():
# 定义要搜索的商品名
goods = '书包'
# 定义爬取的深度
depth = 2
# 定义爬取的url
start_url = 'https://s.taobao.com/search?q=' + goods
# 定义空列表
infoList = []
# 遍历每一页的内容
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parserPage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
- 注意淘宝的robots.txt不允许任何爬虫爬取,我们只在技术层面探讨这一章节的内容。
仅供教学,请勿对淘宝网造成性能干扰。