MPL-GAN:Toward Realistic Meteorological predictive learning Using Conditional GAN
作者:HONG-BIN LIU and ICKJAI LEE
College of Science and Engineering, James Cook University, Cairns, QLD 4870, Australia
下载地址.
Abstract
气象图像预报是气象预报中一个重要而具有挑战性的问题。这个问题可以看作是一个视频帧预测问题,即基于观测的气象图像预测未来帧。尽管这是一个被广泛研究的问题,但是它还远远没有被解决。目前最先进的基于深度学习的方法主要是优化MSELoss,这会导致预测模糊。这篇论文通过Meteorological predictive leanring GAN model (简称MPL-GAN)来解决这个问题,该模型利用条件GAN和预测学习模块来处理未来帧预测中的不确定性。在真实数据集上的实验证明了我们提出的模型的优越性能。我们提出的模型能够将传统的基于均方误差损失的预测学习方法产生的模糊预测映射回原始数据分布,从而能够改进和锐化预测。 具体来说,MPL-GAN实现了平均锐度提升52.82,比baseline好14%。此外,我们的模型正确地检测出了传统的无条件GANs无法做到的气象运动模式。
Introduction
1. 这个问题研究的必要性
天气预报是气象预报的主要应用之一,它对我们的日常生活以及工业农业生产都很重要。常用的包括:降水预测、经流预测、风速预测、辐射预测、温度预测等。已经有很多方法被提出来用于预测更加准确的天气测量(weather measurenent)。包括NWP、基于雷达图的方法和基于卫星图像的方法。
2. 采用DL的必要性
最近,随着深度学习技术的发展,研究人员采用基于递归神经网络(RNN)的方法来改进这些传统方法,以解决这一具有挑战性的问题。
- [1] ConvLSTM: 将降水临近预报问题转化为时空序列预报模型,并提出了基于lstm的雷达回波图预报模型ConvLSTM。
- [11] Seq2Seq-LSTM的模型[11],通过历史观测来提高NWP的性能。
- [12] GAN 研究提出了一个利用卫星图像预测气旋轨迹的对抗模型。
这些研究表明,雷达和卫星图像在气象预测中发挥着越来越重要的作用,这不仅是因为它们的鲁棒性更强,还因为它们为最终用户提供了从当前到预测的更多连续的信息,并且更好得进行了历史数据的可视化。
3. 现有方法的不足
然而,这些方法有一些共同的缺点:它们不能很好地概括现实世界的气象数据集,尤其是长期预测。更具体地说,这项开创性的工作ConvLSTM,产生模糊的雷达图像预测,并且随着时间的推移会变得越来越糟。这些气象图像看起来不真实,模糊导致视觉效果不佳。这些缺点主要是由于两个原因。首先,这些模型优化了欧氏损失,如贯穿序列气象图像总长度的平均绝对误差(MAE)和均方误差(MSE)。 一些研究为各种模型引入了MAE和MSE,但产生模糊图像[13],[14]。这主要是由于假设数据是由高斯分布绘制的,这种高斯分布只适用于图像的连续部分,而忽略了孤立的小区域。其次,由于RNN结构的本质,训练和推理[15]、[16]之间的差距会使小错误沿着生成的序列迅速累积成为大错误。 这两个原因表明,提出一个包括不确定性处理程序的模型来生成真实的气象预报是至关重要的。
4. 视频帧预测和时空序列预测问题的关联
同时,视频帧预测可以建模为一个时空序列预测问题。
- [17] Predrnn 从视频帧中提取图像序列,并提出了一种基于RNN的编解码模型及其改进版本PredRNN++[18]。
然而,这些模型都有着与convlsm产生模糊预测相同的缺点。
5. GAN对于解决这个问题的优势和不足
最近,生成对抗网络(Generative atterial Network,GAN)[19]被用来处理视频帧预测中的不确定性[13],[20]–[22]。GAN模型通过一个生成器和一个鉴别器通过博弈来匹配两个分布,生成器学习生成样本来愚弄鉴别器,鉴别器学习识别这些伪样本。这些基于GAN的无条件模型能够通过学习复杂数据集的高维分布来生成逼真的视频。然而,这些模型虽然能够产生逼真的、时间上一致的视频帧,但并不适用于气象预报学习。这是因为生成的视频帧不能模拟真实世界中由气象图像帧源给出的气象变化。注意,气象预报需要考虑移动实体(像素方向)的方向、速度、旋转加速度和其他信息。
6. 总结
综上所述,一方面,基于RNN的气象预报模型中的MAE和MSE会产生模糊的预报。另一方面,基于GAN的模型能够生成逼真的视频帧,但是无法捕捉到缺少局部变化和模式的实际大气运动。 在这项工作中,我们提出了一个基于条件GAN的气象预测学习GAN(简称MPL-GAN),它可以同时优化回归损失和GAN损失,并以生成真实的气象预报为目标。优化回归损失的目的是模拟真实世界的大气图像运动,这对天气预报至关重要。利用GAN损耗估计数据分布,处理不确定性,产生非模糊预测
主要贡献包括:
- 就我们所知,这是第一个将回归损失与GAN损失相结合的模型,以产生现实的气象预测,提供更好的可视化;
- 在真实世界的雷达图像数据集上进行广泛的实验。实验结果表明,我们的模型在捕捉真实世界大气变化的同时,即使在长期内也能产生不模糊的预测;
- 通过大量的实验分析表明,没有预测学习模块的纯GAN模型无法捕捉到实际的大气运动,这证明了我们提出的MPL-GAN模型对气象变化的检测是有效的。
Related work
1. 气象预测学习
基于最优流量的方法(optimal flow-based methods)[23],[24]在气象预测学习文献中已有很长的历史。随着深入学习的最新进展,作者[1]探索了应用RNN的可能性,并提出了一种称为卷积LSTM(ConvlTM)[1]的模型及其改进的版本的TrajGRU[2]用于雷达回波图像预测。两种方法都试图优化MSE损失。同时,视频帧预测和交通流预测可以看作是一个问题。PredRNN及其改进版本PredRNN++是为解决这一问题而提出的,这些方法同样优化了MSE损失,并且它们都有一个共同的问题:随着时间的推移,预测变得越来越模糊
除了气象图像预测学习外,基于神经网络的方法也被用于数值天气预报。例如,[11]提出了一个Seq2Seq LSTM来预测温度、风速和相对湿度。另一项研究[10]通过引入时间渐进增长计划抽样策略来改进这种方法。然而,这些方法同样遭受长期预测精度下降的影响。
2. GAN for 图像和视频生成
自2014年首次发布以来,GAN[19]一直是最受欢迎的生成模型。从那时起,GAN模型显示出了它们优越的能力,特别是在图像生成方面,从手写数字生成[19]、[25]到大规模图像集生成[26]、[27]。最近,研究人员试图通过使用无条件GAN生成照片逼真的视频[13]、[20]–[22]、[28]来突破GAN的限制。这些视频GANs的目标是生成真实感和时间一致的视频,并用于匹配两者之间的高维数据分布。请注意,这些模型没有考虑其他因素。也就是说,对于给定的初始帧,生成的帧不需要考虑运动实体的方向、速度和其他运动信息。然而,这些运动性质在我们的研究中起着重要的作用,我们的GAN不同于传统的无条件GANs,考虑了运动性质。
Proposed MPL-GAN
MPL-GAN模型,该模型旨在生成逼真的气象图像。下图显示了模型的总体架构,其中包含一个预测学习模型来生成预测,以及一个条件GAN模块,用于将这些预测映射回真实感分布。首先,我们将气象预报学习公式化为:
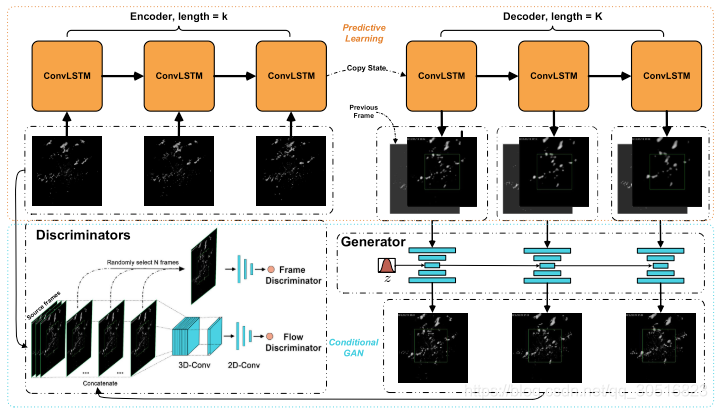
图片描述:橙色方框表示预测学习模型,用于模拟真实世界的气象运动模式。使用ConvLSTM学习模块,可以用其他预测性学习方法代替。蓝色是条件GAN。(生成器和鉴别器)
Definition: 给定长度k矩阵序列: , 其中每个矩阵 表示time-step t的气象图象。气象预测学习是为了根据过去 个帧取预测后 个time-step的气象图像。表示 。
注意: 气象图像携带重要的天气信息,如降雨、温度和风速等。
1. Predictive Learning
为了建模气象变化,我们采用了ConvLSTM[1]编码解码器作为预测学习模块。如[1]、[2]等前人的研究,预测学习的目的是捕捉局部时空模式的移动,如旋转和缩放。正如我们前面提到的,所有现有的基于gan的下一帧预测模型都不适合气象预测学习,因为这些模型不能捕捉现实世界的气象变化。此外,这些没有这种预测学习模块的GAN模型不能产生长期的预测。 例如,一项研究[13]最多只能产生两个帧来预测未来的视频。相比之下,我们的MPL-GAN模型根据先前的groud truth和条件GAN预测输出生成下一个预测。我们设法生成超过10帧的非模糊和真实的气象图像预测,在预测学习模块的帮助下建模真实世界的大气变化。 这表明,预测学习模块对于建模气象变化至关重要。值得注意的是,我们在本研究中使用ConvLSTM进行评估,但它可以被其他任何高级模型替代,如TrajGRU[2]和PredRNN++[18]。一方面,气象变化建模需要预测学习模块,另一方面,单纯的预测学习模型存在图像模糊的问题,需要对其进行专门的细化以进行气象变化分析。在下一节中,我们将引入条件型GAN来解决传统朴素预测学习模块造成的模糊问题。
2. Conditional GAN
GAN试图学习映射函数 将随机噪声向量 映射为图片 。 。本实验的目标是将ConvLSTM产生的模糊预测映射到原始的非模糊分布。让 表示ConvLSTM的时序输出, 表示观测值。我们的目标是训练一个CGNA使得 。
2.1. Conditional generator
由ConvLSTM递归的生成预测序列后,训练条件生成器, , 生成每帧图像。而不是训练整个序列的GAN的生成器,生成 表示ConvLSTM在 时刻的输出, 是 时刻的真实值。然而,当ConvLSTM预测在以后的时间步变得越来越模糊时,条件GAN更难映射两者之间的条件分布。
为了解决这个问题,我们对生成器进行了训练,并对前一帧 进行了条件设置。 即 。理想情况下,应该用当前时刻的真实帧 和当前的ConvLSTM预测帧 上训练条件生成器。我们使用前一帧而不是现在时刻的帧,因为通过观察两个连续的气象帧在数据分布上非常相似,因为大气通常是逐渐缓慢变化的。
此外,在推理阶段,前一帧和现在的真实帧都是不可用的。然而,我们可以在推断阶段用前一时刻的生成器输出替换前一时刻的真实帧 ,i.e. 。 是ConvLSTM的输出。
我们也可以换一种思路,因为在推理阶段,真实值不可用。但是我们假设生成器的输出分布与实际数据分布完全匹配,则可以将数据分布从最后一个已知的真实帧
数据分布就可以递归地从最后一个已知的真实帧转移到预测帧。因此,我们使用真实帧
而不是预测帧
。
2.2 Framse discriminator
从
个时间步中选出
帧图去训练帧鉴别器
.
对于真实值
输出1,fake值
输出0。然后通过优化初始GAN中定义的最小博弈来训练帧鉴别器,使用
。
2.3 Flow discriminator
帧鉴别器的目的是确保生成的样本与实际数据分布相匹配,即保证生成的样本看起来相似。在此基础上,类似于[22]提出的视频鉴别器,我们提出了一个flow鉴别器确保生成器产生的时间帧是时序相关的。相似的,当真序列 ,鉴别器 输出1,生成器输出 时,鉴别器输出0。我们将源序列 和条件生成序列 拼接。 的定义如下:
3. Training
此外,预测学习模块对于建模真实世界的气象运动模式是必不可少的,条件GAN用于将预测学习生成的模糊预测映射回非模糊图像分布。因此,我们将培训过程分为两个阶段。首先,我们开始训练预测学习模块,当预测学习模块的训练基本稳定后,我们开始训练GAN模块。
3.1 PREDICTIVE LEARNING TRAINING
根据ConvLSTM[1]和TrajGRU[17]的设置,我们通过随机梯度下降(SGD)和时间反向传播(BPTT)[30]最小化MSE和MAE损失(B- MSE -MAE)的平衡来训练我们的预测学习(PL)模块。我们训练(B- MSE -MAE)损失,直到它变得稳定,然后我们开始训练条件GAN,使条件GAN学习稳定的数据分布。然而,我们继续训练PL模块和GAN模块,即使损失没有减少。这背后的直觉是给出GAN的分布方差,使GAN变得更稳健。
3.2 CONDITIONAL GAN TRAINING
训练GAN模型需要通过优化极大极小博弈[19]来训练生成器和鉴别器,其中生成器学会用原始假样本欺骗鉴别器,鉴别器学会识别真样本和假样本。我们遵循同样的精神,并将其扩展到训练一个条件生成器和两个独立的鉴别器。帧鉴别器DFr和流鉴别器的损耗定义在方程1和方程2中。现在我们定义条件生成器的损失函数如下:
其中,
表示递归地使用生成器与ConvLSTM时间步长来生成帧序列流的过程。因此,我们的总体优化目标是最小化
和
,从而最大限度地提高鉴别器识别伪帧和伪序列的概率;并使
最小化,以最大限度地提高基因产生鉴别器认为是正确的样本的可能性。
注意,对于每个训练
b,随机选择N个随机帧来训练
次。训练
1次。而且,使用
训练G时,用
操作将G的梯度递归地反向传播多次。这使得训练GAN非常困难。我们根据[20]和[27]的原则,对通过
的序列的每一帧进行下采样,以克服训练的困难。
Experiment
1. Dataset
我们使用HKO-7[1]、[2]雷达回波图像数据集来评估我们提出的MPL-GAN模型。
雷达回波图像每6分钟记录一次,因此每天有240帧。每帧包含480×480像素,覆盖面积512km×512km。
我们通过滑动窗口将数据采样到长度为15帧的序列中,5帧用于编码器,10帧用于解码器。总数的993天的数据,我们随机选择80%的训练集,验证集,为5%和15%的测试集。
Baselines:
- ConvLSTM
- TrajGRU
我们关注现实的图像帧预测更好的可视化。
2. IMPLEMENTATION AND PARAMETERS
2.1 PREDICTIVE LEARNING
我们使用ConvLSTM作为预测学习模块。我们实现了一个三层ConvLSTM编解码器,每层使用以下参数:[3×3−64,3×3−192,3×3−192]。
2.2 CONDITIONAL GAN
训练GAN非常有挑战性。对于生成器,我们的结构类似于PG-GAN。为了匹配生成的样本的分辨率,我们将原始样本的分辨率从480×480提高到512×512。随机选取N = 2帧来训练帧鉴别器
。流鉴别器的3D-Conv由三个层组成,设置为以下参数:[3 × 3 × 3 − 64, 3 × 3 × 3 − 16, 3 × 3 × 3 − 1]。
实验设置:
pytorch 1.4,我们训练我们的模型与Adam optimiser[31]与学习率的1e−4 ConvLSTM和1e−3发生器和鉴别器。批处理大小设置为2是由于条件GAN模型的资源消耗。对于包括基线方法在内的所有模型,我们对100,000批次进行培训,并根据验证集的最小MSE选择最佳模型。对于MPL-GAN,在训练条件GAN之前,我们对PL模块进行10,000批次的培训。所有的实验结果都是在测试集的基础上报告的。
2.3 Overall Evaluation
Baselines
- PL(MSE)。为了证明带有MSE的PL产生模糊的预测,我们将我们的模型与没有条件GAN模块[1]的纯ConvLSTM进行了比较
- PG-GAN。我们将PG-GAN[27]从图像生成扩展到序列生成,其结构与我们的条件GAN module相同,即有一个帧鉴别器和一个流鉴别器。这也非常类似于DVD-GAN [22]
Evalutation Matrix
其中,
是真实帧,
是输出帧;
,
。
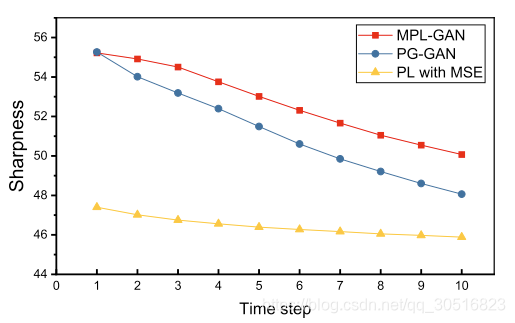
是图像强度的最大可能值。测试集在K帧之间的平均锐度,以及单个帧的评估作为折线图,如图所示:
EXPERIMENT ANALYSIS
我们使用两种基线方法进行定量和定性评估。如表1所示,我们提出的MPL-GAN的整体平均锐度为52.82;PG-GAN得到51.27的相似结果;而使用MSE的PL只能达到46.48。这表明,基于GAN的模型能够产生更准确的气象图像预测,相比PL和MSE。这是因为GAN模型处理了未来框架的不确定性。图2中的每帧全数值比较表明,基于GAN的模型不仅在平均得分上优于基于MSE的PL,而且在长期预测上也优于基于MSE的PL。MPL-GAN和PG-GAN在第一帧中得分相近,但是PG-GAN在长期内性能下降很快。
除了定量评估之外,我们还在图3中可视化了一个预测序列的示例(请使用Adobe Acrobat Reader单击该图形来查看动画)。如动画所示,PL与MSE和MPL-GAN捕获真实世界的气象运动模式。然而,PL与MSE产生模糊的预测,并继续随着时间变得越来越模糊,特别是在长期。然而我们提出的MPL-GAN继续产生真实的外观和锐利的预测。此外,如果我们着眼于小区域的预测框架,PL与MSE往往忽略小区域的结果MSE损失,而我们的模型有更多的区域细节与不确定性处理的GAN。
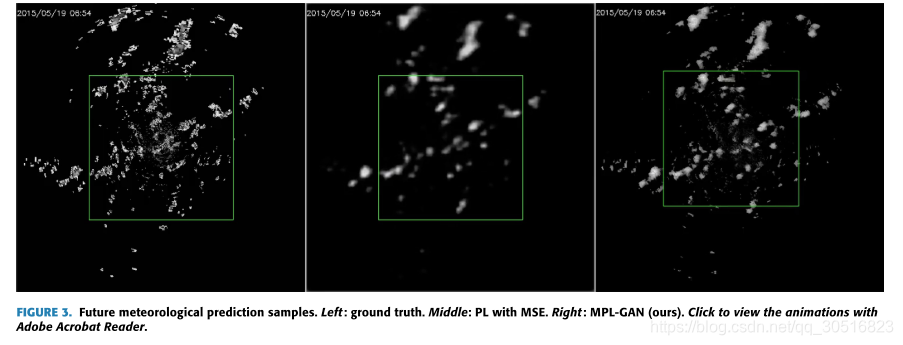
此外,整个实验的目的是为了了解GAN模型是否能够解决MSE下的PL导致的模糊预测问题。事实上,我们可以看到我们提出的模型是PL与MSE与PG-GAN的先进版本与两个鉴别头。如前所述,与使用MSE的PL相比,基于GAN的模型能够产生更准确的预测。然而,从图4的样本来看,PG-GAN不能模拟气象运动。更具体地说,PG-GAN生成的第一个框架看起来非常接近我们的模型MPL-GAN生成的第一个框架,但后面的框架只是对第一个框架的扩展,显然不是真实的场景。另一方面,在预测学习模块的约束下,我们提出的模型MPL-GAN能够生成逼真的和多样化的气象框架,捕捉真实的气象运动模式。我们在表2中总结了上面的调查结果。
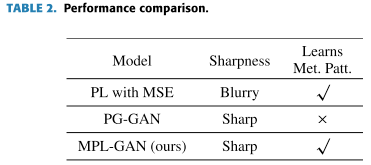
总之,气象图像预报的质量对天气预报和气候变化监测至关重要。图3清楚地描述了MPL-GAN产生的质量预测结果识别了全球趋势和局部变化,而MSE的PL过于模糊和粗糙,缺少局部变化和细节。与MSE一起的PL在实践中用处不大,因为它错过了许多局部模式,并导致不准确的预测,如何MPL-GAN在预报天气和监测局部和全球气候变化方面实际上是有用的,如图3和图4所示。

Conclusion
为了解决预测学习方法如ConvLSTM和TrajGRU中模糊预测问题,我们提出了MPL-GAN。我们利用条件GAN来处理这个问题,方法是将预测性学习方法生成的模糊预测映射回原始的非模糊数据分布。为了做到这一点,我们递归地对自身之前的输出和预测学习模块的当前输出应用一个条件生成器条件设置。通过新颖的帧鉴别器和流鉴别器的设计,产生器能够产生时序一致且真实的帧。在真实雷达回波数据集上的实验表明,我们提出的MPL-GAN模型不仅能产生清晰和逼真的气象预测,而且还能在预测学习模块的约束下模拟真实的气象运动模式。虽然我们的模型能够产生非模糊的预测,但预测精度仍有提高的空间。由于GAN模型带来的不确定性提高了预测的锐度,但降低了预测的准确性,我们未来的工作将研究这个问题,并利用各种真实数据集评估我们提出的模型。