博客作者:凌逆战
论文地址:https://ieeexplore.ieee.xilesou.top/abstract/document/8683611/
地址:https://www.cnblogs.com/LXP-Never/p/10714401.html
利用条件变分自动编码器进行人工带宽扩展的潜在表示学习
作者:Pramod Bachhav, Massimiliano Todisco and Nicholas Evans
摘要
当宽带设备与窄带设备或基础设施一起使用时,人工带宽扩展(ABE)算法可以提高语音质量。大多数ABE解决方案都使用某种形式的memory(记忆),这意味着高维特性表示会增加延迟和复杂性。因此发展了降维技术以保持效率。因此提取紧凑的低维表示,然后与标准回归模型一起用于估计高频段分量。
以往的研究表明,某种形式的监督对于优化ABE的降维技术至关重要。本论文研究了条件变分自动编码器(conditional variational auto-encoders,CVAEs)在监督降维中的首次应用。利用有向图模型的CVAEs对高维对数谱数据进行建模,提取潜在的窄带表示法。
与其他降维技术的结果相比,客观和主观的评估表明,使用CVAEs学习的潜在概率表示产生的带宽扩展语音信号质量显著提高。
index Terms(索引项):变分自动编码器,潜在变量,人工带宽扩展,降维,语音质量
1 介绍
传统窄带(NB)网络和设备通常支持0.3-3.4kHz的带宽。为了提高语音质量,今天的宽带(WB)网络支持50Hz-7kHz的带宽。随着NB网络向WB网络的过渡,需要大量的投资[1],人工带宽扩展(ABE)算法被开发出来,当WB设备与NB设备或基础设施一起使用时,可以提高语音质量。ABE用于从可用NB分量中估计缺失的3.4kHz以上的highband(高带)(HB)频率分量,通常使用从大量WB训练数据中学习的回归模型。
ABE算法要么使用经典的源滤波器模型[2,3],要么直接对复杂的短期频谱估计进行操作[4,6]。在这两种方法中,使用contextual information(上下文信息)或memory(记忆),可以更可靠地估计HB成分。一些特定的back-end(后端)regression(回归)模型[7 9]以时间信息的形式捕获memory,而其他解决方案[4、10、11]则相反地在front-end(前端)捕获记忆,例如通过delta特征或从相邻帧提取的静态特征。虽然memory的使用提高了ABE的性能,但它意味着使用更高维度的特性,因此,ABE回归模型更复杂,计算要求更高。考虑到ABE通常需要在电池驱动的设备上运行,这是不可取的。
为了减少复杂性的增加,[12,13]研究了在固定维度的约束下,通过delta mel频率倒谱系数(MFCC)包含记忆。然而,研究发现,互信息的增益被MFCC inversion(转换)中涉及的重建伪影所抵消[13]。我们自己的工作[14]提出了一种方法,将memory(记忆)以相邻帧的静态特性的形式包含进来。为了保持效率,采用了降维方法。我们后续的工作[15]表明,由对数谱系数组成的memory(记忆)可以使用半监督堆叠自动编码器(semi-supervised stacked auto-encoders, SSAE)学习一种紧凑的、低维的ABE特征表示。本文的工作旨在探索生成建模技术的应用,以进一步提高ABE性能。目标是对高维谱数据(包括memory(记忆))的分布建模,并提取更高层次、更低维的特征,从而在不影响复杂性的情况下提高ABE回归模型的可靠性。从本质上讲,我们寻求一种专门针对ABE的降维(DR)形式。
变分自编码器(VAEs)及其条件变分自动编码器(CVAEs)概率深度生成模型能够对复杂的数据分布进行建模。与堆叠式自动编码器(SAEs)学习的瓶颈特性相比,隐藏表示是概率的,可以用来生成新的数据。受其在图像处理中的成功应用[16 18]的启发,它们在众多的语音处理领域越来越受欢迎,如语音建模与转换[19,20]、语音转换[21]、语音合成[22]、语音增强用于语音活动检测[23]、情感识别[24]和音频源分离[25]。
CVAEs通过combination(联合)潜在变量和条件变量来生成数据。本文工作的思路是通过辅助神经网络对条件变量进行优化,以学习higher-level(更高层次)的NB特征,这些特征是针对ABE任务中缺失HB分量的估计而定制的。这项工作的新贡献是:
(i) 第一次将VAEs和CVAEs应用于DR的回归任务,如ABE;
(ii) 将CVAE与probabilistic encoder(概率编码器)结合,以auriliary(辅助)神经网络的形式,得到条件变量;
(iii) 联合优化的一种方法;
(iv) 他们应用于extract(提取)probabilistic(概率)NB潜在表示,以估计在其他标准ABE框架中丢失的HB数据;
(v) 所提出的方法来大幅提高ABE性能。
本文的其余部分组织如下。第2节描述了基线ABE算法。第3节介绍了基于VAE和CVAE的特征提取方案,第4节实验,第5节结论。
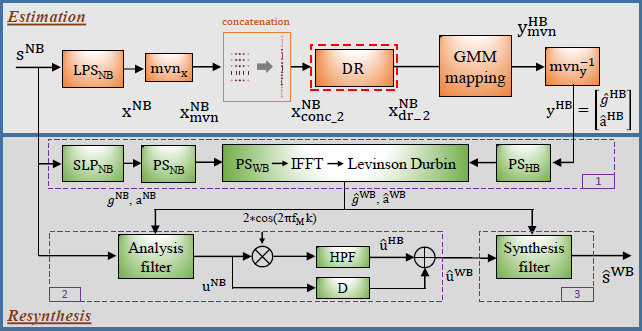
图1 基线ABE系统框图。图改编自[14]
2 基线系统
图1显示了基线ABE系统。它与[14](作者自己的文章)中提出的基于源滤波器模型的方法是一致的。因此,这里只提供一个简要的概述。该算法由 估计 和 再合成 两部分组成。
Estimation(估计) 使用1024点FFT处理持续时间为20 ms、采样率为16kHz的NB语音帧sNB,extract(提取)200维NB对数功率谱(LPSNB)系数xNB,该系数经过均值和方差归一化(mvn_x)得到的$x_{mvn}^{NB}$。在appent(相加)了2个相邻帧的系数后,得到1000维concatenate(级联)向量$x_{conc\_2}^{NB}$。应用降维(DR)技术提取10维的特征向量$x_{dr\_2}^{NB}$。然后使用传统的基于GMM的映射技术进行估计[2]得到归一化的HB特征$y_{mvn}^{HB}$由9个LP系数和一个gain(增益)参数组成。然后应用反向均值方差归一化($mvn_y^{-1}$)得到HB特征$y^{HB}$。
Resynthesis(再合成)
- 首先(框1),通过选择性线性预测(SLPNB)从语音帧sNB中得到LP参数aNB、gNB,用来得到NB功率谱PSNB。然后将其与HB功率谱PSHB(从HB LP参数$\hat{g}^{HB}$,$\hat{a}^{HB}$中estimated(估计)得到) concatenated(级联),得到WB功率谱PSWB,从而估计WB LP参数$\hat{g}^{HB}$,$\hat{a}^{HB}$。
- 其次(框2),HB激励$\hat{u}^{HB}$是根据NB激励uNB在6.8kHz时的频谱translation(转换)然后经过高通滤波来估算的。然后将NB和HB激励分量相结合,得到扩展的WB激励$\hat{u}^{WB}$。
- 最后(框3),使用$\hat{g}^{WB}$和$\hat{a}^{WB}$定义的合成滤波器对$\hat{u}^{WB}$进行滤波,以重新合成语音帧$\hat{s}^{WB}$。采用传统的overlap(重叠)和相加(overlap and add,OLA)技术来产生扩展的WB语音。
3 使用条件变分自动编码器进行特征提取
在本节中,我们展示了如何将VAE和CVAE体系结构的联合学习用于特征提取,以提高ABE性能。
3.1 VAE(变分自动编码器)
变分自动编码器(variational,VAE)[26]是一个生成模型$p_\theta (x,z)=p_\theta (z)p_\theta (x|z)$(带参数$\theta$),假设其中的数据$\{x^{(i)}\}_{i=1}^N$由N个i组成。随机变量$x$的样本由连续的潜在变量$z$生成,在实际中,求解marginal likelihood(边界似然)$p_{\theta}(x)$和true posterior density(真实后验密度)$p_{\theta}(z|x)$都是棘手的,为了解决这个问题,VAEs使用一个recognition/inference(识别/推理)模型$q_\phi (z|x)$作为后验$p_{\theta}(z|x)$的近似值,单个数据点的边界似然为:
$$公式1:\log p(x)=-D_{KL}[q_\phi (z|x)||p_\theta(z|x)]+L(\theta,\phi ;x)$$
其中第一项表示近似后验分布和真实后验分布之间的Kullback-Leibler (KL)散度(DKL)。为了简单起见,假设近似后验和真后验为对角多元高斯分布,用两种不同的深度神经网络计算其各自的参数$\theta$和$\phi$。
由于KL散度为非负的,$L(\theta,\phi ;x)$表示marginal likelihood(边界似然)的variational(变分)下界,可写为:
$$公式2:L(\theta,\phi ;x)=-D_{KL}[q_{\phi} (z|x)||p(z)]+E_{z_\phi }[\log p_\theta(x|z)]$$
其中,$D_{KL}[·]$作为正则化项,可以通过分析计算得出。在实际应用中,假定先验$p(z)=N(z;0,I)$是中心各向同性多元高斯,没有自由参数。第二项是预期的负重建误差,必须通过抽样估计。使用从识别网络$q_\phi (z|x)$中samples(抽取)的$L$个样本,将其近似为$\frac{1}{L}\sum_{l=1}^L\log p_\theta(x|z^{(l)})$。使用可微确定性映射进行采样,这样$z^{{l}}=g_\phi (x,\epsilon ^{(l)})=\mu (x)+\epsilon ^{(l)}\odot \sigma (x)$,其中$\epsilon ^{(l)}\sim N(0,I)$。$\mu _z=\mu (x)$和$\sigma _z=\sigma(x)$是识别网络$q_\phi (z|x)$的输出。这被称为reparameterization trick(重新参数化技巧)。下界$L$构成目标函数,利用随机梯度下降算法对参数$\theta$和$\phi $进行优化。
3.2 CVAE(条件变分自动编码器)
条件变分自动编码器(CVAE)是一个条件生成模型$p_\theta(y,z|x)=p_\theta(z)p_\theta(y|x,z)$;对于给定的输入$x$,从先验分布$p_\theta(x)$中提取潜在变量$z$,其中分布$p_\theta(y|x,z)$生成输出$y$[17,18]。为了处理棘手的问题,CVAEs也使用近似后验$q_\phi (z|x,y)$。
我们采用了与[18]不同的公式,其中我们假设潜在变量只依赖于输出变量$y$,即$q_\phi (z|x,y)=q_\phi(z|y)$。条件似然$p_\theta(y|x)$的变分下界由下式给出:
$$公式3:\log p_\theta(y|x)\geq L(\theta ,\phi ;x,y)=-D_{KL}[q_\phi (z|y)||p_\theta(z)]+E_{q_\phi (z|y)}[\log p_\theta(y|x,z)]$$
第二项近似为$\frac{1}{L}\sum_{l=1}^L\log p_\theta(y|x,z^{(l)})$;其中$z^{(l)}=g_\phi (y,\epsilon ^{(l)})=\mu (y)+\epsilon ^{(l)}\odot \sigma (y)$其中$\epsilon ^{(l)}\sim N(0,I)$和$\sigma _z=\sigma (y)$是识别网络$q_\phi (y|x,z)$的输出。实际上,每个datapoint(数据点)[26]使用L = 1个样本。CVAE识别网络$q_\phi (z|y)$和生成网络$p_\theta(y|x,z)$采用深度神经网络建模。
公式3中的输出分布$p_\theta(y|x,z)$取高斯函数,平均值为$f(x,z;\theta)$并且covariance matrix(协方差矩阵)为$\sigma^2*I$,即$p_\theta(y|x,z)=N(f(x,z;\theta),\sigma ^2*I)$其中$f$是带有参数$\theta$的x和z的确定性变换。因此
$$公式3:\log p_\theta(y|x,z)=C-||y-f(x,z;\theta)||^2/\alpha $$
其中C是一个常数,在优化过程中可以忽略。标量$\alpha =2\sigma ^2$可以看作是KL-divergence(KL散度)与重构项[27]之间的权重因子。
3.3 提取ABE的潜在表示
本节描述了联合优化VAE和CVAE的方案,为了学习到针对ABE的潜在表示。方案如图2所示。并行训练数据由NB和WB语句组成,帧长为20ms,重叠为10ms。输入数据$x=x_{conc\_2}^{NB}$由带memory(记忆)的NB LPS系数组成(如第2节所述),输出数据$y=y_{mvn}^{HB}$由9个LP系数和一个从并行HB数据中通过选择性线性预测(SLP)提取的增益参数组成。
首先对VAE进行训练,将编码器$q_{\phi_x}(z_x|x)$(图2底部)由输入数据x进行fed(馈送),以预测均值$\mu_{z_x}$和代表后验分布$q_{\phi_x}(z_x|x)$的log-variance(对数方差)$\log (\sigma _{z_x}^2)$。将对应的解码器$p_{\theta_x}(x|z_x)$(图2未表示出)由输入$z_x\sim q_{\phi _x}(z_x|x)$进行馈送,以预测分布$p_{\theta_x}(x|z_x)$的均值$\mu _x$。这可以看作是初始化编码器$q_{\phi_x}(z_x|x)$权值的某种形式的预训练。注意,在这个阶段,NB表示$z_x$是在没有任何HB数据监督的情况下学习的。然后丢弃VAE解码器。然后使用编码器$q_{\phi_x}(z_x|x)$作为CVAE的条件变量(如图2所示)。
然后训练CVAE对输出$y$的分布进行建模。将HB数据y输入编码器$q_{\phi_y}(z_y|y)$(图2左上网络),以预测均值$\mu_{z_y}$和近似后验分布$q_{\phi_y}(z_y|y)$的log-variance(对数方差)$\log (\sigma _{z_y}^2)$。然后使用预测的参数通过reparameterization trick(重新参数化技巧)获得输出变量$y$的潜在表示$z_y\sim q_{\phi _y}(z_y|y)$(见3.2节)。然后,利用潜在变量$z_x\sim q_{\phi _x}(z_x|x)$作为CVAE condition(条件)变量。串联后,$z_x$和$z_y$输入解码器$p_{\theta_y}(y|z_x,z_y)$(右上的网络),为了预测输出变量$y$的均值$\mu _y=\mu (z_x,z_y)$。最后,对整个网络进行训练,共同学习参数$\phi _x$、$\phi _y$和$\theta _y$。由式(3)、(4)可得优化下等价变分下界为:
$$公式5:\log p_{\theta}(y|z_x)\geq L(\theta_y,\phi _y,\phi _x;z_x,y)=-[D_{KL}[q_{\phi _y}(z_y|y)||p_{\theta_y}(z_y)]+||y-f(z_x,z_y;\theta_y)||^2/\alpha]$$
我们希望,在公式5的优化过程中,对编码器$q_{\phi_x}(z_x|x)$的参数$\phi_x$进行更新,从而使框架学习生成CVAE输出$\hat{y}$的编码信息的潜在表示形式$z_x$。
最后,利用编码器$q_{\phi_x}(z_x|x)$(图2中红色分量表示)对每个$x$估计他们的潜在表示$z_x$,然后使用联合向量$z_x$和$y$学习GMM回归映射[2]。在ABE估计阶段,将DR块(图1中的红色框)由编码器$q_{\phi_x}(z_x|x)$替代,按照第2节中描述的方式进行估计。注意网络$q_{\phi_x}(z_x|x)$和$p_{\phi_y}(y|z_x,z_y)$一起组成一个DNN,有两个随机层$z_x$和$z_y$,这本身可以用于ABE,其中$z_y$是在估计阶段从先验分布$p_{\theta_y}(z_y)=N(0,I)$中采样的。然而,本文报道的工作的目的是利用CVAE学习到的潜在表示$z_x$作为ABE的DR技术。目的是保持回归模型的计算效率。
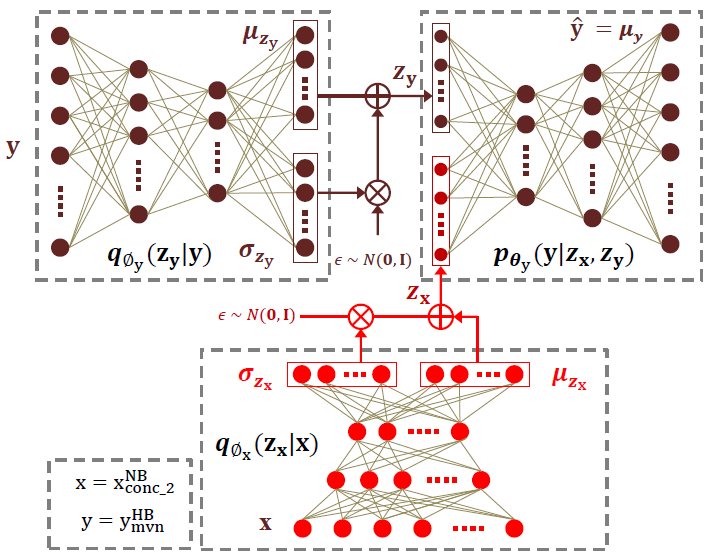
图2 一种基于CVAE的特征提取方案
4 实验设置及结果
本节描述用于ABE实验的数据集,基线和CVAE配置细节和结果。实验的目的是比较ABE系统的性能,该系统使用从CVAE中学习到的特性和使用alternative(替代)DR技术的特性。在所有情况下,性能评估均采用或不采用均值和variance normalisation(方差归一化)。
4.1 数据集
TIMIT数据集[28]用于训练和验证。使用3693个来自训练集的话语和1152个来自测试集(不含核心测试子集)的话语,根据[6]中描述的步骤,并行处理WB和NB语音信号,来训练ABE方案。TIMIT core(核心)测试子集(192条语句)用于验证和网络优化。采用1378个语音组成的The acoustically-different(听觉不同) TSP数据库[29]进行测试。将TSP数据下采样至16kHz,并进行类似的预处理或得并行的WB和NB数据。
4.2 CVAE配置和训练
CVAE体系结构1是使用Keras toolkit[30]实现的。编码器$q_{\phi_x}(z_x|x)$和$q_{\phi_y}(z_y|y)$由两个隐藏层组成,分别为512和256个units(单元),输入层分别为1000和10个单元。它们的输出是由均值$\mu_{z_x}$、$\mu_{z_y}$和对数方差$\sigma _{z_x}$、$\sigma _{z_y}$组成的Gaussian-distributed(高斯分布)的潜在变量层$z_x$和$z_y$,由10个单位组成。解码器$p_{\theta_x}(x|z_x)$和$p_{\theta_y}(x|z_y)$有2个隐藏层,包含256和512个单元。输出层分别有1000和10个单元。所有的隐层都有tanh 激活单元,而高斯参数层有linear 激活单元。log-variances(对数方差)的建模避免了negative(负)方差的估计。
联合进行训练,使用Adam随机优化技术[31]将公式5的负条件对数似然最小化,初始学习率为10-3,超参数$\beta _1=0.9$,$\beta _2=0.999$并且$\epsilon =10^{-8}$。根据[32]中描述的方法对网络进行初始化,以提高收敛速度。为了防止过度拟合,在每个激活层之前应用batch-normalisation(批处理规范化)[33]。当验证损失在连续的5个周期内增加时,学习率降低了一半。首先,VAE对输入数据x进行50个epoch(周期)的训练。然后使用输入x和输出y数据对full(整个)CVAE进行进一步的50个epoch的训练。给出最低验证损失的模型用于后续处理。
将CVAE性能与alternative(选择)SAE、SSAE和PCA DR技术进行了比较。根据我们之前的工作[15],SSAE和SAE设置有一个共同的结构(512、256、10、256、512)隐藏单元。这些参数是在我们对[15]的研究基础上选择的。
4.3 权重因子$\alpha $分析
由于更好地估计HB分量对ABE性能至关重要,因此潜在表示$z_x$应该包含$y$的信息,因此我们在训练和测试阶段研究了权重因子$\alpha $在reconstruction error(RE)$||y-f(z_y,z_x;\theta_y)||^2$重构误差上的重要性。
表1显示了不同的$\alpha $值在epoch结束时的$D_{KL}$和$RE$值,验证损失最小。$\alpha $值越低,$D_{KL}$值越大,说明approximate posteriorr(近似后验)$q_{\phi_y}(z_y|y)$与prior先验分布$p_{\theta_y}(z_y)=N(0,I)$相差甚远。这一假设是通过在测试过程中比训练过程中观察到更高的REs来证实的。这是因为解码器$p_{\theta_y}(y|z_x,z_y)$利用测试时从prior(先验)采样的潜在变量$z_y$重建输出$y$,而训练时从approximate(近似)的posterior(后验)采样$z_y$。$\alpha $值越大,$D_{KL}$值越低,说明poatweior distribution(后验分布)越接近prior distribution(先验分布)。通过对训练和测试阶段相似REs的观察,证实了这一假设。这些发现证实了之前的工作[20]。根据验证数据集的REs,本文其余部分报告的所有实验都对应于$\alpha =10$的值。
| $\alpha $ | 2 | 5 | 10 | 20 | 30 |
| $D_{KL}$训练phase(阶段) | 0.96 | 0.21 | 3.3e-4 | 1.5e-4 | 9.7e-5 |
| RE训练阶段 | 4.73 | 7.40 | 8.93 | 8.97 | 8.97 |
| RE测试阶段 | 11.40 | 9.85 | 8.93 | 8.97 | 8.97 |
图1 在训练和测试阶段,权重因素对DKL和RE的影响。验证数据集的结果显示
4.4 客观评价
客观频谱失真测量包括:均方根对数频谱失真(RMS-LSD)、所谓的COSH测度(symmetric version(对称版)的Ikatura-Saito失真)[34]计算的频率范围为3.4-8kHz,并将WB扩展到感知评价语音质量算法[35]。后者给出了平均意见得分的客观估计(MOS-LQOWB)。
结果见表2。PCA降维后的ABE性能优于SAE和VAE技术,说明了在特征提取过程中进行监督学习或所谓的discriminative fine tunig(判别微调)的重要性。MVN在降低PCA ABE系统性能的同时,显著提高了SAE和SSAE技术的性能。CVAE ABE系统是所有系统中性能最好的,有趣的是,无论有没有MVN,性能都是稳定的。这可能是由于潜在表示的概率学习。
| DR方法 | $d_{RMS-LSD(db)}$(db) | $d_{COSH(db)}$ | MOS-LQOWB |
| PCA PCA+MVN |
6.95 7.35 |
1.43 1.45 |
3.21 3.14 |
| SAE SAE+MVN |
12.45 7.54 |
2.96 1.50 |
1.95 3.03 |
| VAE VAE+MVN |
8.64 8.60 |
1.67 1.67 |
2.75 2.75 |
| SSAE SSAE+MVN |
10.50 6.80 |
2011 1.34 |
2.26 3.28 |
| CVAE CVAE+MVN |
6.59 6.69 |
1.31 1.30 |
3.34 3.31 |
表2 客观的评估结果。RMS-LSD和$d_{COSH}$是$dB$中的距离度量(数值越低表示性能越好),而MOS-LQOWB值反映质量(数值越大表示性能越好)
4.5 主观评价
表3以comparison mean-opinion score(比较平均意见评分,CMOS)的形式展示了比较主观听力测试的结果。测试由15名听众进行,他们被要求比较使用DT 770 PRO耳机收听的12对语音信号A和B的质量。他们被要求在-3(更差)到3(更好)的范围内对信号A相对于B的质量进行评级,评分步骤为1。所有用于主观测试的语音文件都在线提供2。
| 比较comparison A-->B | CMOS |
| CVAE-->NB CVAE-->PCA CVAE-->SSAE+MVN CVAE-->WB |
0.90 0.13 0.10 -0.96 |
表3 采用CVAE、SSAE + MVN和PCA DR技术对ABE系统的CMOS进行主观评价。
使用CVAE方法扩展带宽的语音文件质量优于原始NB信号(CMOS为0.90),但仍低于原始WB信号(CMOS为-0.96)。但是,CVAE系统的语音质量要优于CMOS分别为0.13和0.10的其他系统。
5 总结
条件变分自动编码器(CVAE)是用于生成模型的有向图形模型。本文首次将其应用于计算高效的人工带宽扩展(ABE)中的降维。当与标准的ABE回归模型一起使用时,使用该方法生成的概率潜在表示不需要任何后处理,如均值和方差归一化。本文所报道的ABE系统产生的语音质量显著提高,这一结果得到了客观评价和主观评价的证实。改进的原因是利用CVAE对高维谱系数进行了更好的建模。至关重要的是,它们是在不增加回归模型复杂性的情况下实现的。未来的工作应该将CVAEs与其他生成模型(如对抗性网络)进行比较或结合。
6 参考文献
[1] S. Li, S. Villette, P. Ramadas, and D. J. Sinder, “Speech bandwidth extension using generative adversarial networks,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5029–5033.
[2] K.-Y. Park and H. Kim, “Narrowband to wideband conversion of speech using GMM based transformation,” in Proc. of IEEE Int. Conf. on Acoustics, Speech, and Signal Processing(ICASSP), 2000, pp. 1843–1846.
[3] P. Jax and P. Vary, “On artificial bandwidth extension of telephone speech,” Signal Processing, vol. 83, no. 8, pp. 1707–1719, 2003.
[4] K. Li and C.-H. Lee, “A deep neural network approach to speech bandwidth expansion,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp.4395–4399.
[5] R. Peharz, G. Kapeller, P. Mowlaee, and F. Pernkopf, “Modeling speech with sum-product networks: Application to bandwidth extension,” in Proc. of IEEE Int. Conf. on Acoustics,Speech and Signal Processing, 2014, pp. 3699–3703.
[6] P. Bachhav, M. Todisco, M. Mossi, C. Beaugeant, and N.Evans, “Artificial bandwidth extension using the constant Qtransform,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5550–5554.
[7] I. Katsir, D. Malah, and I. Cohen, “Evaluation of a speech bandwidth extension algorithm based on vocal tract shape estimation,” in Proc. of Int. Workshop on Acoustic Signal Enhancement (IWAENC). VDE, 2012, pp. 1–4.
[8] Y. Gu, Z.-H. Ling, and L.-R. Dai, “Speech bandwidth extension using bottleneck features and deep recurrent neural networks.,” in Proc. of INTERSPEECH, 2016, pp. 297–301.
[9] Y. Wang, S. Zhao, J. Li, J. Kuang, and Q. Zhu, “Recurrent neural network for spectral mapping in speech bandwidth extension,” in Proc. of IEEE Global Conf. on Signal and Information Processing (GlobalSIP), 2016, pp. 242–246.
[10] B. Liu, J. Tao, Z.Wen, Y. Li, and D. Bukhari, “A novel method of artificial bandwidth extension using deep architecture,” in Sixteenth Annual Conf. of the Int. Speech Communication Association,2015.
[11] J. Abel, M. Strake, and T. Fingscheidt, “Artificial bandwidth extension using deep neural networks for spectral envelope estimation,” in Proc. of Int. Workshop on Acoustic Signal Enhancement (IWAENC). IEEE, 2016, pp. 1–5.
[12] A. Nour-Eldin and P. Kabal, “Objective analysis of the effect of memory inclusion on bandwidth extension of narrowband speech,” in Proc. of INTERSPEECH, 2007, pp. 2489–2492.
[13] A. Nour-Eldin, “Quantifying and exploiting speech memory for the improvement of narrowband speech bandwidth extension,” Ph.D. Thesis, McGill University, Canada, 2013.
[14] P. Bachhav, M. Todisco, and N. Evans, “Exploiting explicit memory inclusion for artificial bandwidth extension,” in Proc.of IEEE Int. Conf. on Acoustics, Speech and Signal Processing(ICASSP), 2018, pp. 5459–5463.
[15] P. Bachhav, M. Todisco, and N. Evans, “Artificial bandwidth extension with memory inclusion using semi-supervised stacked auto-encoders,” in Proc. of INTERSPEECH, 2018, pp.1185–1189.
[16] D. Kingma et al., “Semi-supervised learning with deep generative models,” in Advances in Neural Information Processing Systems, 2014, pp. 3581–3589.
[17] K. Sohn, H. Lee, and X. Yan, “Learning structured output representation using deep conditional generative models,” in Advances in Neural Information Processing Systems, 2015,pp.3483–3491.
[18] X. Yan, J. Yang, K. Sohn, and H. Lee, “Attribute2image: Conditional image generation from visual attributes,” in European Conference on Computer Vision. Springer, 2016, pp. 776–791.
[19] W.-N. Hsu, Y. Zhang, and J. Glass, “Learning latent representations for speech generation and transformation,” INTERSPEECH,2017.
[20] M. Blaauw and J. Bonada, “Modeling and transforming speech using variational autoencoders.,” in INTERSPEECH, 2016, pp.1770–1774.
[21] C.-C. Hsu et al., “Voice conversion from non-parallel corpora using variational auto-encoder,” in Signal and Information Processing Association Annual Summit and Conference (APSIPA),2016 Asia-Pacific. IEEE, 2016, pp. 1–6.
[22] K. Akuzawa, Y. Iwasawa, and Y. Matsuo, “Expressive speechsynthesis via modeling expressions with variational autoencoder,” INTERSPEECH, 2018.
[23] Y. Jung, Y. Kim, Y. Choi, and H. Kim, “Joint learning using denoising variational autoencoders for voice activity detection,”Proc. Interspeech 2018, pp. 1210–1214, 2018.
[24] S. Latif, R. Rana, J. Qadir, and J. Epps, “Variational autoencoders for learning latent representations of speech emotion,”INTERSPEECH, 2018.
[25] L. Pandey, A. Kumar, and V. Namboodiri, “Monoaural audio source separation using variational autoencoders,” Proc. Interspeech 2018, pp. 3489–3493, 2018.
[26] D. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
[27] C. Doersch, “Tutorial on variational autoencoders,” arXiv preprint arXiv:1606.05908, 2016.
[28] J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, and D. Pallett, “DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1,” NASA STI/Recon technical report N, vol. 93, 1993.
[29] P. Kabal, “TSP speech database,” McGill University, Database Version : 1.0, pp. 02–10, 2002.
[30] F. Chollet et al., “Keras,” https://github.com/keras-team/keras, 2015.
[31] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014.
[32] K. He et al., “Delving deep into rectifiers: Surpassing humanlevel performance on imagenet classification,” in Proc. of the IEEE int. conf. on computer vision, 2015, pp. 1026–1034.
[33] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Int. conf. on machine learning, 2015, pp. 448–456.
[34] R. Gray, A. Buzo, A. Gray, and Y. Matsuyama, “Distortion measures for speech processing,” IEEE Trans. on Acoustics,Speech, and Signal Processing, vol. 28, no. 4, pp. 367–376,1980.
[35] “ITU-T Recommendation P.862.2 : Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs,” ITU, 2005.