文章目录
公式输入请参考: 在线Latex公式
Auto-encoder
上下两个东西如果单独拿出来是没有办法train的,因为对于encoder来说,我们有输入,但是输出的code是什么样子,我们是不知道的。
对于encoder来说,输出的code通常维度要小于输入的维度,用于Compact representation of the input object。
对于decoder而言,他的主要作用是reconstruct the original object

所以把encoder和decoder联在一起,就可以训练了,这个时候的输入和输出都有了。
先复习一下之前的PCA
Starting from PCA
输入是一个图片,转换为向量
(之前将PCA这里的
是要减去均值
的,这里省略这个步骤,因为输入NN的时候,通常起手式就是先做normalization,做完
,所以就不用再减去均值
了),输入乘上权重
(相当于通过NN的一个layer)得到一个component,用
来表示,
再乘上
得到
,这个
相当于根据
做reconstruction得到的结果。
在PCA中,我们的目标是
,也就是
和
越接近越好。

从encoder的角度来看,
相当于输入层,
相当于输出层,中间的
相当于隐藏层(当然PCA算法中,c是线性的),由于上节说过
用来Compact representation of the input object。所以维度要小,因此又叫做:Bottleneck layer
是encoder
是decoder
意思就是PCA也可以看做Auto-encoder的一种简单形式,那么如果Auto-encoder推广到Deep Auto-encoder呢?
Deep Auto-encoder
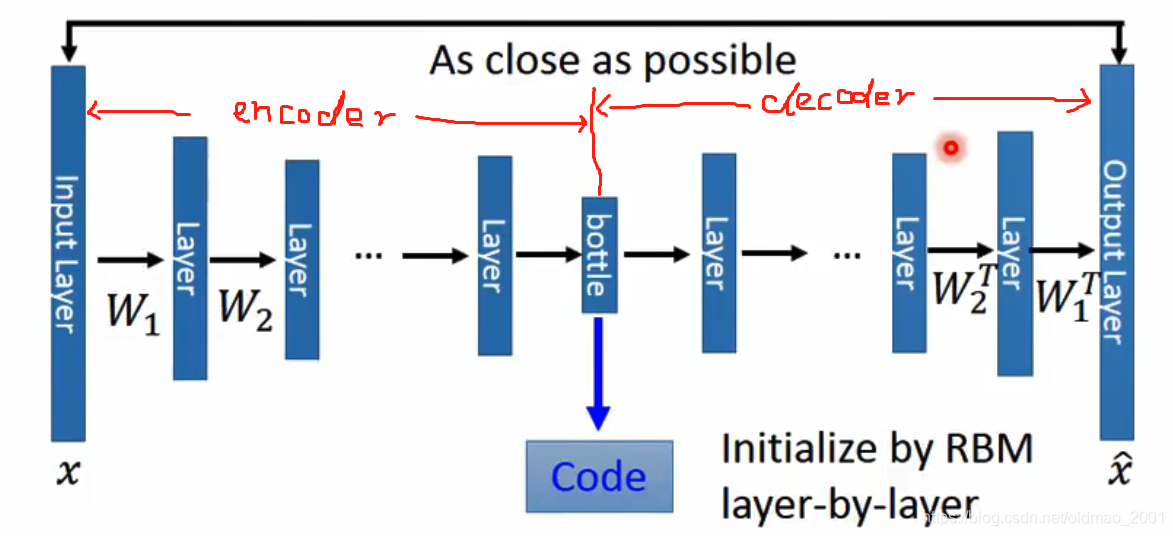
Reference: Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks."Science 313.5786(2006):504-507
需要注意几点:
1、当时这个方法不好训练,需要逐层使用RBM来初始化;
2、根据PCA的经验,可以看到左右两边的权重是有对应的转置关系的。实际上可以忽略这种转置关系,直接使用反向传播来更新参数。
下面看一下从Hinton大佬的文章里面的一些截图:

可以看到Deep Auto-encoder的结果吊打比PCA。
PCA的做法:

Deep Auto-encoder的做法:

如果用PCA降到2维
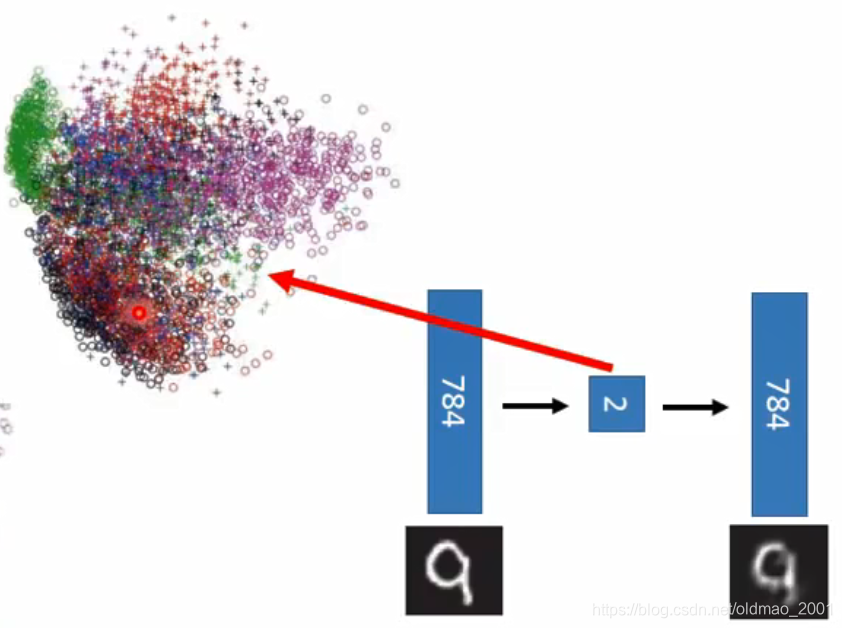
可以看到不同颜色代表的不同数字都混在一起了
如果是Deep Auto-encoder,数字就是分开的。

Pokemon
老师二次元能力爆发,分别用两种方式对宝可梦的数据做了可视化。。。。
http://140.112.21.35:2880/~tlkagk/pokemon/pca.html
http://140.112.21.35:2880/~tlkagk/pokemon/auto.html
The code is modified from
.http://jkunst.com/r/pokemon-visualize-em-all/


点开网页可以看到更加NB的效果。
下面看Auto-encoder在其他领域的应用
Auto-encoder-Text Retrieval
文本检索,本质上就是找到与文本最相近的向量:
Vector Space Model

这种做法,如何用向量来表示document非常重要,最简单做法就是Bag-of-word:
每个词用one-hot向量表示,那么句子就是下面这个样子(有的时候还会乘上一些权重以表示词的重要程度):

这个模型的弱点也明显,就是没有考虑词与词之间的语义信息。Semantics are not considered.
但是如果用上Auto-encoder,那么语义信息就很自然的被包含进来了。The documents talking about the same thing will have close code.

Hinton做出的结果

如果用LSA

Auto-encoder-Similar Image Search
可以用在以图找图应用上
Reference: Krizhevsky, Alex, and Geoffrey E. Hinton."Using very deep autoencoders for content-based image retrieval."ESANN.2011
如果用像素为单位来进行比较(Retrieved using Euclidean distance in pixel intensity space)得到的效果是不好的。例如下面用MJ的图片进行搜索,得到的结果。。。那个马蹄是来搞笑的吗。。。

可以用Auto-encoder对N张图片进行encoder,然后再对code进行查询。

然后decoder进行reconstruction的结果:

再回到MJ的问题用256维的code来检索,结果如下:

Pre-training DNN
接下来看看如何对Auto-encoder进行初始化,用的是Pre-training DNN,具体做法如下:
假设我们要对MINST使用Auto-encoder进行识别,使用的模型如下图:

输入是784维,第一个隐藏层(蓝色)是1000维,第二个隐藏层(绿色)是1000维,第三个隐藏层(深蓝)500维,输出code是10维。
Pre-training第一步:目标是初始化第一个隐藏层的参数。
构造如下模型:
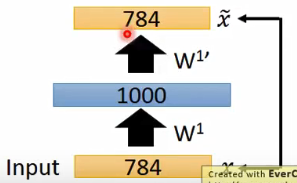
根据之前的经验知道,这里的目标是使得输入x和输出
(也就是code)越接近越好。
需要注意的是,在之前的Auto-encoder模型中,code比输入一般来说是要小的,这里的是一样的维度,因此在训练的时候很容易啥都没学到(直接把输入搬到输出呗),这个时候需要强制的加上L1的弄。强制的使得参数变得稀疏。
训练结束后,得到了
第二步,把
固定住,构造如下模型

这个时候就是训练第二层,最后把得到的
保存下来。(注意,这里的
应该是等于
的)
同样,训练第三层,得到

最后的
用随机初始化就可以了,最后再用反向传播进行fine-tune

划重点:
Pre-training这个方法现在之前训练比较深的网络时比较有用,现在不用这个方法也可以进行训练了。但是当我们有大量的unlabel data,少量的label data,这个时候可以用unlabel data Pre-training模型,然后再用label data进行fine-tune
De-noising auto-encoder
Auto-encoder的另外一个改进方法就是De-noising:
Vincent, Pascal, et al."Extracting and composing robust features with denoising autoencoders."ICML,2008.

这个模型的鲁棒性比较好,因为在学习样本的code的过程中,顺便把噪声的样子也学习到了,因此噪声对这个模型的影响也就小了。
另外一个类似的改进模型是Contractive auto-encoder
Ref: Rifai, Salah, et al."Contractive auto-encoders: Explicit invariance during feature extraction."Proceedings of the 28th International Conference on Machine Learning(ICML-11).2011.
还有两个其他的,不是NN的模型,就不写了
接下来看用CNN来做Auto-encoder
Auto-encoder for CNN
模型框架如下:

右边部分都应该没有问题,左边部分咋整的?
CNN-Unpooling
通常的做法如下图:

注意中间黑白色的部分,要记录下来最大值所在的位置,最后unpooling的时候要把最大值放到记录的位置,其他位置补零。效果如下图:

当然还有比较偷懒的做法,直接不记录位置,最后unpooling的时候所有的位置都填充最大值。
CNN-Deconvolution
这里老师的观点比较6,认为:Actually, deconvolution is convolution.看例子。
下面是一个一维卷积的例子,不同颜色代表不同权重。

要对这个卷积过程进行反卷积,实际上就是:
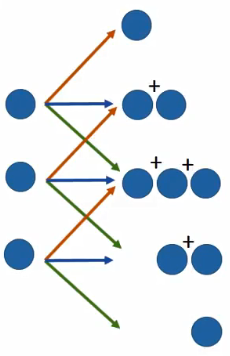
这个过程很容易理解,但是实作起来麻烦,上面实际上是等价于把输入进行padding后卷积:
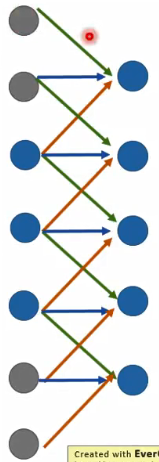
这里注意观察权重对应的颜色,计算结果是完全一样的。所以反卷积实际上可以看做是padding后的卷积操作,这样就不需要额外编制代码,而是直接调用卷积的函数即可。
