前言
市面上有非常多VAE的讲解,我最近基本都看了一遍,感觉要不然需要太多的数理知识,要不然就是讲的太过浅显。现把自己的理解总结一遍,作为记录。
Auto-encoder(AE)
我们如何证明自己理解了一个事物?显然,判别这项事物并不够,例如我可以判断猫和狗,但我真的了解猫和狗嘛,我甚至都没养过狗。那么有一个思路就是,如果我能创造一只猫或一只狗,我才算真正的了解它。
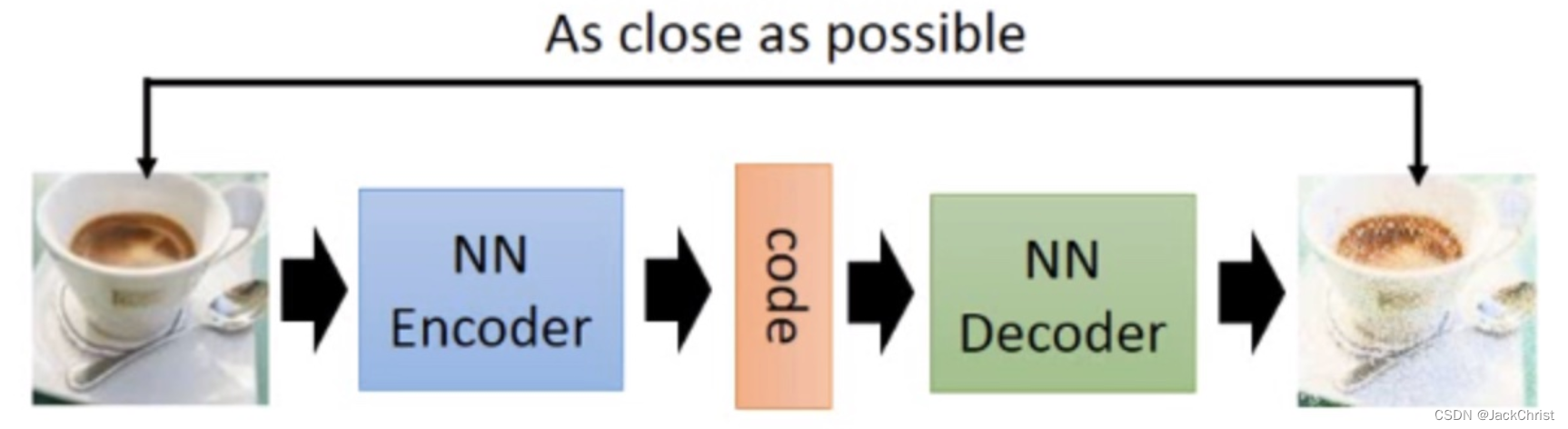
在神经网络中,同样如此。我们总是去提取一个信号的特征,然后去做下游任务,但这个特征是好是坏并不知道。如果我们能根据这个特征去把图像复原,是不是可以说明我这个"特征"可以完美地概括这个事物?我觉得是可以的,类似于PCA,是符合直觉的。这就是auto-encoder的思路。AE结构图如下所示,as close as possible是一个重建损失,用MSE就可以做到。
Variational Auto-encoder(VAE)
VAE是一个生成模型,其目的主要是去做一些有创造力的工作。例如生成一些本不存在的图像,这个任务在判别模型中是做不到的。在AE中也做不到,因为我们的code,准确来说是latent code,没办法去随机采样。例如一个训练好的网络,[1,1]可以生成茶杯了,那么我随机一个数字[9,9]它是茶杯吗,大概率不是。所以AE常有人去做预训练任务,也就是说把decoder拿走,认为encoder可以很好地提取输入图像的特征,所以通过encoder之后的code来进行下游任务的训练。这个效果还是不错的。
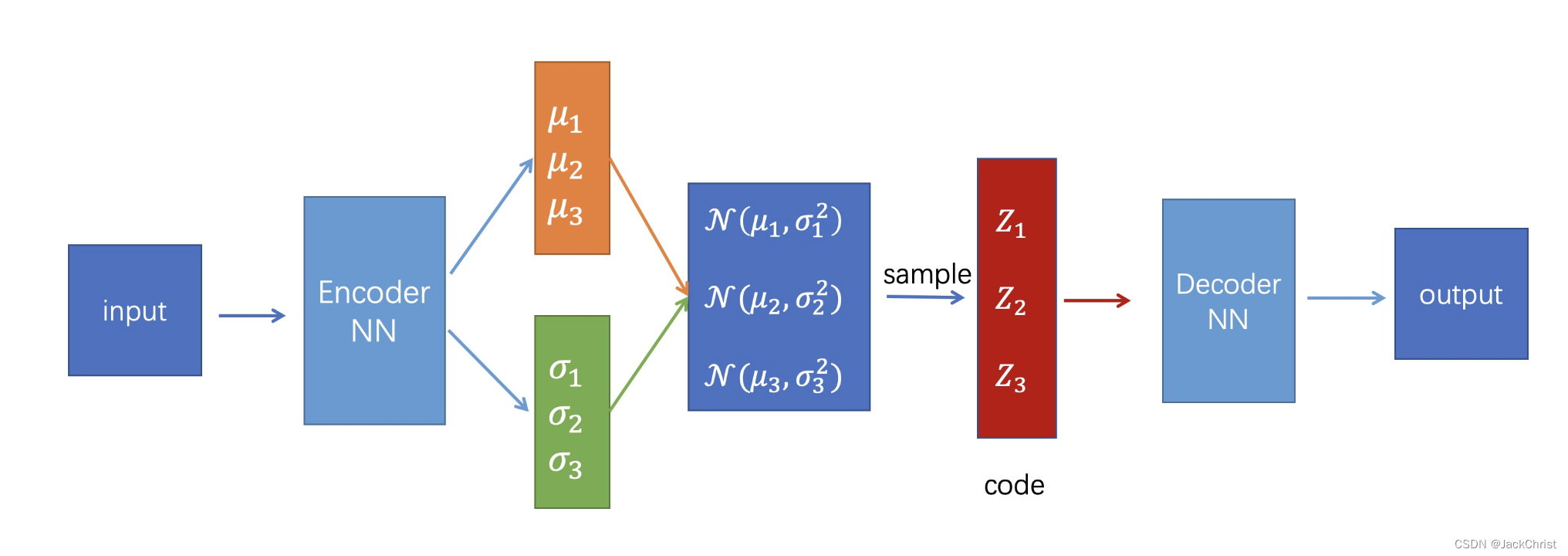
VAE可以去生成一些模拟的图像(信号),因为它加入了分布和采样的概念。如图所示,需要解释的是这里的input不只一张图像,有几张图像就有几个 μ \mu μ和 σ \sigma σ,也就是每一张图像生成一个高斯分布。然后从这些高斯分布中抽样得到隐变量 z z z。
loss function
AE的损失函数是重建损失,那么VAE的损失函数是什么,大家应该都知道是Elbo,Elbo的推导有非常多方法,我所知道的有三种方法,这一块是最复杂的。首先我们要定义任务的目标:使似然函数 P ( x ) P(x) P(x)越来越大。
问题一:为什么要使 P ( x ) P(x) P(x)越来越大?什么是 P ( x ) P(x) P(x)?
我的理解是 P P P是网络,我们希望这个网络可以产生与X相似的数据,那如果这个网络模拟出x背后的分布,那 P ( x ) P(x) P(x)必然很大。在任务中,由于我们是想产生x,那么自然是使 P ( x ) P(x) P(x)越来越大,如果我们是想给定一个特征x,去判断其属于的标签,则是使 P ( y ∣ x ) P(y \mid x) P(y∣x)越来越大。
问题二:为什么 P ( x ) P(x) P(x)是似然?
似然函数都有了解,是去判断什么样的参数可以产生这个数据,既然提到 P P P是网络,网络中是有参数的,那么 P P P实际上是 P θ P_\theta Pθ, P ( x ) P(x) P(x)实际上是 P θ ( x ) P_\theta(x) Pθ(x)或者 P ( x ∣ θ ) P(x \mid \theta) P(x∣θ)。实际上使用这三种表达方式的推导都有,这也是我看到时困惑我的一点。
综上 P ( x ) P(x) P(x)如果很大,说明我的网络越有可能生成类似于X的数据。如果令 P ( x ) P(x) P(x)很大,实际上就是在做极大似然估计。由于公式太多,直接手写推导一,也不知道有没有人看,就先写一种推导: )
这个推导把 m a x i m u m l o g P ( x ) maximum logP(x) maximumlogP(x)问题转化为 m a x i m u m E L B O maximum ELBO maximumELBO,然后再转化为 m i n i m u m D k l ( q ( z ∣ x ) ∥ P ( z ) ) minimum D_{kl}(q(z\mid x)\parallel P(z)) minimumDkl(q(z∣x)∥P(z)),如果我们能完成这个目标,则说明我们训练出了一个网络,这个网络可以生成与x最接近的数据。
意义
问题一:为什么要引入 q ( z ∣ x ) q(z \mid x) q(z∣x)?
因为我们没办法知道 P ( z ∣ x ) P(z \mid x) P(z∣x),用q无限接近P这就是变分推断的终极奥义。
问题二:为什么引入 q ( z ∣ x ) q(z \mid x) q(z∣x)我们就可以完成这个任务?
因为通过推导,我们可以使 q ( z ∣ x ) q(z \mid x) q(z∣x)和 P ( z ) P(z) P(z)无限接近,也就是 m i n i m u m D k l ( q ( z ∣ x ) ∥ P ( z ) ) minimum D_{kl}(q(z\mid x)\parallel P(z)) minimumDkl(q(z∣x)∥P(z))。而 P ( z ) P(z) P(z)是先验,先验是我们定义的,我们通常把它定义为 N ( 0 , I ) \mathcal{N}(0,I) N(0,I)。
q ( z ∣ x ) q(z\mid x) q(z∣x)也是符合正态分布的,因为我们使网络输出两个正态分布的参数。说白了现在就已经把问题转化为,把一个正态分布和一个标准正态分布拉近的问题。
第二项的期望表达的是重建损失,这一点还没有搞清楚是为什么,但代码里确实是如此。
重参数化技巧
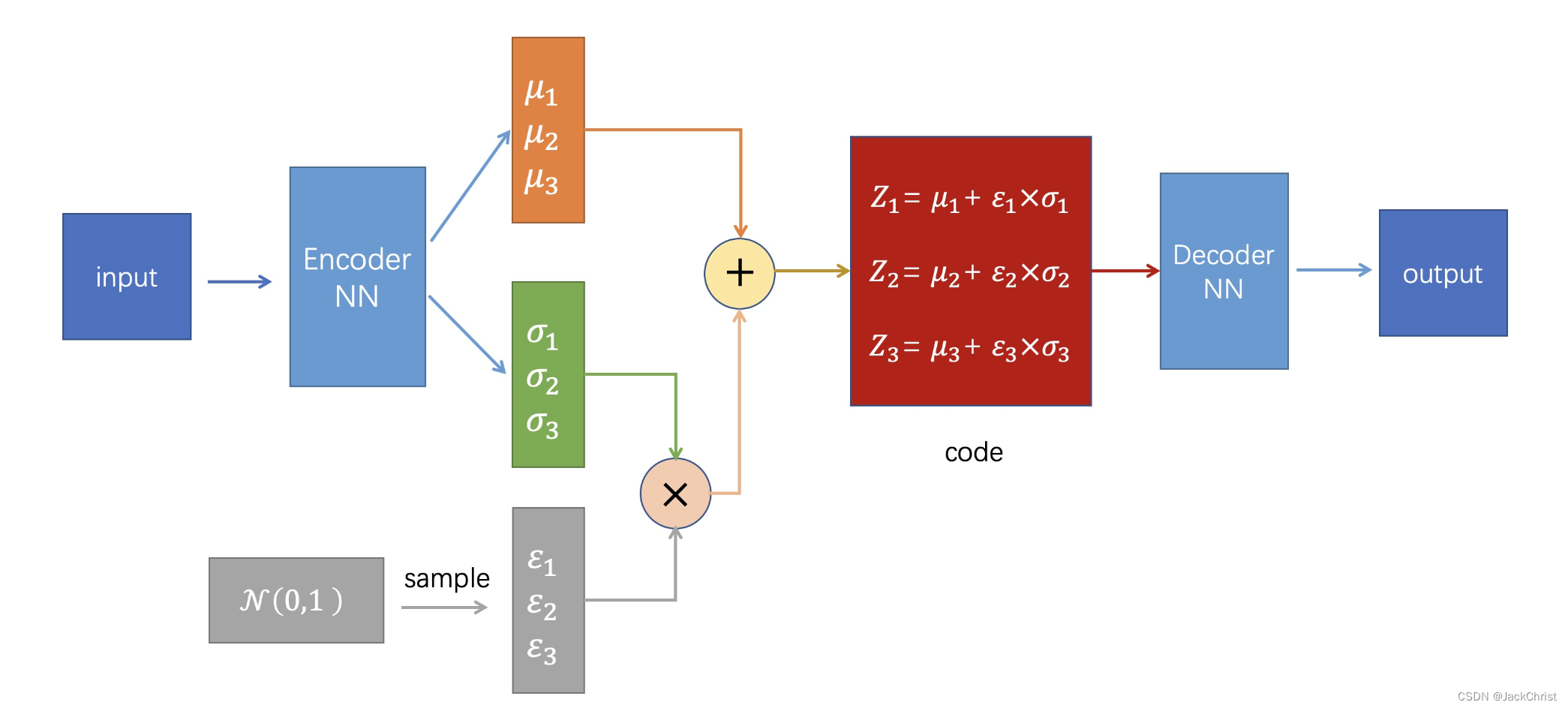
reparametrize是重参数化技巧,如果我们直接从一个正态分布中进行采样,那么这个采样过程是不可导的,但采样的结果是可导的。从 N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma ^2) N(μ,σ2)(是我们模拟出来的一个具体的分布)中采样 Z Z Z,相当于从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)中采样一个 ε \varepsilon ε,然后 Z = μ + ε × σ Z = \mu + \varepsilon \times \sigma Z=μ+ε×σ。此处也还没深入探究。
总体步骤
我们拥有一堆data,我们想根据这些data使得模型能产生更多类似的data。模型拥有encoder和decoder,在训练时encoder用来生成一堆高斯分布的参数,在此高斯分布中可以采样出z,把z输入到decoder中即可生成我们想要的data。通过推导可以发现,要想一个网络可以生成与x相似的数据,就相当于优化一个elbo,这样就可以使encoder生成的那个高斯分布与我们假定的先验分布越来越接近,更进一步也就是说使encoder生成的隐变量和数据本身的隐变量越来越接近。
代码
代码非常简单
class VAE(nn.Module):
"""Implementation of VAE(Variational Auto-Encoder)"""
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 200)
self.fc2_mu = nn.Linear(200, 10)
self.fc2_log_std = nn.Linear(200, 10)
self.fc3 = nn.Linear(10, 200)
self.fc4 = nn.Linear(200, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
mu = self.fc2_mu(h1)
log_std = self.fc2_log_std(h1)
return mu, log_std
def decode(self, z):
h3 = F.relu(self.fc3(z))
recon = torch.sigmoid(self.fc4(h3)) # use sigmoid because the input image's pixel is between 0-1
return recon
def reparametrize(self, mu, log_std):
std = torch.exp(log_std)
eps = torch.randn_like(std) # simple from standard normal distribution
z = mu + eps * std
return z
def forward(self, x):
mu, log_std = self.encode(x)
z = self.reparametrize(mu, log_std)
recon = self.decode(z)
return recon, mu, log_std
def loss_function(self, recon, x, mu, log_std) -> torch.Tensor:
recon_loss = F.mse_loss(recon, x, reduction="sum") # use "mean" may have a bad effect on gradients
#这里是值得说明的,此处将KL散度继续推导得到这个式子,详细推导很多地方都有,反正我没推,哈哈。
kl_loss = -0.5 * (1 + 2*log_std - mu.pow(2) - torch.exp(2*log_std))
kl_loss = torch.sum(kl_loss)
loss = recon_loss + kl_loss
return loss
值得注意的是,在最后生成时,我们直接从标准高斯分布中采样就行了,因为我们已经把encoder的输出,也就是decoder的输入Z与标准高斯拉近。
结果
这是我自己训练100epoch的结果,生成模型的结果很难定义好与不好,好不好得看下游任务是不是好,单看图片也就这个样子。至少有一些数字是可以以假乱真的。

总结
VAE通过使encoder生成分布的方法去做一些有创造力的工作,不过很多假设未免太强了,而且概率模型的优势也没有在VAE中体现出来,即轻松地加入先验知识。且使用VAE也不能控制输出的类型。