接下来我将会整理机器学习的一些基本算法的理论知识和python代码实现,我也是初学者,如果我文中出现的理解、逻辑以及代码的错误,希望大家及时指正,共同进步。
一、概念
邻近算法,或者是K最近邻算法(KNN, k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻就是K个最近的邻居的意思,就是K个距离测试数据最近的训练数据,不过其中的距离又可以分为欧式距离和曼哈顿距离。
欧式距离:就是直角三角形斜边的距离,就是两点之间的直线距离,
曼哈顿距离:就是直角三角形两条直角边的距离之和。

二、思想
KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特征。该方法在确定分类决策上只依据最近邻的一个或者几个样本来决定自身的类别属性,因此伴随着相应的优缺点。如下图:

距离绿色在特征空间中,K等于3的时候,两个红色三角形,一个蓝色正方形,将会判断为红色类型,而如果K=5的时候将会将其划分到蓝色类型。其实从这张图中就可以看出来KNN有一定的优缺点。
三、优缺点及改进策略
1、优点
1) 简单、易于理解,易于实现,无需估计参数,无需训练
2) 适合对稀有事件进行分类
3) 特别适合于多分类问题(multi-modal, 对象具有多个类别标签),KNN比SVM的表现要好
2、缺点
1) 当样本量不足时,如果一个类别样本量很大,其它类别样本量很小,如果K值过大有可能导致测试时大容量样本占比高,不过如果大容量样本距离测试样本距离较远则不会影响测试结果。
2) 计算量比较大,因为每一个测试样本都会和所有的训练样本测距,如果训练样本过大则计算时间太长,并且每一个测试样本会进行新一轮的重复的计算。
3、改进策略
每一个算法都会经历时间和测试来检验出一些不足,KNN也是如此。针对其不足,算法的改进方向主要时分类效率和分类效果两个方面。
1) 分类效率:可以事先对数据样本进行约简、删除一些对分类影响小的样本,减少计算量。该优化适用于样本比较大的情况。
2) 分类效果:为K个邻居增加权值的方法,①就是越靠近可以将这个类别的权重分配的大点,K个近邻中靠后的几个权重占比小点;②或者人为的将不同容量的样本通过权重来优化,即如果最近邻时容量小的那么可以让其占比大点,邻居是容量大的占比小点,这样来平衡不均衡样本。
四、python实现
1、分类算法
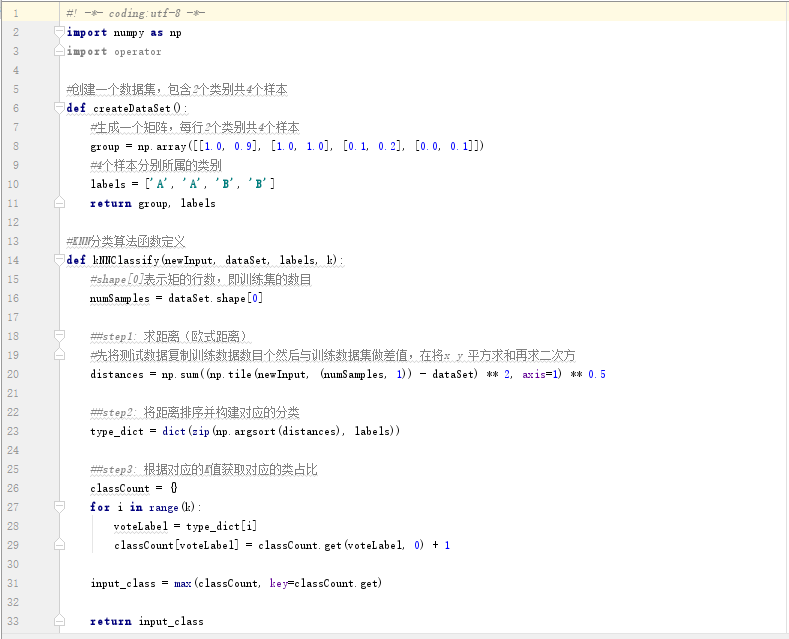
2、测试文件

3、测试结果

4、官方包使用例子
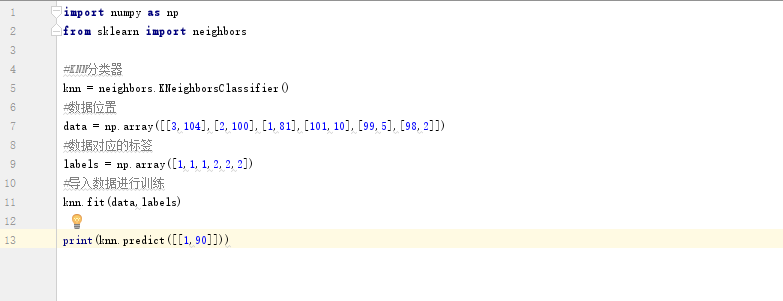
注意:可以通过调整K值得大小来获取不同个近邻后得分类结果。