K近邻算法
前言:本人是看了几位大佬和机器学习有关的书籍之后,对该算法的一些深刻体会,鉴于这是入门算法比较适合我这种新手,初次写博客,不足的地方,请多多指教!
一、KNN算法简述
KNN来自英文缩写(K Nearest Neighbor),顾名思义,K个与样本数据相邻的邻居,k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。接下来,我们用一张可视化的图看看,如下图所示:
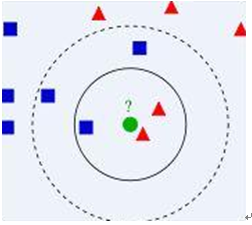
假设一个二维空间内存在蓝色正方形和红色三角形两类数据,这时候若存在一个圆形的绿色数据,我们应该怎样区分它到底属于哪类数据集,我们应该怎样去分类呢?这样我们就用到了KNN算法,首先将距离绿色的点最近的几个数据找到,以绿色的圆圈为圆点任意半径画圆,这时候困扰的是我们到底选则附近几个点作为依据呢?这里我们选取的是3,即K=3,则是选取距离绿色点四周最近的三个点作为评判依据,因为这里红色:绿色的数量比是2:1,所以我们认为绿色与红色是一类;如果这里我们选取K=5,即以第二个圆半径之内的点数量作为评判依据,这时候红色则是只占据了2/5,因此绿色圆被赋予蓝色四方形类。从这里可以看到,k的值还是很重要的。这里我们一般规定K的只不超过20。
二、KNN实例
2.1简介
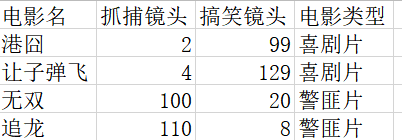
假设存在这样的一个数据集,也可叫做训练数据(trains datas),并且每一个数据都存在其对应的特征标签,即样本数据每一个数据都有其对应的标签数据。这里举一个例子,我们这里使用KNN算法辨别某部电影是警匪片还是喜剧片如下图所示:
假设我们先生成一些有关电影分类的数据,我们可以用numpy模块直接创建,有关代码如下:
def createDataSet():
#四组二维特征
group = np.array([[2,99],[4,129],[100,20],[110,8]])
#四组特征的标签
labels = [‘喜剧片’,‘喜剧片’,‘警匪片’,‘警匪片’]
return group, labels
if name == ‘main’:
#创建数据集
group, labels = createDataSet()
#打印数据集
print(group)
print(labels)
运行结果,如图1所示:
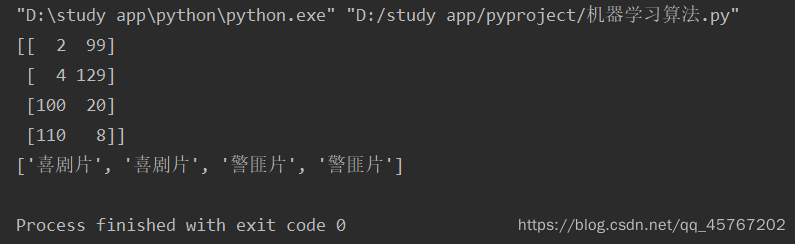
图1数据图
这个数据集有两个特征,即搞笑镜头数目和追捕镜头数目。除此之外,我们也知道每个电影的所属类型,即分类标签。用肉眼大致粗略地观察,搞笑镜头多的,是喜剧片。抓捕镜头镜头多的,是动作片。以我们多年的看片经验,这个分类还算合理。如果现在给我一部电影,你告诉我这个电影搞笑镜头数和抓捕镜头数。我可以判断出这个电影类型。而k-近邻算法也可以像我们人一样做到这一点,不同的地方在于,我们的经验更直观真实,而k-邻近算法是靠已有的数据推测出相应的结论。例如,你告诉我这个电影搞笑镜头数为2,抓捕镜头数为102,我的经验会告诉你这个是警匪片,k-近邻算法也会告诉你这个是警匪片。你又告诉我另一个电影搞笑镜头数为34,警匪镜头数为32,我可能会傻傻的告诉你这可能是“搞笑喜剧片”,但是K近邻算法不会这样决定,它只会以一种最优的衡量标准,抉择出最相似特征数据的分类标签。
2.2分类标准-距离的计算
由上文我们已经了解K近邻算法是将各类特征数据进行比较分类,然后提取出最相似的一些数据的分类标签,那么我们应该如何去比较呢?以一个什么样的标准去衡量一个分类依据呢?难道真的就像上文提到的,我们光靠肉眼去目测距离远近吗?我们先看下图2所示:
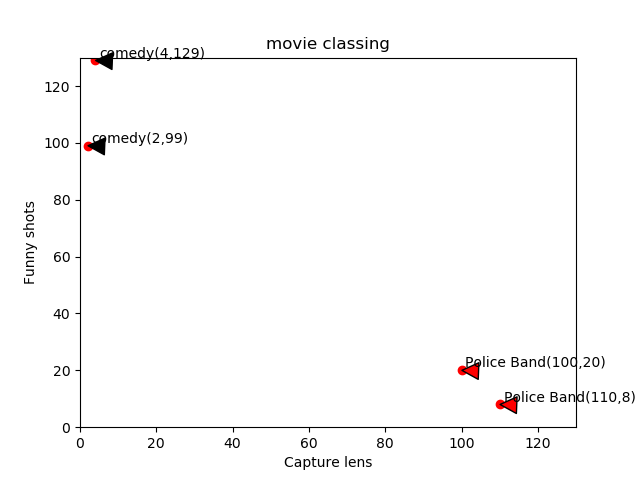
图2 电影分类
假设现在给我们一点测试数据P点(101,20)我们可以从散点图大致可以推断,这个圆点标记的电影可能属于警匪片,因为距离已知的那两个动作片的圆点更近。k-近邻算法用什么方法进行判断呢?没错,就是距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,这样的距离公式我们就要用到高中在直角坐标系中计算两点之间的距离公式,如图3所示: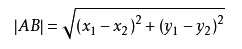 图3两点距离公式
图3两点距离公式
通过计算我们发现,很明显该点与图中警匪片的距离要更近,那样我们可以得出TEST数据点P是警匪片,也就是让我们预测的电影类型为警匪片,但是,这里我们直接通过计算的方法并不是K近邻算法的思想?那么如果我们用K近邻算法的思想来推测,步骤如下:
(1)首先分别计算待测数据与已知特征数据之间的距离;
(2)再按照距离递增次序排序;
(3)确定K值(一般K值的选取按照分界线差值较大的数据为分界点);
(4)确定前k个点所在类别的出现频率,返回前k个点所出现频率最高的类别标签作为当前点的预测分类。
比如我这里选取K的值为3,那么通过计算距离可得知,按照距离从小到大的顺序排列,而其每个点所对应的标签数据为警匪片(100,20),警匪片(110,8),喜剧片(2,99),在这三个点中,警匪片出现的频率为2/3,喜剧片出现的频率为1/3,因此我们从此推断该P点所对应的人电影类别是警匪片。这个判别过程就是K近邻算法。
三.python代码实现
完整代码如下:
-- coding: UTF-8 --
import numpy as np
import operator
def createDataSet():
#四组二维特征
group = np.array([[2,99],[4,129],[100,20],[110,8]])
#四组特征的标签
labels = [‘喜剧片’,‘喜剧片’,‘警匪片’,‘警匪片’]
return group, labels
“”"
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
Modify:
2020-02-16
“”"
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
if name == ‘main’:
#创建数据集
group, labels = createDataSet()
#测试集
testdata = [101,20]
#kNN分类
test_class = classify0(testdata, group, labels, 3)
#打印分类结果
print(test_class)
这里我们用的是P点(101,20),预测P点所对应的电影类别,KNN的K值取的是3,运行结果如下:
由图可知,该片为警匪片。
四.总结
KNN算法有效解决了分类,回归预测问题,它简单实用。本人才疏学浅,本文还有很多不足,望大佬们提出宝贵意见,谢谢o-o。
