什么是VAE
VAE与GAN 都是做生成的model,用来构建一个从隐变量 Z 生成目标数据 X 的模型,其中是有差别的。
GAN与VAE都是在假设data服从某些常见的分布,比如正太分布,前提下去实现的,训练一个 X=g(Z)的model,GAN与VAE都是在进行分布之间的变换,将原来的概率分布映射到了训练集的概率分布。
因为我们只知道数据的真实样本,并不知道其data分布表达式,判断生成分布与真实分布的相似度对于Generator是非常困难的。
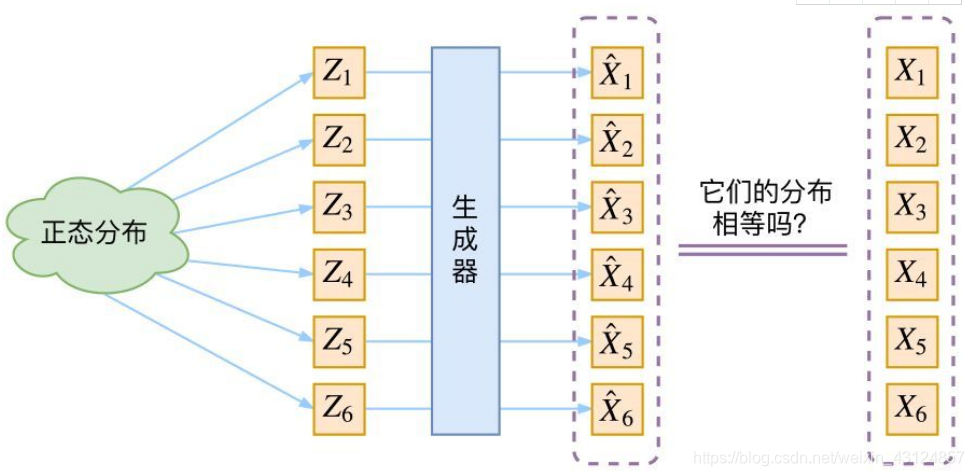
如果假设Pdata服从高斯分布,那么我就可以从中采样得到若干个 Z1,Z2,…,Zn,然后对它做变换得到 X̂1=g(Z1),X̂2=g(Z2),…,X̂n=g(Zn),我们怎么判断这个通过G_function构造出来的数据集,PG分布跟我们Pdata是不是一样的呢?现在我们拥有从Pdata 中sample的数据{X1,X2,…,Xn},还有我们通过generator从PG中生成的数据 {X̂1,X̂2,…,X̂n}。此时还不能直接用KL散度来描述两个概率分布之间的相似程度,因为我们并没有PG与Pdata的概率分布表达式。
既然没有合适的度量,如何解决此问题?GAN采用直接把这个度量也用神经网络训练出来。而 VAE 则使用了一个精致迂回的技巧。
**
VAE的实现
**
首先我们有一批数据样本 {X1,…,Xn},其整体用 X 来描述。我们想利用 {X1,…,Xn} 得到 X 的分布 p(X),如果可行就可以直接根据 p(X) 采样得到所有可能的 X 。

p(X|Z)表示由 Z 来生成 X 的模型的概率。假设 Z 服从标准正态分布p(Z)=N(0,I),那么我们就可以先从标准正态分布中采样一个 Z,然后根据 Z 来算X的分布。
模型实现框架的示意图如下:

以上框架图中我们不能看出,经过重新采样变量的 Zk是不是对应真实样本Xk,如果直接最小化 D(X̂ k,Xk)^2是不合理的。
在整个 VAE 模型中,我们并没有去使用 p(Z)(先验分布)是正态分布的假设,我们用的是假设 p(Z|X)(后验分布)是正态分布。给定一个真实样本 Xk,我们假设存在一个专属于 Xk 的分布 p(Z|Xk),并进一步假设这个分布是(独立的、多元的)正态分布。为什么要强调“专属”呢?因为后面要训练一个生成器 X=g(Z),希望能够把从分布 p(Z|Xk) 采样出来的一个 Zk 还原为 Xk。现在 p(Z|Xk) 专属于 Xk,从这个分布采样出来的 Z 能够要还原到 Xk 中去。这时候每一个 Xk 都配上了一个专属的正态分布 p(Z|Xk) 。但这样有多少个 X 就有多少个正态分布了。我们知道正态分布有两组参数:均值 μ 和方差 σ^2(多元的话,它们都是向量)。我们可以使用神经网络去拟合这些专属于 Xk 的正态分布 p(Z|Xk) 的均值和方差。
我们构建 μk=f1(Xk),logσ2=f2(Xk) 两个神经网络来算它们。之所以选择拟合 logσ2 而不是直接拟合 σ2,是因为 σ^2 ^^总是非负的,需要加激活函数处理,而拟合 logσ2不需要加激活函数,因为它可正可负。
我们能够获得专属于 Xk 的均值和方差,就可以得到其正态分布。然后从这个专属分布中采样一个 Zk 出来,经过一个生成器得到 X̂k=g(Zk)。就可以最小化 D(X̂k,Xk)^2,因为 Zk 是从专属 Xk 的p(Z|Xk) 分布中采样出来的,这个生成器应该要把开始的 Xk 还原回来。于是可以画出 VAE 的示意图:

VAE 就是为每个样本构造专属的正态分布p(Z|Xk),然后采样重构的。
本文参考: